Map 综述—彻头彻尾理解 ConcurrentHashMap
本文所有关于 ConcurrentHashMap 的源码都是基于 JDK 1.6 的,不同 JDK 版本之间会有些许差异,但不影响我们对 ConcurrentHashMap 的数据结构、原理等整体的把握和了解
ConcurrentHashMap是J.U.C(java.util.concurrent包)的重要成员,它是HashMap的一个线程安全的、支持高效并发的版本
ConcurrentHashMap 概述
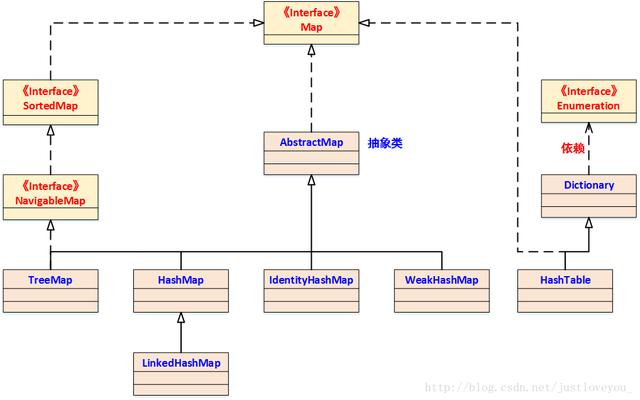
HashMap 是 Java Collection Framework 的重要成员,也是Map族(如下图所示)中我们最为常用的一种。不过遗憾的是,HashMap不是线程安全的
HashMap的这一缺点往往会造成诸多不便,虽然在并发场景下HashTable和由同步包装器包装的HashMap(Collections.synchronizedMap(Map<K,V> m) )可以代替HashMap,但是它们都是通过使用一个全局的锁来同步不同线程间的并发访问,因此会带来不可忽视的性能问题。庆幸的是,JDK为我们解决了这个问题,它为HashMap提供了一个线程安全的高效版本 —— ConcurrentHashMap
在ConcurrentHashMap中,无论是读操作还是写操作都能保证很高的性能:在进行读操作时(几乎)不需要加锁,而在写操作时通过锁分段技术只对所操作的段加锁而不影响客户端对其它段的访问。特别地, 在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设为16),及任意数量线程的读操作
- 通过锁分段技术保证并发环境下的写操作;
- 通过 HashEntry的不变性、Volatile变量的内存可见性和加锁重读机制保证高效、安全的读操作;
- 通过不加锁和加锁两种方案控制跨段操作的的安全性。
ConcurrentHashMap 在 JDK 中的定义
ConcurrentHashMap类中包含两个静态内部类
- HashEntry: 用来封装具体的K/V对,是个典型的四元组
- Segment:用来充当锁的角色,每个 Segment 对象守护整个ConcurrentHashMap的若干个桶 (可以把Segment看作是一个小型的哈希表),其中每个桶是由若干个 HashEntry 对象链接起来的链表
ConcurrentHashMap 在默认并发级别下会创建16个Segment对象的数组,如果键能均匀散列,每个 Segment 大约守护整个散列表中桶总数的 1/16。
类结构定义
ConcurrentHashMap 继承了AbstractMap并实现了ConcurrentMap接口,其在JDK中的定义为:
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
...
}
复制代码
成员变量定义
与HashMap相比,ConcurrentHashMap 增加了两个属性用于定位段,分别是 segmentMask 和 segmentShift 。此外,不同于HashMap的是, ConcurrentHashMap底层结构是一个Segment数组,而不是Object数组
final int segmentMask; // 用于定位段,大小等于segments数组的大小减 1,是不可变的 final int segmentShift; // 用于定位段,大小等于32(hash值的位数)减去对segments的大小取以2为底的对数值,是不可变的 final Segment<K,V>[] segments; // ConcurrentHashMap的底层结构是一个Segment数组 复制代码
段的定义:Segment
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色
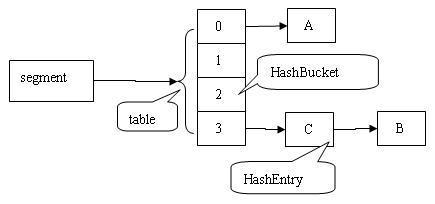
在Segment类中,count 变量是一个计数器,它表示每个 Segment 对象管理的 table 数组包含的 HashEntry 对象的个数,也就是 Segment 中包含的 HashEntry 对象的总数。特别需要注意的是,之所以在每个 Segment 对象中包含一个计数器,而不是在 ConcurrentHashMap 中使用全局的计数器,是对 ConcurrentHashMap 并发性的考虑: 因为这样当需要更新计数器时,不用锁定整个ConcurrentHashMap
基本元素:HashEntry
与HashMap中的Entry类似,HashEntry也包括同样的四个域,分别是key、hash、value和next。 不同的是,在HashEntry类中,key,hash和next域都被声明为final的,value域被volatile所修饰,因此HashEntry对象几乎是不可变的,这是ConcurrentHashmap读操作并不需要加锁的一个重要原因
由于value域被volatile修饰,所以其可以确保被读线程读到最新的值,这是ConcurrentHashmap读操作并不需要加锁的另一个重要原因。
ConcurrentHashMap 的构造函数
1,ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel)
该构造函数意在构造一个具有指定容量、指定负载因子和指定段数目/并发级别(若不是2的幂次方,则会调整为2的幂次方)的空ConcurrentHashMap
2,ConcurrentHashMap(int initialCapacity, float loadFactor)
该构造函数意在构造一个具有指定容量、指定负载因子和默认并发级别(16)的空ConcurrentHashMap
3,ConcurrentHashMap(int initialCapacity)
该构造函数意在构造一个具有指定容量、默认负载因子(0.75)和默认并发级别(16)的空ConcurrentHashMap
4,ConcurrentHashMap()
该构造函数意在构造一个具有默认初始容量(16)、默认负载因子(0.75)和默认并发级别(16)的空ConcurrentHashMap
5,ConcurrentHashMap(Map<? extends K, ? extends V> m)
该构造函数意在构造一个与指定 Map 具有相同映射的 ConcurrentHashMap,其初始容量不小于 16 (具体依赖于指定Map的大小),负载因子是 0.75,并发级别是 16, 是 Java Collection Framework 规范推荐提供的
小结
在这里,我们提到了三个非常重要的参数: 初始容量 、 负载因子 和 并发级别 ,这三个参数是影响ConcurrentHashMap性能的重要参数
ConcurrentHashMap 的数据结构
通过使用段(Segment)将ConcurrentHashMap划分为不同的部分,ConcurrentHashMap就可以使用不同的锁来控制对哈希表的不同部分的修改,从而允许多个修改操作并发进行, 这正是ConcurrentHashMap锁分段技术的核心内涵
ConcurrentHashMap 的并发存取
在ConcurrentHashMap中,线程对映射表做读操作时,一般情况下不需要加锁就可以完成,对容器做结构性修改的操作(比如,put操作、remove操作等)才需要加锁。
用分段锁机制实现多个线程间的并发写操作: put(key, vlaue)
在ConcurrentHashMap中,典型结构性修改操作包括put、remove和clear,下面我们首先以put操作为例说明对ConcurrentHashMap做结构性修改的过程
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
}
复制代码
ConcurrentHashMap不同于HashMap,它既不允许key值为null,也不允许value值为null
定位段的segmentFor()方法源码如下
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
复制代码
根据key的hash值的高n位就可以确定元素到底在哪一个Segment中
段的put()方法的源码如下所示
V put( K key, int hash, V value, boolean onlyIfAbsent )
{
lock(); /* 上锁 */
try {
int c = count;
if ( c++ > threshold ) /* ensure capacity */
rehash();
HashEntry<K, V>[] tab = table; /* table是Volatile的 */
int index = hash & (tab.length - 1); /* 定位到段中特定的桶 */
HashEntry<K, V> first = tab[index]; /* first指向桶中链表的表头 */
HashEntry<K, V> e = first;
/* 检查该桶中是否存在相同key的结点 */
while ( e != null && (e.hash != hash || !key.equals( e.key ) ) )
e = e.next;
V oldValue;
if ( e != null ) /* 该桶中存在相同key的结点 */
{
oldValue = e.value;
if ( !onlyIfAbsent )
e.value = value; /* 更新value值 */
}else { /* 该桶中不存在相同key的结点 */
oldValue = null;
++modCount; /* 结构性修改,modCount加1 */
tab[index] = new HashEntry<K, V>( key, hash, first, value ); /* 创建HashEntry并将其链到表头 */
count = c; /* write-volatile,count值的更新一定要放在最后一步(volatile变量) */
}
return(oldValue); /* 返回旧值(该桶中不存在相同key的结点,则返回null) */
} finally {
unlock(); /* 在finally子句中解锁 */
}
}
复制代码
相比较于 HashTable 和由同步包装器包装的HashMap每次只能有一个线程执行读或写操作,ConcurrentHashMap 在并发访问性能上有了质的提高。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

