面试官们“爱不释手”的分布式系统架构到底是个什么鬼?
本文是公众号读者W同学的投稿
感谢W同学的技术分享
目录:
一、什么是分布式系统?
二、为什么要走分布式系统架构?
三、系统如何进行拆分?
四、分布式之后带来的技术挑战?
一、什么是分布式系统?
在谈分布式系统架构前,我们先来看看,什么是分布式系统?
假设原来我们有一个系统,代码量30多万行。现在拆分成20个小系统,每个小系统1万多行代码。
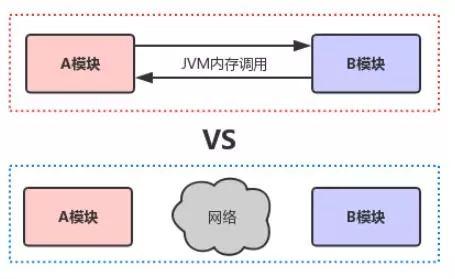
原本代码之间都是直接基于Spring框架走JVM内存调用,现在拆开来,将20个小系统部署在不同的机器上,然后基于分布式服务框架(比如dubbo)搞一个rpc调用,接口与接口之间通过网络通信来进行请求和响应。
所以分布式系统很重要的特点就是服务间要跨网络进行调用,我们来看下面的图:
此外,分布式系统可以大概可以分成两类。
1. 底层的分布式系统。
比如hadoop hdfs(分布式存储系统)、spark(分布式计算系统)、storm(分布式流式计算系统)、elasticsearch(分布式搜索系统)、kafka(分布式发布订阅消息系统)等。
2. 分布式业务系统
分布式业务系统,把原来用java开发的一个大块系统,给拆分成多个子系统,多个子系统之间互相调用,形成一个大系统的整体。
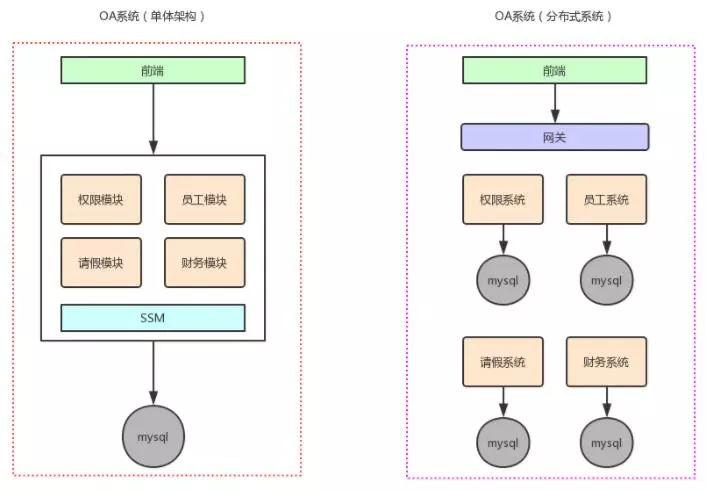
举个例子,假设原来你做了一个OA系统,里面包含了权限模块、员工模块、请假模块、财务模块,一个工程,里面包含了一堆模块,模块与模块之间会互相去调用,1台机器部署。
现在如果你把他这个系统给拆开,权限系统,员工系统,请假系统,财务系统,4个系统,4个工程,分别在4台机器上部署。
然后一个请求过来,完成这个请求,员工系统去调用权限系统,调用请假系统,调用财务系统,4个系统分别完成了一部分的事情。
最后4个系统都干完了以后,才认为是这个请求已经完成了。这就是所谓的分布式业务系统。
同样,我们来一张图,感受一下上述过程:
二、为什么要走分布式系统架构?
有的同学可能要问了,我一台服务器跑的好好的,所有系统一个工程全部搞定,多好。为啥一定要去搞什么分布式系统架构,互相调用还要走远程,似乎还增加了不少工作量?
这里我就以我曾经待过的一个公司的血泪经历为例,来聊聊这个问题。
很多年前,在没有走分布式架构的时候,我待的这家公司的各个业务线都是垂直的 “ 烟囱式 ” 项目。
随着互联网的快速发展,公司的业务也在不断的发展,注册用户增加、网站应用的功能、规模不断扩大,特别是移动互联网的发展,APP、微信、自助终端机等访问渠道的增加,各种新业务,新需求不断涌入,系统遇到了各种各样的问题。
首先是项目工程无节制的变得臃肿庞大,系统复杂度增加,大几十万行代码,几十个开发人员,service层,dao层代码大量被copy使用,经常各种代码合并冲突问题要处理,非常耗费时间。
经常是我改动了我的代码,别人调用了我的接口,导致他的代码也出现问题,需要重新测试,麻烦的要死。
然后每次发布都是几十万行代码的系统一起发布,大家得一起提心吊胆准备上线,几十万行代码的上线,每次上线都要做很多的检查,很多异常问题的处理,每个人都高度紧张,被搞得几乎崩溃。
而且如果我现在有个新业务,打算把相关依赖升级一下,比如升级到最新的spring版本,还不行,因为这可能导致别人的代码报错,不敢随意乱改技术。并且一个web工程每次启动都需要好分钟的时间,本地IDE里面调试一次代码都很痛苦。
其次,随着用户访问流量的增加,系统负载压力变大,变得不堪重负,通过增加实例数,增加硬件扩容能够带来的效果已微乎其微,故障频发,效率低下。系统质量也越来越难以保证,测试周期也变得越来越长,无法满足公司业务发展的需要。
以上就是以前待过的公司一些 “不堪回首” 的往事,总得来说,问题主要体现在以下几个方面:
-
应用代码耦合严重,功能扩展难
-
新需求开发交互周期长,测试工作量大
-
新加入的开发同事需要很长时间才能熟悉系统
-
升级维护也很困难(改动任何一点地方都要升级整个系统)
-
系统性能提升艰难,可用性低,不稳定。
好,既然我们已经深刻体会到了系统耦合的痛苦,那么现在就来看看,系统拆分后带来的好处:
首先,系统拆分了以后,会感觉整个世界都清爽了。
几十万行代码的系统,假设拆分成20个服务,平均每个服务就1-3万行代码,每个服务部署到单独的机器上。20个工程,就用20个git仓库代码,20个开发人员,每个人维护自己的那个服务就可以了。
-
因为是自己独立的代码,跟别人没关系。再也没有代码冲突了,爽!
-
每次就测试我自己的代码就可以了,爽!
-
每次就发布我自己的一个小服务就可以了,爽!
-
技术上想怎么升级就怎么升级,保持接口定义不变,输入输出内容不变就可以了,爽!
总结起来一句话,分布式系统拆分之后,可以大幅度提升复杂系统大型团队的开发效率。
三、系统如何进行拆分?
一般来说,将系统进行拆分,首先需要对系统整体比较熟悉。可以走多轮拆分的思路,第一次拆分就是将以前的各个大的模块粗粒度的拆分开来。
比如一个电商系统可以拆分成订单系统、商品系统、店铺系统、会员系统、促销系统、支付系统等等。
后面可能每个系统又变得越来越复杂了,比如说订单系统又可以进一步拆分出来购物车系统,库存系统,价格系统等。
总得来说就是基于领域驱动设计的思想以及实战经验总结,同时参考业界一些常规做法,大家讨论着来进行拆分,逐步优化,多轮拆分,小步快跑,最终达到一个比较好的状态。
四、分布式之后带来的技术挑战?
首先就是分布式服务框架的选用,目前国内来讲主流的还是dubbo与spring cloud。
我们来思考一下,使用服务框架主要用来解决什么问题呢?如果不用dubbo或者spring cloud是否可以做分布式架构呢?
不用dubbo或者spring cloud等服务框架当然也是可以的,但是这就需要自己处理很多事情了。
比如,各个子系统走restful接口调用,那么就是http调用,这时比如传送过去一个对象,就要自己搞成一个json,然后一次调用失败后重试怎么做?
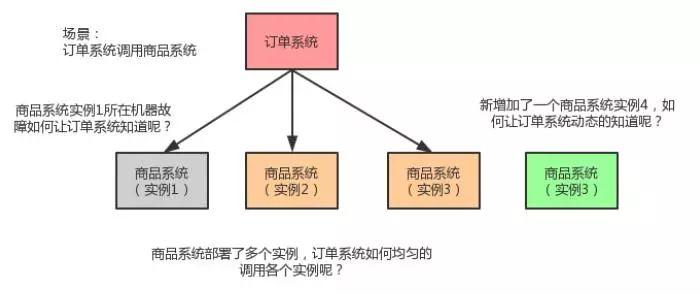
另外,一般来说都是集群部署,目标系统有多个实例,那么自己还要写一个负载均衡算法,如何每次随机从多个目标机器中挑选一个来调用?
还有,如果目标系统扩容新部署了一个实例,或者服务器故障下线了一个实例,如何动态让调用方感知到呢? 诸如此类的很多问题,如果不用服务框架的话,自己这么瞎搞,会遇到各种各样的问题。
上述过程,用一张图给大家呈现一下:
如果选用了某一个分布式服务框架,就需要深入的掌握这个框架的使用与底层原理,比如 dubbo 就需要搞明白以下的一些问题:
-
dubbo的工作原理?
-
dubbo支持的序列化协议?
-
dubbo的负载均衡和高可用策略?动态代理策略?
-
dubbo的SPI思想?
-
如何基于dubbo进行服务治理、服务降级、失败重试以及超时重试?
-
dubbo服务接口的幂等性如何设计(比如不能重复扣款,不能重复生成订单,不能重复创建卡号)?
-
dubbo服务接口请求的顺序性如何保证?
-
如何自己设计一个类似dubbo的rpc框架?
使用spring cloud也是一样,比如eureka的工作原理?feign声明式调用的原理?等等各种底层原理要搞懂。
还有其它一些走分布式架构后常见的要解决的技术问题:
-
分布式会话
-
分布式锁
-
分布式事务
-
分布式搜索
-
分布式缓存
-
分布式消息队列
-
统一配置中心
-
分布式存储,数据库分库分表
-
限流、熔断、降级等。
以上这些问题,往深了说,每一个点都需要可能 N 篇文章来详细阐述,这里没法逐一展开,后面我们会继续通过一些文章,聊一聊这些分布式架构下的各种技术问题。
END
个人公众号:石杉的架构笔记(ID:shishan100)
欢迎长按下图关注公众号: 石杉的架构笔记!
公众号后台回复 资料 ,获取作者独家秘制学习资料
石杉的架构笔记,BAT架构经验倾囊相授
正文到此结束
- 本文标签: 测试 数据库 UI App 开发 支付系统 Elasticsearch 限流 协议 系统架构 时间 REST 文章 高可用 缓存 服务器 负载均衡 配置 需求 Eureka http 分布式 JVM web js HDFS 代码 经验总结 src 幂等性 配置中心 java https 集群 RESTful 分布式事务 dubbo id Feign spring git 网站 IDE 消息队列 工作原理 Spring cloud 目录 质量 互联网 数据 json 总结 ORM 分布式锁 部署 Hadoop 压力 调试 实例 锁 Service 分布式系统 幂等
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

