详解JVM运行原理及Stack和Heap的实现过程

概述
因为线上系统遇到CPU100%的问题,这种问题在流量较大时比较常见,因为JDK自身有很多JVM调试工具,如jps、jstack、jmap、jhat、jstat等使用工具,在实际工作中使用这些工具进行调试是十分必要的,一般通过上面工具就能定位并解决CPU100%的问题。
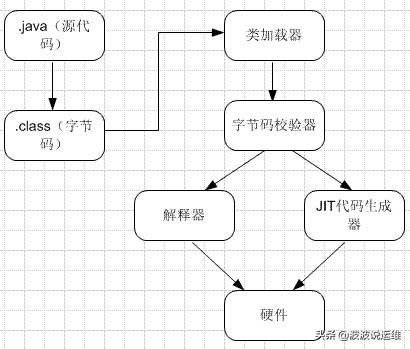
实际上Java语言写的源程序是通过Java编译器,编译成与平台无关的‘字节码程序’(.class文件,也就是0,1二进制程序),然后在OS之上的Java解释器中解释执行,而JVM是java的核心和基础,在java编译器和os平台之间的虚拟处理器。所以理解JVM运行原理是很有必要的。
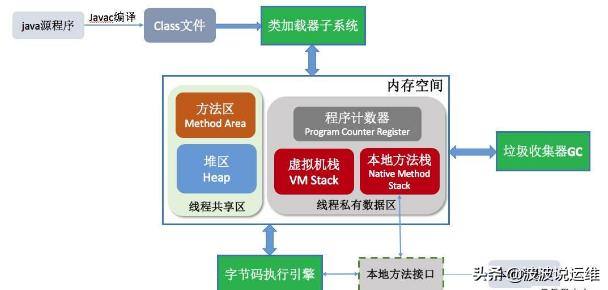
JVM原理
1. JVM简介
JVM是java的核心和基础,在java编译器和os平台之间的虚拟处理器。它是一种利用软件方法实现的抽象的计算机基于下层的操作系统和硬件平台,可以在上面执行java的字节码程序。
java编译器只要面向JVM,生成JVM能理解的代码或字节码文件。Java源文件经编译成字节码程序,通过JVM将每一条指令翻译成不同平台机器码,通过特定平台运行。
2. Java语言运行的过程
Java语言写的源程序通过Java编译器,编译成与平台无关的‘字节码程序’(.class文件,也就是0,1二进制程序),然后在OS之上的Java解释器中解释执行。

3. JVM执行程序的过程
- I. 加载class文件。
- II. 管理并分配内存。
- III. 执行垃圾收集。
JRE(java运行时环境)由JVM构造的java程序的运行环境
JVM中的Stack和Heap
在JVM中,内存分为两个部分,Stack(栈)和Heap(堆),这里,我们从JVM的内存管理原理的角度来认识Stack和Heap,并通过这些原理认清Java中静态方法和静态属性的问题。
1. 简介
Stack(栈)是JVM的内存指令区。Stack管理很简单,push一定长度字节的数据或者指令,Stack指针压栈相应的字节位移;pop一定字节长度数据或者指令,Stack指针弹栈。Stack的速度很快,管理很简单,并且每次操作的数据或者指令字节长度是已知的。所以Java基本数据类型,Java指令代码,常量都保存在Stack中。
Heap(堆)是JVM的内存数据区。Heap的管理很复杂,每次分配不定长的内存空间,专门用来保存对象的实例。在Heap中分配一定的内存来保存对象实例,实际上也只是保存对象实例的属性值,属性的类型和对象本身的类型标记等,并不保存对象的方法(方法是指令,保存在Stack中),在Heap中分配一定的内存保存对象实例和对象的序列化比较类似。而对象实例在Heap中分配好以后,需要在Stack中保存一个4字节的Heap内存地址,用来定位该对象实例在Heap中的位置,便于找到该对象实例。
下图为JVM的体系结构:
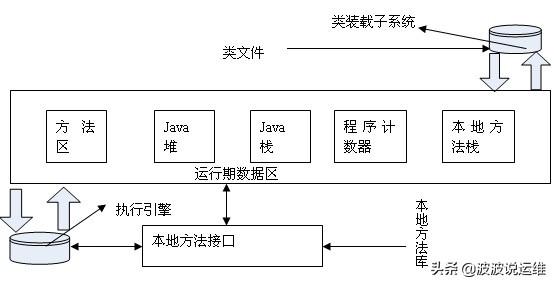
2. 什么是数据、什么是指令,对象的方法和对象的属性又是什么?
1)方法本身是指令的操作码部分,保存在Stack中;
2)方法内部变量作为指令的操作数部分,跟在指令的操作码之后,保存在Stack中(实际上是简单类型保存在Stack中,对象类型在Stack中保存地址,在Heap 中保存值);上述的指令操作码和指令操作数构成了完整的Java指令。
3)对象实例包括其属性值作为数据,保存在数据区Heap中。
非静态的对象属性作为对象实例的一部分保存在Heap中,而对象实例必须通过Stack中保存的地址指针才能访问到。因此能否访问到对象实例以及它的非静态属性值完全取决于能否获得对象实例在Stack中的地址指针。
在JVM中,静态属性保存在Stack指令内存区,动态属性保存在Heap数据内存区。
总结:
1)栈是运行时的单位,而堆是存储的单位。
2)栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
4. 为什么要把堆和栈区分出来呢?
第一,从软件设计的角度看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。
第二,堆与栈的分离,使得堆中的内容可以被多个栈共享(也可以理解为多个线程访问同一个对象)。这种共享的收益是很多的。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间。
第三,栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力。而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分,使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可。
第四,面向对象就是堆和栈的完美结合。其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。但是,面向对象的引入,使得对待问题的思考方式发生了改变,而更接近于自然方式的思考。当我们把对象拆开,你会发现,对象的属性其实就是数据,存放在堆中;而对象的行为(方法),就是运行逻辑,放在栈中。我们在编写对象的时候,其实即编写了数据结构,也编写的处理数据的逻辑。
程序要运行总是有一个起点的。同C语言一样,java中的Main就是那个起点。无论什么java程序,找到main就找到了程序执行的入口
5. 堆中存什么?栈中存什么?
1)堆中存的是对象。栈中存的是基本数据类型和堆中对象的引用。一个对象的大小是不可估计的,或者说是可以动态变化的,但是在栈中,一个对象只对应了一个4btye的引用。
2)为什么不把基本类型放堆中呢?因为其占用的空间一般是1~8个字节——需要空间比较少,而且因为是基本类型,所以不会出现动态增长的情况——长度固定,因此栈中存储就够了,如果把他存在堆中是没有什么意义的(还会浪费空间,后面说明)。可以这么说,基本类型和对象的引用都是存放在栈中,而且都是几个字节的一个数,因此在程序运行时,他们的处理方式是统一的。但是基本类型、对象引用和对象本身就有所区别了,因为一个是栈中的数据一个是堆中的数据。最常见的一个问题就是,Java中参数传递时的问题。
3)Java中的参数传递时传值呢?还是传引用?程序运行永远都是在栈中进行的,因而参数传递时,只存在传递基本类型和对象引用的问题。不会直接传对象本身。
Java在方法调用传递参数时,因为没有指针,所以它都是进行传值调用
PS:堆和栈中,栈是程序运行最根本的东西。程序运行可以没有堆,但是不能没有栈。而堆是为栈进行数据存储服务,说白了堆就是一块共享的内存。不过,正是因为堆和栈的分离的思想,才使得Java的垃圾回收成为可能。
深入理解JVM原理对于我们平时调试问题还是很有帮助的,运维不仅仅是学一些Linux命令就可以的,如果要往深方面研究的话很多时候开发的东西要需要会一点的。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

