ThreadLocal实现原理
使用场景
假设我们有一个数据库连接管理类:
class ConnectionManager {
private static Connection connect = null;
private static String url = System.getProperty("URL");
public static Connection openConnection() {
if(connect == null){
try {
connect = DriverManager.getConnection(url);
} catch (SQLException e) {
e.printStackTrace();
}
}
return connect;
}
public static void closeConnection() {
if(connect!=null) {
try {
connect.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
如果这个类被用在多线程环境内,则会存在线程安全问题,那么可以对这两个方法添加synchronized关键字进行同步处理,不过这样会大大降低程序的性能,也可以将connection变成局部变量:
class ConnectionManager {
private Connection connect = null;
public Connection openConnection(String url) {
if(connect == null){
try {
connect = DriverManager.getConnection(url);
} catch (SQLException e) {
e.printStackTrace();
}
}
return connect;
}
public void closeConnection() {
if(connect!=null) {
try {
connect.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
class ConnectionManagerTest {
private String url = System.getProperty("URL");
public void insert() {
ConnectionManager connectionManager = new ConnectionManager();
Connection connection = connectionManager.openConnection(this.url);
//使用connection进行操作
connectionManager.closeConnection();
}
public void update() {
ConnectionManager connectionManager = new ConnectionManager();
Connection connection = connectionManager.openConnection(this.url);
//使用connection进行操作
connectionManager.closeConnection();
}
}
每个CURD方法都创建新的数据库连接会造成数据库的很大压力,这里可以有两种解决方案:
- 使用连接池管理连接,既不是每次都创建、销毁连接,而是从一个连接池里借出可用的连接,用完将其归还。参加MyBatis连接管理(1) |MyBatis连接管理(2)
- 可以看到,这里connection的建立最好是这样的:每个线程希望有自己独立的连接来避免同步问题,在线程内部希望共用同一个连接来降低数据库的压力,那么使用ThreadLocal来管理数据库连接就是最好的选择了。它为每个线程维护了一个自己的连接,并且可以在线程内共享。
class ConnectionManager {
private static String url = System.getProperty("URL");
private static ThreadLocal<Connection> connectionHolder = ThreadLocal.withInitial(() -> {
try {
return DriverManager.getConnection(url);
} catch (SQLException e) {
e.printStackTrace();
}
return null;
});
public static Connection openConnection() {
return connectionHolder.get();
}
public static void closeConnection() {
Connection connect = connectionHolder.get();
if(connect!=null) {
try {
connect.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
另外还可以用到其他需要每个线程管理一份自己的资源副本的地方: An Introduction to ThreadLocal in Java
实现原理
这里面涉及到三种对象的映射:Thread-ThreadLocal对象-ThreadLocal中存的具体内容,既然是每个线程都会有一个资源副本,那么这个从ThreadLocal对象到存储内容的映射自然就会存在 Thread 对象里:
ThreadLocal.ThreadLocalMap threadLocals = null;
而ThreadLocal类只是提供了访问这个Map的接口:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
这个ThreadLocalMap是ThreadLocal的内部类,实现了一个类似HashMap的功能,其内部维护了一个Entry数组,下标就是通过ThreadLocal对象的threadLocalHashCode计算得来。这个Entry继承自WeakReference,实现对key,也就是ThreadLocal的弱引用:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
内存模型图如下:
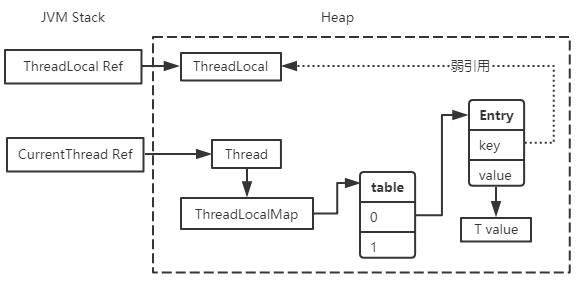
当ThreadLocal Ref出栈后,由于ThreadLocalMap中Entry对ThreadLocal只是弱引用,所以ThreadLocal对象会被回收,Entry的key会变成null,然后在每次get/set/remove ThreadLocalMap中的值的时候,会自动清理key为null的value,这样value也能被回收了。
注意:
如果ThreadLocal Ref一直没有出栈(例如上面的connectionHolder,通常我们需要保证ThreadLocal为单例且全局可访问,所以设为static),具有跟Thread相同的生命周期,那么这里的虚引用便形同虚设了,所以使用完后记得调用ThreadLocal.remove将其对应的value清除。
另外,由于ThreadLocalMap中只对ThreadLocal是弱引用,对value是强引用,如果ThreadLocal因为没有其他强引用而被回收,之后也没有调用过get/set,那么就会产生内存泄露,
在使用线程池时,线程会被复用,那么里面保存的ThreadLocalMap同样也会被复用,会造成线程之间的资源没有被隔离,所以在线程归还回线程池时要记得调用remove方法。
hash冲突
上面提到ThreadLocalMap是自己实现的类似HashMap的功能,当出现Hash冲突(通过两个key对象的hash值计算得到同一个数组下标)时,它没有采用链表模式,而是采用的线性探测的方法,既当发生冲突后,就线性查找数组中空闲的位置。当数组较大时,这个性能会很差,所以建议尽量控制ThreadLocal的数量。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

