Kubernetes容器集群DevOps
| 编辑推荐: |
| 本文来自于云社区,本文主要分享平安证券在容器云时代的一些CI/CD(持续集成/交付)的积累和经验。 |
平安证券成立于1991年,在近30年的时间内,积累了很多不同的IT应用,公司上下一直在紧跟IT前沿应用,践行科技赋能。
本次分享分为以下几个大部份内容:
1,生产环境的高可用master部署方案。
2,分层的docker镜像管理
3,Dashboard,Prometheus,grafana的安全实践
4,一个能生成所有软件包的jenkins job
5,计算资源在线配置及应用持续部署
一,生产环境的高可用master部署方案
K8s的高可用master部署,现在网络上成熟的方案不少。大多数是基于haproxy和Keepalived实现vip的自动漂移部署。至于haproxy和Keepalived,可独立出来,也可寄生于k8s master节点。
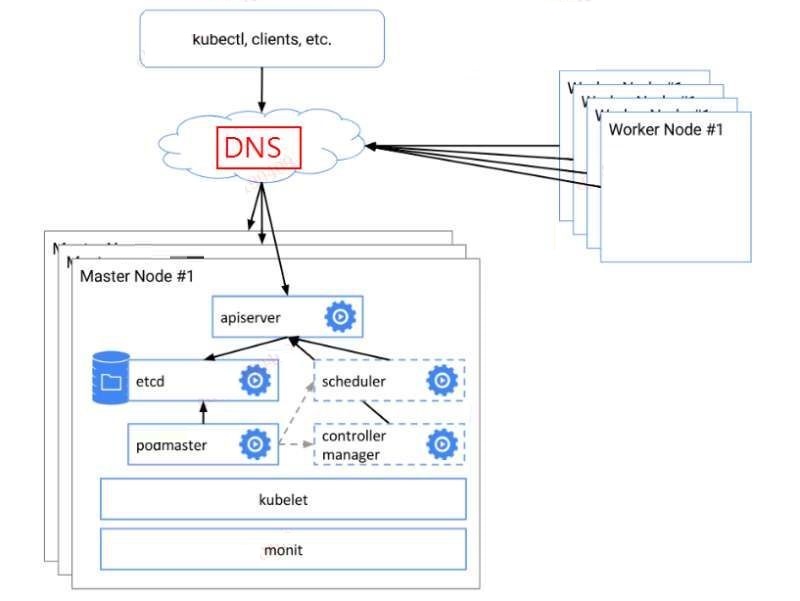
我司在IT设备的管理上有固定的流程,VIP这种ip地址不在标准交付范围之内。于是,我们设计了基于DNS解析的高可用方案。这种方案,是基于load balancer变形而来。图示如下:
dns负载
这种构架方案,平衡了公司的组织结构和技术实现。
如果真发生master挂掉,系统应用不受影响,DNS的解析切换可在十分钟内指向新的master IP,评估在可接受范围之内。(10分钟呀)
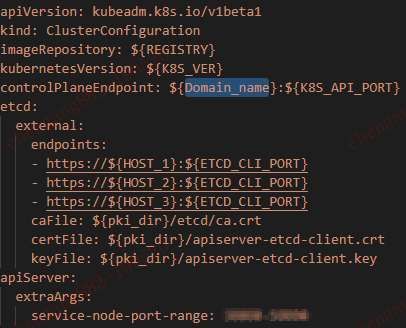
公司内部安装master节点时,使用了基本工具是Kubeadm,但是作了脚本化改造及替换成了自己的证书生成机制。经过这样的改进之后,使用kubeadm进行集群安装时,就更有条理性,步骤更清晰,更易于在公司进行推广。
底层的Etcd集群使用独立的docker方式部署,但共享kubeadm相关目录下的证书文件,方便了api-server和etcd的认证通信。脚本的相关配置如下:
etcd知识补充开始
Zookeeper是一个用户维护配置信息、命名、分布式同步以及分组服务的集中式服务框架,它使用Java语言编写,通过Zab协议来保证节点的一致性。因为Zookeeper是一个CP型系统,所以当网络分区问题发生时,系统就不能注册或查找服务。
etcd是一个用于共享配置和服务发现的高可用的键值存储系统,使用Go语言编写,通过Raft来保证一致性,有基于HTTP+JSON的API接口。etcd也是一个强一致性系统,但是etcd似乎支持从non-leaders中读取数据以提高可用性;另外,写操作仍然需要leader的支持,所以在网络分区时,写操作仍可能失败。
在原生接口和提供服务方式方面,etcd更适合作为集群配置服务器,用来存储集群中的大量数据。方便的REST接口也可以让集群中的任意一个节点在使用Key/Value服务时获取方便。ZooKeeper则更加的适合于提供分布式协调服务,他在实现分布式锁模型方面较etcd要简单的多。所以在实际使用中应该根据自身使用情况来选择相应的服务。
etcd知识补充结束
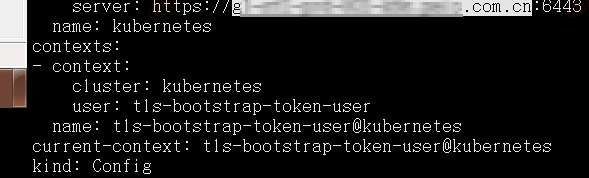
当以dns域名的形式进行部署后,各个证书配置认证文件,就不会再以IP形式连接,而是以dns域名形式连接api-server了。
如下图所示:
二, 分层的docker镜像管理
接下来,我们分享一下对docker镜像的管理。
Docker的企业仓库,选用的是业界流行的harbor仓库。
根据公司研发语言及框架的广泛性,
采用了三层镜像管理,
分为公共镜像,业务基础镜像,业务镜像(tag为部署发布单),层层叠加而成,即形成标准,又照顾了一定的灵活性。
公共镜像:一般以alpine基础镜像,加上时区调整,简单工具。
业务基础镜像:在公共镜像之上,加入jdk,tomcat,node,python等中间件环境。
业务镜像:在业务基础镜像之上,再加入业务软件包。
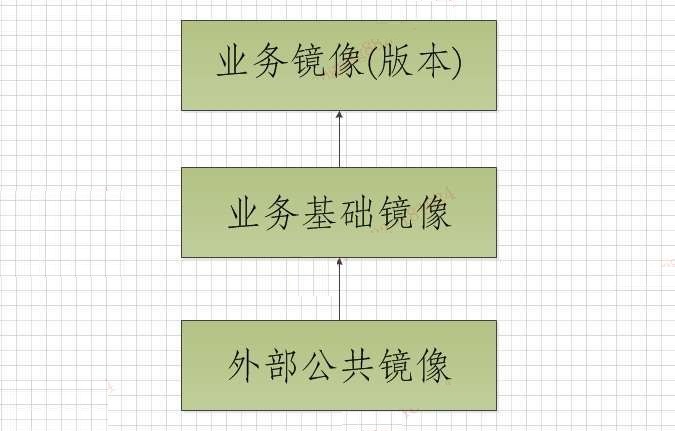
三层镜像管理
三, Dashboard,Prometheus,grafana的安全实践
尽管在k8s本身技术栈之外,我司存在体系化的日志收集,指标监控及报警平台,为了运维工具的丰富,我们还是在k8s内集成了常用的dashboard,Prometheus,grafana组件,实现一些即时性运维操作。
这些组件部署,我们都纳入一个统一的nginx一级url下,二级url才是各个组件的管理地址。这样的设计,主要是为了给dashborad及prometheus增加一层安全性(grafana自带登陆验证)。
这时,可能有人有疑问,dashboard,kubectl都是可以通过cert证书及rbac机制来实现安全性的,那为什么要自己来引入nginx作安全控制呢?
在我们的实践过程中,cert证书及rbac方式,结合ssh登陆帐号,会形成一系列复杂操作,且推广难度高,我们早期实现了这种模式,但目前公司并不具备应用条件,所以废弃了。公司的k8s集群,有专门团队负责运维,我们就针对团队设计了这个安全方案
Prometheus的二级目录挂载参数如下:
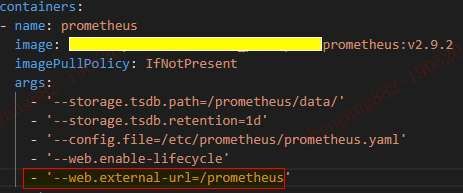
Grafana的二级目录挂载参数如下:
Dashboard在nginx里的配置如下:
四, 一个能生成所有软件包的jenkins job
在CI流水线实践,我们选用的gitlab作为源代码管理组件,jenkins作为编译组件。但为了能实现更高效标准的部署交付,公司内部实现一个项目名为prism(棱镜)的自动编译分发部署平台。在容器化时代,衍生出一个prism4k项目,专门针对k8s环境作CI/CD流程。Prism4k版的构架图如下所示:
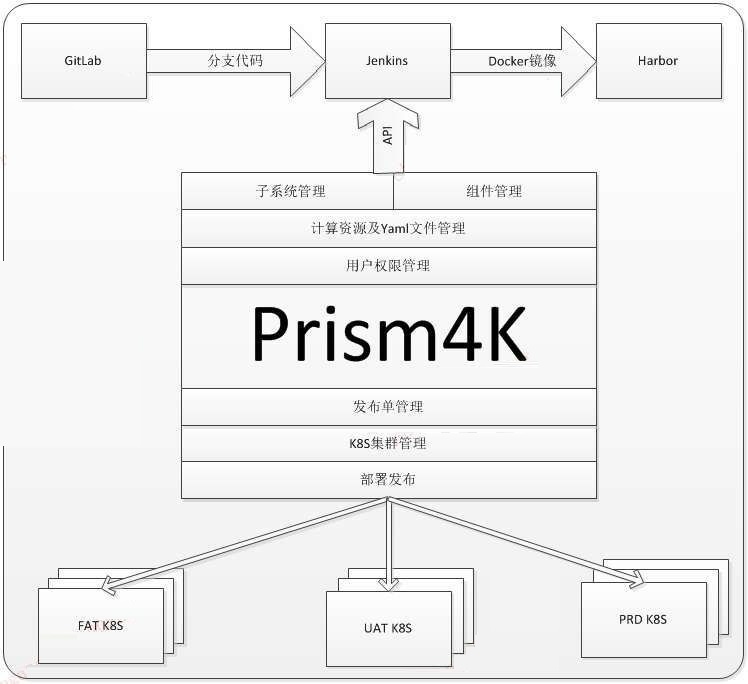
在这种体系下,jenkins就作为我们的一个纯编译工具和中转平台,高效的完成从源代码到镜像的生成。
于每个IT应用相关的变量,脚本都已组织好,放到prism4k上。故而,jenkins只需要一个job,就可以完成各样各样的镜像生成功能。其主要pipeline脚本如下(由于信息敏感,只列举主要流程,有删节):
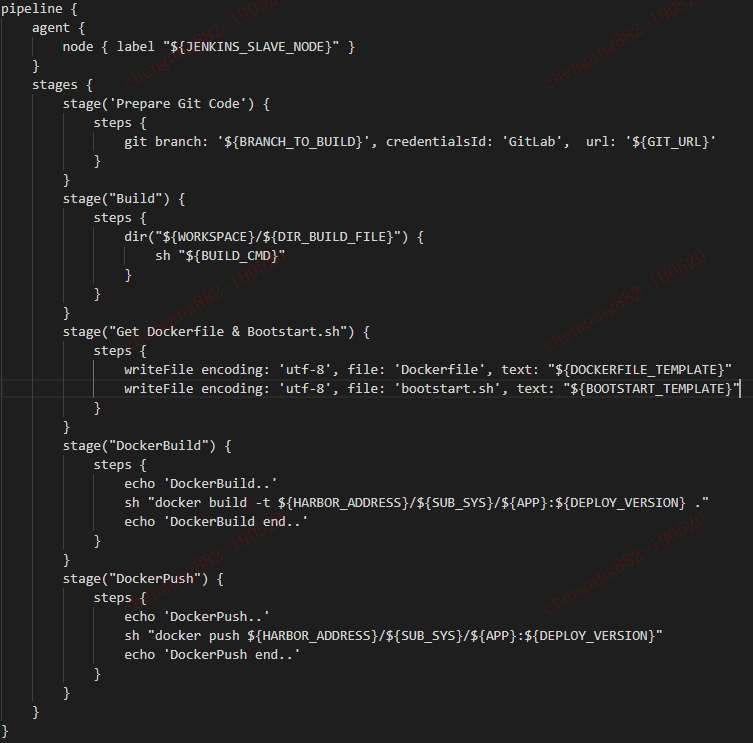
在jenkins中,我们使用了一个Yet Another Docker Plugin,来进行jenkins编译集群进行docker生成时的可扩展性。作到了编译节点的容器即生即死,有编译任务时,指定节点才生成相关容器进行打包等操作。
五, 计算资源在线配置及应用持续部署
在prism4k平台中,针对jenkins的job变量是通过网页配置的。在发布单的编译镜像过程中,会将各个变量通过api发送到jenkins,启动jenkins任务,完成指定task任务。
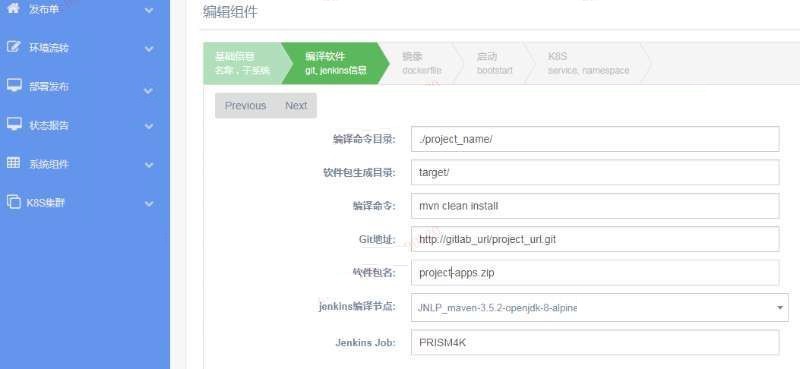
Pod的实例数,cpu和内存的配置,同样通过web方式配置。
Pod的实例数
在配置好组件所有要素之后,日常的流程就可以基于不同部门用户的权限把握,实现流水线化的软件持续交付。
研发:新建发布单,编译软件包,形成镜像,上传harbor库。
测试:环境流转,避免部署操作污染正在进行中的测试。
运维:运维人员进行发布操作。
在FAT这样的测试环境中,为加快测试进度,可灵活的为研发人员赋予运维权限。但在更正式的测试环境和线上生产环境,作为金融行业的IT建设标准,则必须由运维团队成员操作。
下面配合截图,了解一下更具体的三大步骤
1, 发布单
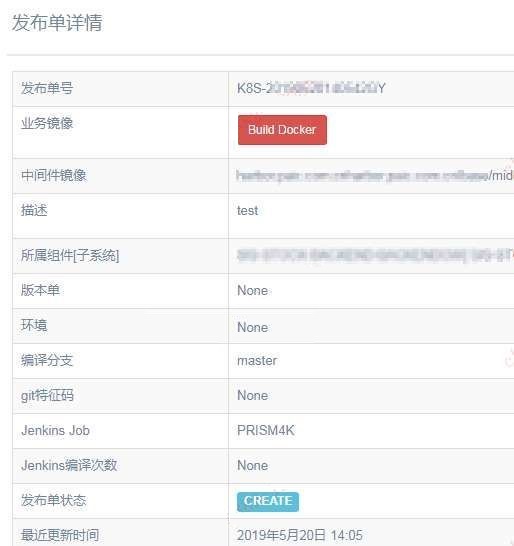
发布单
在prism4k与jenkins的api交互,我们使用了jenkins的python库。
2, 环境流转
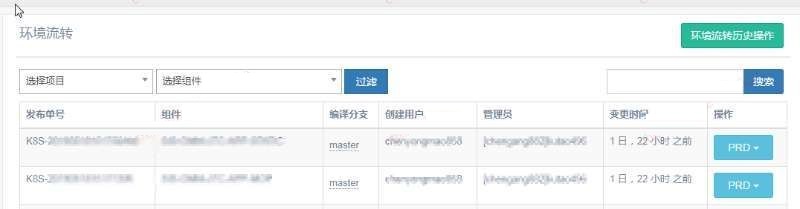
>
环境流转
3, 部署
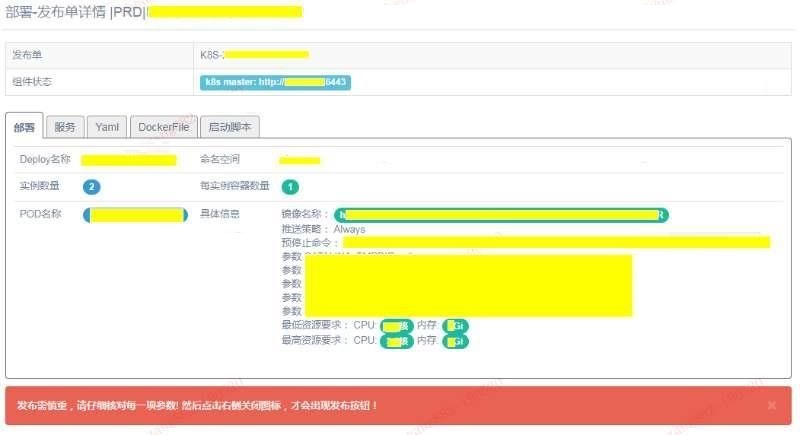
部署
在部署操作过程中,会将这次发布的信息全面展示给运维同事,让运维同事可以进行再次审查,减少发布过程中的异常情况。
总结:
由于k8s版本的快速更新和发布,我们对于其稳定性的功能更为青睐,而对于实验性的功能,或是需要复杂运维技能的功能,则保持理智的观望态度。
所以,我们对k8s功能只达到了中度使用。当然,就算是中度使用,k8s的运维和使用技巧,还是有很多面向在此没有涉及到,希望以后有机会,能和各位有更多的沟通和交流。愿容器技术越来越普及,运维的工作越来越有效率和质量。
感谢各位的宝贵时间!
FQA
Q12:想了解下,yaml文件怎么管理的,可以自定义生成吗
A:我们的Yaml文件,都统一纳到Prism4k平台管理,有一些资源是可以自定义的,且针对不同的项目,有不同的Yaml模板,然后,透过django的模块功能统一作解析。熟悉Yaml书写的研发同事可以自己定义自己项目的Yaml模板。
Q13:master高可用部署,采用域名方式相比于直接使用IP有什么好处与优势呢?
A:采用域名,我在分享中提及,是因为在公司现行的运行体制内设计出来的方案。如果能自己的团队可以全控公司网络和服务资源,我个人也会趋向于VIP的高可用。如果域名方案对于我们团队有优势,是因为这个方案,其它协同部门会同意。:)
Q14:Pipeline会使用Jenkinfile来灵活code化pipeline, 把Pipeline的灵活性和创新性还给开发团队,这比一个模板化的统一Pipeline有哪些优势?
A:pipeline的运行模式,采用单一JOB和每个项目自定义JOB,各有不同的应用场景。因为我们的jenkins是隐于幕后的组件,研发主要基于prism4k操作,可以相对减少研发的学习成本。相对来说,jenkins的维护人力也会减少。
对于研发各种权限比较高的公司,那统一的JOB可能并不合适。
Q15:想了解下贵公司使用什么网络方案?pod的网络访问权限控制怎么实现的
A:公司现在用的是flannel网络CNI方案。同时,在不同的集群,也有作calico网络方案的对比测试。
pod的网络权限,这块暂时没有,只是尝试istio的可行性研究。
Q16: 一个job生成所有的docker镜像,如果构建遇到问题,怎么去追踪这些记录?
A:在项目前期接入时,生成镜像的流程都作了宣传和推广。标准化的流程,会减少产生问题的机率。如果在构建中遇到问题,prism4k的界面中,会直接有链接到本次建的次序号。点击链接,可直接定位到console输出。
Q17:遇到节点 node上出现100+pod,node会卡卡住,贵公司pod资源怎么做限制的
A:我们的业务pod资源,都作了limit和request限制。如果开现有卡住的情况,现行的方案是基于项目作拆分。prism4k本身对多环境和多集群都是支持的。
Q18:多环境下,集中化的配置管理方案,你们选用的是哪个,或是自研的?
A:我们现在正在研发的prism4k,前提就是要支持多环境多集群的部署,本身的功能里,yaml文件的配置管理,都是其内置功能
Q20:能否问一下贵公司镜像加速如何做的吗?
A:我们现在的发布量不是特别巨大,现在只是努力缩小镜像,而镜像加速暂未使用。
Q21: prism4k 研发团队规模是多少人,花了多长的研发周期?
A:两人吧,非全职开发。
2018年底开始开发的,目前功能还在完善之中。
正文到此结束
- 本文标签: 科技 金融 Kubernetes 软件 Uber Go语言 高可用 测试环境 服务器 质量 配置 域名 组织 同步 Job 分布式 zab Nginx jenkins DNS 安装 时间 value 总结 python id Proxy web node zookeeper 代码 key 锁 http Master Dashboard ssh tab js 安全 API Docker 开发 ask 希望 权限控制 java 认证 https apr 管理 json 缩小 推广 Haproxy 分布式锁 2019 目录 测试 git 集群 数据 实例 参数 src IO 一致性 部署 云 协议 ip cat UI 解析 REST 企业 plugin 模型 tag 编译 tomcat
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

