学好kafka,轻松做架构
去年的时候,我有几个月在给一家超级独角兽企业做顾问,跟他们其中一个核心团队的负责人沟通比较多,他们团队很年轻,技术经验不能说很充分,但发展速度太快了,几个年轻人两三年前写的东西,已经可以一年贡献几个亿的利润,从商业上来说非常成功,但技术欠债也在所难免,规模访问时系统单点隐患可以说相当的多,当时团队扩招了不少人才,整个架构也在重构,负责人就给我讲他们的整个架构升级的方案,并征询我的意见。
然后我发现我有点懵圈了,很惭愧,对方谈及的架构完全是基于kafka,而我对这玩意居然没有概念!!
回来后赶紧补课,网上搜索了一下,先是大吃一惊,这玩意解决的问题,不就是当年我做架构的时候,焦头烂额搞的七晕八素的问题么!为什么当年我不知道有这个神器!仔细再看才恍然大悟,kafka是2011年底linkedin开源,2012年底由apache孵化器单独孵化这个项目,这之后慢慢的才引起业内的重视,在业内被广泛应用,应该是2014年以后的事情了。而我,真惭愧,2011年底的时候,基本上就不碰一线技术了,2013年则远渡南洋,更是连技术顾问都不做了,所以几年下来,业内技术工具的重大变化,居然一概不知。
坦白说,如果当年我在4399做架构的时候,要是有这么个玩意,我随便拍脑袋说一下,我平时关于架构升级的工作,大概50%可以省下来。而线上故障的出现频率,大约可以减少70%以上。睡眠时间可以增加。。。这条就算了。
为什么说kafka这个东西这么重要,在集群里,统一信息流管理太有意义了。当并发规模增加时,我们当时遇到的最大的负载问题是数据库,而数据库优化不是万能的,需要做集群处理,但这里引申了很多问题,中间件调配问题,以及集群中的信息一致性问题,此外,为了解决数据库写入压力,同步写入转为异步写入也是很重要的一环。以上,都需要信息流的工具。此外,前端缓存的读取和快速更新,也需要一些信息流工具协助,纯粹的共享内存固然有其价值一面,但太多存在约束的问题了,限于篇幅就不展开说了。
当时我们采用了一些第三方的中间件产品和共享内存产品来解决这些问题,然后中间出现了太多问题,一些第三方中间件产品属于个人产品,缺乏维护,出现问题也无法及时解决,我水平也有限,最窘迫的时候紧急从杭州刷脸请来一个高手到厦门,帮助我们处理一些第三方缓存队列工具的bug问题。
那有人可能觉得,用好共享内存不就够了,为什么还要用消息队列?我当时真的做过测试,高并发的情况下,对共享内存的快速读写,其实很容易造成写入顺序的错误,导致漏写或错写。有个简单测试,有兴趣的读者可以试试,我读取memcache的数据,加1操作,然后写回去,用apache的ab做模拟并发压测,执行1万次,猜猜结果是多少,理论上应该加1万吧,其实只加了6000多,现在机器性能和以前不一样,不知道再跑一次会是多少。仔细想想数据是怎么丢掉的?所以高并发写入一定要用消息队列,这是血淋淋教训得到的结论。
那看到这个kafka的介绍如此强悍,我赶紧发消息给坚守在4399的小伙伴们,希望他们尽快学习掌握,结果童鞋们云淡风轻的回了一句,早都用上了。哦,好吧,原来只有我一个人落伍了。
那么,今天 Kafka 已经广泛应用于国内外大厂,比如 BAT、字节跳动、美团、 Netflix、Airbnb、Twitter、Cloudflare 等等 。这不是偶然的,从我短暂的架构经验来看,这个工具解决的问题,恰恰都是架构设计和实际应用场景中最容易出坑,也最让人焦头烂额的地方。 架构设计的目标是什么,可靠性,可扩展性,和成本可控性。有希望从事架构师职业的童鞋,务必记住这几个核心目标。
防范单点隐患,系统资源灵活扩展,运维成本与业务规模的增长关系低于等比线。这三个原则,我建议研发人员也能理解一下,如果你希望自己职场的路更宽阔,更长远。那么kafka,你不能说,完美的解决这三个问题,但你会发现,应用到位的话,对解决这三个问题来说,可以省力很多。
去年我给那家超级独角兽在顾问的时候,参与他们技术分享会,发现他们高薪招聘来的优秀研发人才,几乎每个人对kafka都很熟悉,这已经成为业内很重要的通用技能。就算不是架构师,做好研发工作,可能也需要这方面的知识,才能更好的理解架构诉求和自己的研发目标。
所以,我建议身边从事研发和运维的年轻人,可以将 Kafka 加入到自己的学习列表。的确, 我们 仅需要学习一套框架,就能在实际业务系统中实现消息队列应用、应用程序集成、分布式存储构建,甚至是流处理应用的开发与部署 , 可谓相当超值了。
不过,想要学透 Kafka 没有想象中的那么简单,学习路径和方法尤为重要。我的建议是: 千万不要直接扎到具体的细节中,亦或是从一个很小的点开始学习。 因为你无法建立全局的认知观,从而实现系统地学习。还记得我以前强调过的学习观么, 用思想驾驭工具,而不是用工具奴役思想!
要从应用场景,实际问题出发,理解架构目标和思想,理解工具在这一目标中的作用和地位,然后基于实际诉求驾驭它,才是真正的掌握了工具,如果你只是熟练的操作,而缺乏整体观,那反而被工具奴役了。
在我看来,针对不同的角色,Kafka 的学习路径是不一样的。
-
如果你是 软件开发工程师 ,可以先根据编程语言寻找对应的 Kafka 客户端,然后去官网上学习代码示例,正确编译和运行这些样例。接下来,你可以尝试修改样例代码并使用其他的 API,之后观测你修改的结果。如果这些都没有难倒你,你可以自己编写一个小型项目来验证下学习成果,然后就是改善和提升客户端的可靠性和性能了。到了这一步,就熟读一遍 Kafka 文档吧,确保你理解了那些可能影响可靠性和性能的参数。最后是学习 Kafka 的高级功能,比如流处理应用开发。
-
如果你是 系统管理员或运维工程师 ,那么学习目标应该是如何根据实际业务需求评估、搭建生产Kafka 线上环境。对生产环境的监控也是重中之重的工作,Kafka 提供了超多的 JMX 监控指标,你可以选择任意你熟知的框架进行监控。有了监控数据,作为系统运维管理员的你,势必要观测真实业务负载下的 Kafka 集群表现。之后利用已有的监控指标来找出系统瓶颈,然后提升整个系统的吞吐量,这是最能体现你工作价值的地方。
说到这里,送大家一张 Kafka 学习框架,出自 Kafka 资深专家 胡夕 之手 。 我想你应该听过他的书《Apache Kafka实战》,豆瓣评分 8.8 分。胡夕根据他的实战经验,把 Kafka 学习框架整理成了下图。具体地,分为 Kafka 入门、Kafka 的基本使用、客户端详解、Kafka 原理介绍、Kafka 运维与监控以及高级 Kafka 应用。
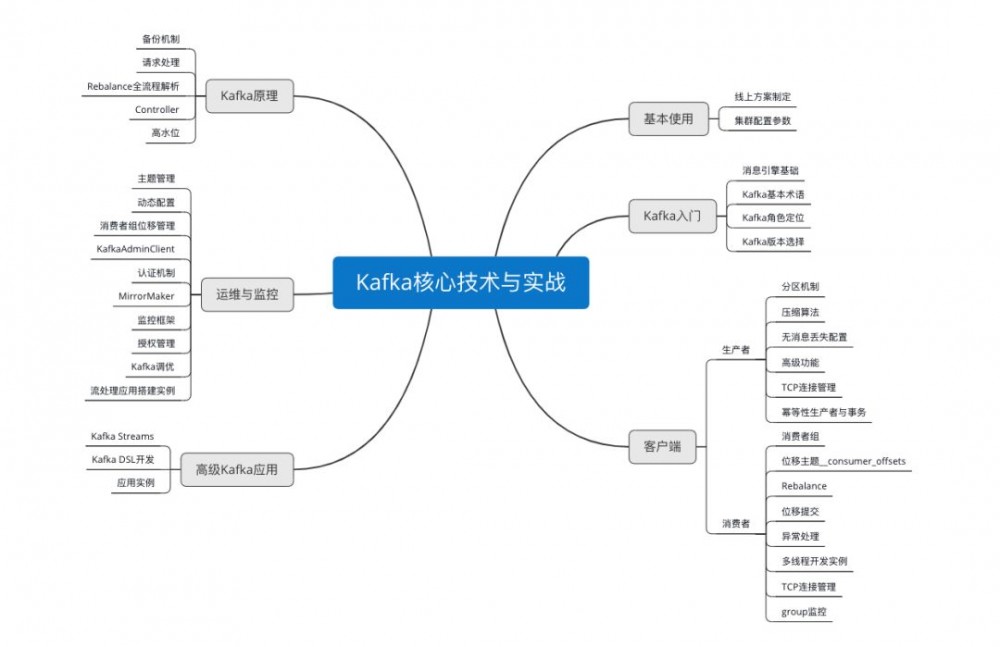
Kafka 学习框架
这些内容,胡夕都会在他在极客时间新上线的 《Kafka 核心技术与实战》 专栏里为你一一讲解,跟着他对 Apache Kafka 的理解和实战方面的经验,相信你一定能透彻理解 Kafka、更好地应用 Kafka。

胡夕是谁?
胡夕,现任人人贷公司计算平台部总监,也是 Apache Kafka 的一名活跃代码贡献者。
在过去 5 年中,他经历了 Kafka 从最初的 0.8 版本逐步演进到 2.3 版本的完整过程,可以说对 Kafka 及其他开源流处理框架与技术有深刻理解。他主导过多个十亿级/天的消息引擎业务系统的设计与搭建,具有丰富的线上环境定位和诊断调优经验,也曾给多家大型公司提供企业级 Kafka 培训。
他的书《Apache Kafka实战》,读者好评如潮,说内容实战,看完上手即用,在工作中帮大家解决了问题。

你可能会问, 《Kafka 核心技术与实战》专栏与书的区别又是什么呢?
其实区别还是挺大的,书是基于 Kafka 1.0 版本撰写的,但目前 Kafka 已经演进到 2.3 版本了,书中的部分内容已经过时甚至是不准确了,而《Kafka核心技术与实战》专栏的写作是 基于 Kafka 的最新版 。
要于是俱进啊,不要跟我一样落伍啊!
另外,《Kafka核心技术与实战》专栏作为一次全新的交付,胡夕希望能用 更轻松更容易理解的语言和形式 ,帮你获取到最新的 Kafka 实战经验。
你将获得?
-
专栏的第一部分会介绍消息引擎这类系统大致的原理和用途,以及作为优秀消息引擎代表的 Kafka 在这方面的表现。
-
第二部分则重点探讨 Kafka 如何用于生产环境,特别是线上环境方案的制定。
-
在第三部分中会陪你一起学习Kafka客户端的方方面面,既有生产者的实操讲解也有消费者的原理剖析,你一定不要错过。
-
第四部分会着重介绍 Kafka 最核心的设计原理,包括 Controller 的设计机制、请求处理全流程解析等。
-
第五部分则涵盖 Kafka 运维与监控的内容,助你获得高效运维 Kafka 集群以及有效监控Kafka的实战经验。
-
最后一个部分会简单介绍一下 Kafka 流处理组件 Kafka Streams 的实战应用,希望能让你认识一个不太一样的 Kafka。

限时订阅福利
1. 上新优惠 ¥68 (原价 ¥99 ), 最后 2 天 倒计时,6月15日恢复原价。
2.分享海报,邀请好友订阅即可获得 ¥24 返现 ,多邀多得,上不封顶。
3. 凭订阅截图,可领取「 学习礼包 」,包括 111 本实战指南,仅限 500 人。 获取方式:点「阅读原文」
 识别我的海报,立即试读或订阅课程
识别我的海报,立即试读或订阅课程

点「 阅读原文 」,领取「 学习礼包 」
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

