Building Microservices(O'Reily 2015)
前言
Building Microservices: Designing Fine Grained Systems 读书笔记。
本书偏理论而非实现,可作为内功心法,适合架构师或有经验的系统工程师。
常读常新。
前言
微服务是分布式系统提高 细粒度服务 (use of finely grained services)使用的一种 方式,在这种模式中,每个服务都有自己 独立的生命周期 ,所有服务共同合作完成整体 的功能。
微服务主要是 针对业务领域建模 的(modeled around business domains),因此可以 避免传统 分层架构 (tiered architecture)的一些缺点。
微服务价格提供了越来越多的 自治性 (increased autonomy)。
1 微服务
Domain Driven Design :如何对系统建模。
领域驱动设计(DDD)、持续交付(CD)、按需虚拟化(On-demand virtualization)、基 础设施自动化(Infrastructure automation)、小自治团队(Small autonomous teams) 、大规模系统(Systems at scale):这些都是微服务产生的前提。
微服务并不是凭空设计的,而是真实需求催生的。
什么是微服务?
微服务:小的、自治的、一起工作的服务。
-
小:专注、只做好一件事情
很难确定多小才算小,但是比较容易确定多大就算大:如果你觉得一个系统该拆分了, 那它就是太大了
-
自治
判断标准:对一个服务进行改动升级,不影响其他服务
主要好处
- 技术异质性(Technology Heterogeneity)
- 不同组件可以采用不同语言、框架、数据库类型等等。综合考虑功能、性能、成本等 ,选择最优的方案
- 新技术落地更方便
- 容错性(Resilience)
- 容错工程的一个核心概念: bulkhead (防水壁)。一个组件出差,错误不应该瀑 布式传递给其他系统(cascading),做到错误隔离
- 但也应该认识到,微服务(分布式系统)跟单体应用相比,会引入新的故障源( sources of failure),例如网络故障、机器故障
- 扩展性(Scaling)
- 易于部署(Ease of Deployment)
- 架构和组织对齐(Organizational Alignment)
- 多个小团队维护独立的较小的代码库,而不是大家一起维护一个很大的代码库
- 可组合性(Composability)
- 单个服务可以同时被不同平台使用,例如一个后端同时服务 PC、Mobile、Tablet 的访 问
- 易于替换组件(Optimizing for Replaceability)
SOA 与微服务
面向服务的架构(Service-oriented architecture,SOA)是一种多个服务协同工作来提供 最终功能集合(end set of capabilities)的设计方式。这里的服务通常是操作系统中 完全独立的进程 。服务间的调用是跨网络的,而不是进程内的函数调用。
SOA 的出现是为了应对 庞大的单体应用 (large monolithic applications)带来的挑战。 它的 目的是提高软件的重用性 (reusability of software),例如多个终端用户应用 使用同一个后端服务。SOA 致力于 使软件更易维护和开发 ,只要保持服务的语义不变, 理论上换掉一个服务其他服务都感知不到。
SOA 的思想是好的,但是, 关于如何做好 SOA,业界并没有达成共识 。在我看来, 很 多厂商鼓吹 SOA 只是为了兜售他们的产品 ,而对业界大部分人对 SOA 本身还缺少全面和 深入的思考。
SOA 门前的问题包括:通信协议(e.g. SOAP)、厂商中间件、对服务粒度缺乏指导、对在 哪切分单体应用的错误指导等等。愤青(cynic)可能会觉得,厂商参与 SOA 只是为他们卖 自家产品铺路,而这些大同小异的(selfsame)产品反而会削弱(undermine) SOA 的目标。
SOA 的常规实践经验(conventional wisdom)并不能帮助你确定如何对一个大应用进行拆分。 例如,它不会讨论多大算大,不会讨论实际项目中如何避免服务间的过耦合。 而这些没有讨论的东西都是 SOA 真正潜在的坑。
微服务源自真实世界的使用(real-world use),因此它对系统和架构的考虑比 SOA 要更 多。可以做如下类比: 微服务之与 SOA 就像极限编程(XP)之与敏捷开发(Agile ) 。
其他拆分方式
- 共享库(Shared Libraries):语言、操作系统、编译器等绑定
- 模块(Modules):模块/代码动态更新,服务不停。例如 Erlang
没有银弹
微服务并不是银弹,错误的选择会导致微服务变成闪着金光的锤子(a golden hammer)。 微服务带来的挑战主要源自分布式系统自有的特质。需要在部署、测试、监控等方面下功夫 ,才能解锁服务器带来的好处。
总结
2 演进式架构师(The Evolutionary Architect)
软件工程和建筑工程的角色对比
计算机和软件行业很年轻,才六七十年。“工程师”、“架构师”(architect,在英文里和建 筑师是同一个单词)等头衔都是从其他行业借鉴过来的。但是,同样的头衔在不同行业所 需承担的职责是有很大差别的,简单来说就是: 软件行业中的头衔普遍虚高,且对自己工 作成果所需承担的责任都很小 。例如,建筑师设计的房子倒塌的概率,要比架构师设计的 软件崩溃的概率小得多。
另一方面,软件工程设计和建筑工程设计也确实有不同。例如桥梁,设计建好之后基本桥就 不动了,而软件面向的是一直在变化的用户需求,架构要有比较好的可演进性。
建筑设计师更多的会考虑物理定律和建材特性,而软件架构师容易飘飘然,与实现脱节,最 后变成纸上谈兵,设计出灾难性的架构。
架构师应具备的演进式愿景
客户的需求变化总是比架构师想象中来的更快,软件行业的技术和工具迭代速度也比传统行 业快得多。 架构师不应该执着于设计出完美的终极架构,而更应该着眼于可演进的架构。
软件架构师的角色与游戏《模拟城市》( SimCity )里镇长(town planner)的角色 非常相似,做出每个决策时都需要考虑到未来。
人们经常忽视的一个事实是: 软件系统并不仅仅是给用户使用的,开发和运维工程师也 要围绕它工作,因此系统设计的也要对开发和运维友好 。
Architects have a duty to ensure that a system is habitable for developers too.
总结起来一句话:设计一个让 用户 和 开发者 都喜欢的系统。
那么,如何才能设计出这样的系统呢?
Zoning(服务或服务组边界)
架构师应该更多地关心 服务间 发生的事情,而不是 服务内 发生的事情。
Be worried about what happens between boxs, and be liberal in what happens inside.
每个服务可以灵活选择自己的技术栈,但如果综合起来技术栈太过分散庞杂,那成本也会非 常高,并且规模很难做大。需要在技术栈选择的灵活性和整体开发运维成本之间取得一个 平衡。举例,Netflix 大部分服务都是使用 Cassandra。
参与写代码的架构师(The coding architect)
架构师花一部分时间参与到写代码,对项目的推进会比只是画图、开会、code review 要 有效得多。
A Principled Approach
架构设计就是一个不断做出选择(折中)的过程(all about trade-offs),微服务架构给 我们的选择尤其多。
原则化(Framing):Strategic Goals -> Principles -> Practices.
A great way to help frame our decision making is to define a set of principles and practices that guide it, based on goals that we are trying to achieve.
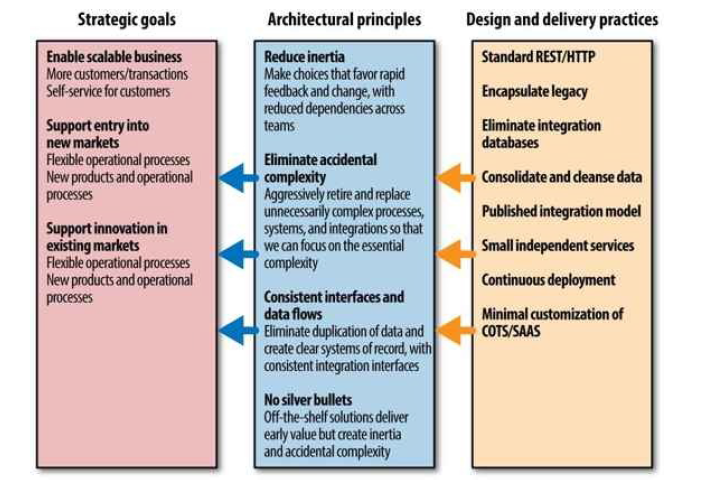
图 2-1 一个真实世界的原则和实践(principles and practices)的例子
最好提供 文档 和 示例代码 ,甚至是额外的工具,来解释这些原则和实践标准。
The Required Standard
一个好的微服务应该长什么样:
It needs to be a cohesive system made of many small parts with autonomous life cycles but all coming together.
监控
建议所有的服务都对外暴露健康和监控信息。
- Push 模型:主动向外发送信息,例如 telegraf
- Pull 模型:暴露端口,被动地被其他组件收集,例如 prometheus
接口(API)
API 有多种可选的实现方式。 从粗的维度包括 HTTP/REST、RPC 等等,细的维度还包括它们各自内部的各自标准。例如, HTTP/REST API 里用动词还是名词、如何处理分页、如何处理不同 API 版本等等。
尽量保持在两种以内。
架构安全性(Architectural Safety)
不能因为一个服务挂掉,导致整个系统崩溃。 每个服务都应该在设计时就考虑到依 赖的组件崩溃的情况 。这包括:
- 线程池的连接数量
- 熔断(circut breaker)
- 快速失败(fast fail)
- 统一的错误码(例如 HTTP Code)
确保代码符合规范(Governance Through Code)
两项有效的方式:
- exemplars
- service templates
Exemplars
Tailored Service Templates
将同样的东西统一化,可以库、代码模板或其他形式:
- 健康检查
- HTTP Handler
- 输出监控信息的方式
- 熔断器/方式
- 容错处理
但注意不要喧宾夺主,过于庞大的模板和库也是一种灾难。
技术债(Technical Debt)
技术债不一定都是由拙劣的设计导致的。例如,如果后期的发展方向偏离了最初的设计 目标,那部分(甚至大部分)系统也会成为技术债。
技术债也并不是一经发现就要投入精力消除。 架构师应该从更高的层面审视这个问题,在”立即还债”和”继续忍耐”之间取得一个平衡。
维护一个技术债列表,定期 review。
例外处理
如果你所在的公司对开发者的限制非常多,那微服务并不是适合你们。
总结
演进式架构师的核心职责:
- 技术愿景(Vision):对系统有清晰的技术愿景,并且与团队充分沟通,系统满足客户和 公司的需求
- 深入实际(Empathy,理解):理解你的决定对客户和同事产生的影响
- 团结合作(Collaboration):与同事紧密合作来定义、优化和执行技术愿景
- 拥抱变化(Adaptability,自适应性):技术愿景能随着客户需求的变化而变化
- 服务自治(Autonomy,自治性):在标准化和允许团队自治之间取得平衡
- 落地把控(Governance):确保系统是按照技术愿景实现的
这是一个长期的寻求平衡的过程,需要经验的不断积累。
3 如何对服务建模
划分微服务的边界。
良好的微服务的标准
标准:
- 低耦合(loose coupling)
- 高内聚(high cohesive)
这两个术语在很多场合,尤其是面向对象系统(object oriented systems)中已经被用烂 了,但我们还是要解释它们在微服务领域里表示什么。
低耦合
哪些事情会导致高耦合?一种典型的场景是 错误的系统对接(integration)方式 ,导致依赖其他服务。
低耦合的系统对其他系统知道的越少越好,这意味着,我们也许应该减少服务间通信的种类 。啰嗦(chatty)的通信除了性能问题之外,还会导致高耦合。
高内聚
相关的逻辑集中到一起,改动升级时便只涉及一个组件。因此,核心问题转变成: 确 定问题域的边界 。
有界上下文(The Bounded Context)
《领域驱动设计》:对真实世界域(real-world domains)进行建模来设计系统。 其中一个重要概念: bounded context 。
Bounded Context: Any given domain consists of multiple bounded contexts, and residing within each are things that do not need to communicate outside as well as things that are shared externally with other bounded contexts. Each bounded context has an explicit interface, where it decides what models to share with other contexts.
Bounded context 的另一种定义: 由显式的边界定义的具体的责任 (a specific responsibility enforced by explicit boundarries)。类比:细胞膜(membrance),细 胞之间的边界,决定了哪些可以通过,哪些需要保持在细胞内部。
Shared and Hidden Model
一般来说,如果一个 model 需要对外暴露,那对外的和内部使用的 model 也应该是不同的 ,因为很多细节是只有内部才需要的,没有必要暴露给外部,因此会分为:
- shared models:bounded context 对外暴露的 models
- hidden models:bounded context 内部使用的 models
举例:订单的模型,
- Hidden model:在数据库中的表示
- Shared model:在 REST API 中的表示
Modules and Services
Shared model 和 hidden model 使得服务间不依赖内部细节,实现了解耦。
确保 bounded context 实现成一个代码模块(module),以实现高内聚。这些模块化的边 界,就是微服务的理想分割点。
如果 服务的边界 和问题域的 bounded context 边界是对齐的,而且我们的微服务能够 表示(represent)这些 bounded context,那么我们就走在了低耦合和高内聚的正确道路 上。
过早拆分(Premature Decomposition)
项目早期,边界一直在变化,不适合拆分成微服务。应该等边界比较稳定之后再开始。
业务功能(Business Capabilities)
设计一个 bounded context 首先应该考虑的不是 共享什么数据 ,而是这个bounded context 能为域内的其他服务提供什么功能(capability) 。如果一上来就考虑数据模 型,很容易设计出缺乏活力的(anemic)、基于 CRUD (增删查改)的服务。
Turtles All the Way Down
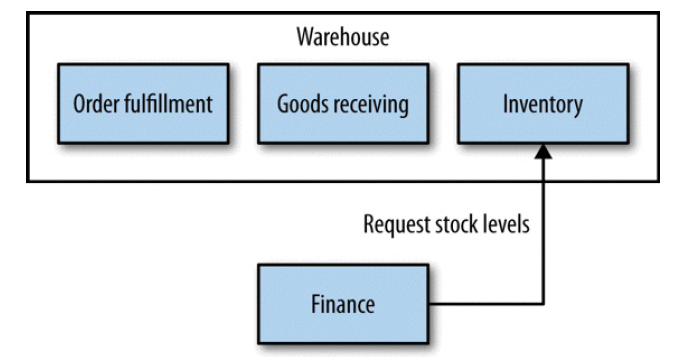
图 3-2 Microservices representing nested bounded contexts
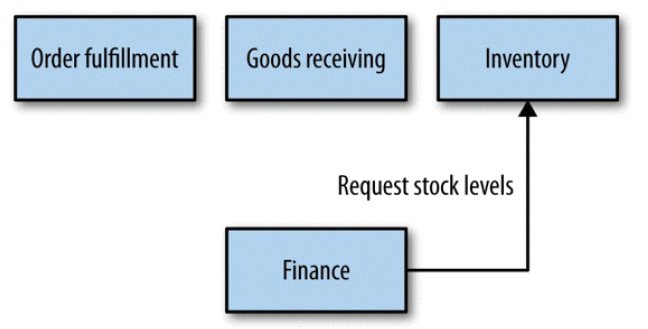
图 3-3 The bounded contexts being popped up into their own top-level contexts
选择哪种需要视组织结构:如果上面三个服务是同一个团队负责的,那 3-2 比较合适;如 果是三个不同团队负责的,那 3-3 比较合适。康威定律。
另外,测试的难易程度也会有差异。
Communication in Terms of Business Concepts
The Technical Boundary
避免: 洋葱架构 (onion architecture)。软件层级非常多,从上往下切的时候,会让 人忍不住掉眼泪。
Summary
本章学习了什么是一个好的服务,如何找出问题域的边界,以及由此带来的两个好处:低耦 合和高内聚。Bounded context 是帮助我们完成这一目的的利器。
《领域驱动设计》描述了如何找出恰当的边界,这本书非常经典,本章只是涉及了它的一点 皮毛(scratched the surface)。另外,推荐《领域驱动设计实现》( Implementing Domain-Driven Design ),以帮助更好的理解 DDD 的实践。
4 集成
我个人认为, 集成(integration)是微服务中最重要的一方面 。集成方案设计的好, 万事 OK;设计的不好,坑(pitfall)会一个接着一个。
确定最佳的集成技术
SOAP、XML-RPC、REST、ProtoBuf 等等。
避免不兼容改动(breaking changes)
尽最大努力。
保持 API 技术无感知(technology-agnostic)
如果你在 IT 行业已经混了 15 分钟以上,那就不用我提醒你这个行业变化有多快了。
If you have been in the IT industry for more than 15 minutes, you don’t need me to tell you that we work in a space that is changing rapidly.
新的技术、平台、工具不断涌现,其中一些用好了可以极大提高效率,因此 API 不应该绑 死到一种技术栈。
使服务对客户尽量简单
从选择的角度讲,应该允许客户使用任何技术来访问服务。
从方便的角度讲,给客户提供一个客户端库会大大方便他们的使用。但也也会造成和服务端 的耦合,需要权衡。
避免暴露内部实现
暴露内部实现会增加耦合。任何会导致暴露内部实现的技术,都应该避免使用。
共享数据库
这也是最简单、最常用的集成方式是: 数据库集成 (DB integration,使用同一个数据库)。
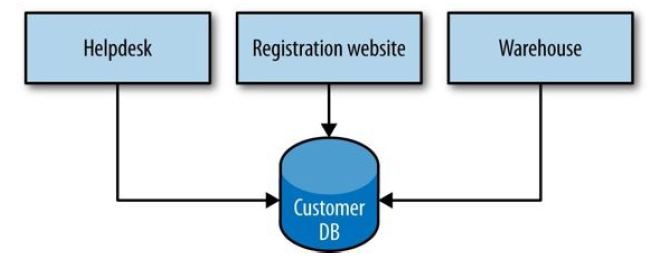
图 4-1 数据库集成
缺点:
- 允许外部组件直接查看和绑定内部实现细节
- 修改数据库的字段会影响所有相关服务
- 回归测试麻烦
- 外部组件被迫绑定到特定技术(数据库实现)
- 如果要从关系数据库切换到非关系数据库,外部组件也得跟着改
- 高耦合
- 外部组件包含相同逻辑,例如查询,修改数据库
- 要修一个 bug 或加一个 feature,得改每一个组件
- 低内聚
微服务的两个标准:低耦合和高内聚,被破坏殆尽。
Database integration makes it easy for services to share data, but does nothing about sharing behavior .
异步还同步
同步和异步会导致不同的协助模式:
- 同步:请求/响应式(request/response)
- 客户端主动发起请求,然后等待结果
- 同步请求 + 回调函数 的方式也属于请求/响应模式
- 异步:事件驱动式(event-based)
- 服务端主动通知客户端发生了某事件
- 从本质上(by nature)就是异步的
- 处理逻辑更分散,而不是集中到一个系统
- 低耦合,服务只负责发事件通知,谁会对此事件作出反应,它并不知道,也不关心
- 添加新的订阅者时,客户端无感知
选择哪种模式?重要标准: 哪个更适合解决常见的复杂场景问题 ,例如跨多个服务的请 求调用。
Orchestration Versus Choreography(管弦乐编排 vs 舞蹈编排)
- 管弦乐编排 :有一个中心的指挥家(conductor),指示每个乐队成员该做什么
- 舞蹈编排 :没有指挥家,每个舞蹈演员各司其职
以创建一个新用户的流程为例:
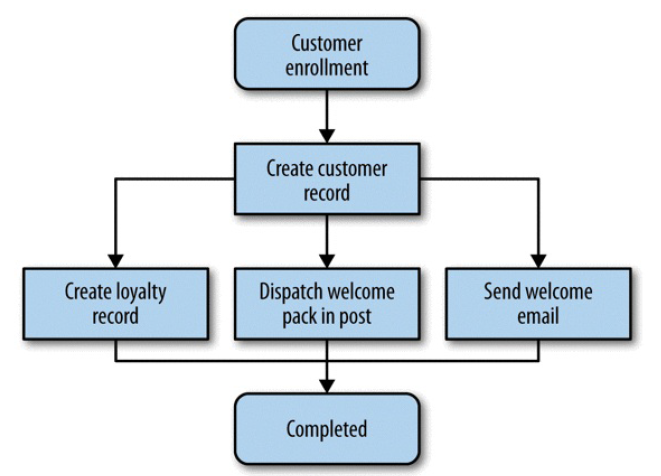
图 4-2 The process for creating a new customer
管弦乐编排(同步)模式
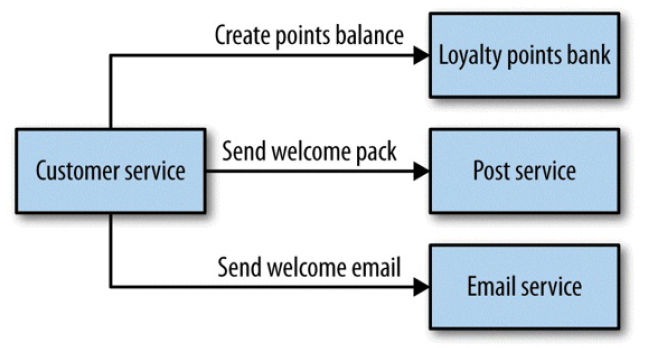
图 4-3 Handling customer creation via orchestration
优点:
- 很容易将流程图转变成代码实现,甚至有工具做这种事情,例如合适的规则引擎(rule engine)。另外还有很多商业软件专门做这种事情(business process modeling software)
- 如果使用同步方式,编排器(大脑)还能知道每个阶段的调用是否成功
缺点:
- 编排器成为核心,很大一部分逻辑都实现在这里
- 单点及性能问题
舞蹈编排(异步)模式
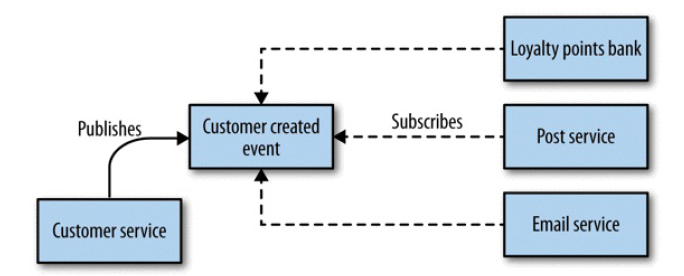
图 4-4 Handling customer creation via choreography
优点:
- 耦合更低、更灵活、更易扩展
- 添加新订阅者方便,不需要改编排器代码
缺点:
- 架构更松散,只能隐式地反映流程图
- 需要更好的监控和跟踪系统,才能高效排障
总体来说优先推荐舞蹈编排模式。也可以两者结合使用。
请求/响应式设计时两者常见的通信方式:RPC 和 REST。
RPC
存在的几个问题:
- 远程过程调用和本地(函数)调用看起来一模一样,但实际上不一样,性能差很多
- 契约字段基本上只增不减(expand only),否则会破坏老版本兼容性,最后导致大量不 用的字段留在协议里
Compared to database integration, RPC is certainly an improvement when we think about options for request/response collaboration.
RPC 的性能一般更好,因为它们可以采用二进制格式:
- 消息体更小
- 延迟更低
REST
资源 对外的表现形式 (JSON、XML 等)和它们 在服务内的存储形式 是完全分开的。
REST 本身并没有限定底层协议,但事实上用的最多的还是 HTTP 一种。
虽然性能没有 RPC 好,但很多情况下, REST/HTTP 仍然是服务间通信的首选。
基于事件的异步协作实现
技术选择(Technology Choices)
需要消息队列这样的中间件。
中间件应该 聚焦其功能本身 ,其他逻辑都实现在服务中:
Make sure you know what you’re getting: keep your middleware dumb, and keep the smarts in the endpoints.
异步架构的复杂之处
建议在上异步架构之前,做好 监控和追踪方案 (例如生成关联 ID,在不同服务 间跟踪请求)。
强烈建议 Enterprise Integration Pattern 一书。
服务即状态机(Services as State Machines)
每个服务都限定在一个 bounded context 内,所有与此 context 相关的逻辑都封装在其内 部。服务控制着 context 内对象的整个生命周期。
DRY 和微服务里的代码重用
DRY:Don’t Repeat Yourself.
DRY 一般已经简化为避免 代码 重复,但实际上更严格地说,它指的是避免系统 行为和 知识 的重复。
DRY 落实到实现层面就是将公用的部分抽象成库,但注意,这在微服务里可能会导致问题。 例如,如果所有服务都依赖一个公用库,那这些服务也就形成了耦合。当其中一个服务想( 不兼容)更新这个库的时候,其他服务都得跟着升级,导致服务间独立升级的假设被打破。
Rule of thumb: don’t violate DRY within a microservice, but be relaxed about violating DRY across all services.
耦合的代价比代码重复的代价高的多。
典型的例子:客户端程序。
写服务端的团队最好不要同时提供标配客户端,否则服务端实现细节会不知不觉地泄漏 到客户端程序,导致耦合。
if the same people create both the server API and the client API, there is the danger that logic that should exist on the server starts leaking into the client.
这方面做的比较好的:AWS。AWS API 通过 SDK 的形式访问,而这些 SDK 要么是有社区自 发开发的,要么是 AWS API 以外的团队开发的。
make sure that the clients are in charge of when to upgrade their client libraries: we need to ensure we maintain the ability to release our services independently of each other!
Access by Reference
当一个订单确定之后,需要以事件的方式通知邮件系统给用户发一封邮件。两种选择:
- 将订单信息放到消息体里,邮件系统收到消息后就发送邮件
- 将订单索引放到消息体里,邮件系统收到消息后先去另外一个系统去获取订单详情,再 发送邮件
在基于事件的方式中,我们经常说这个事件 发生了 ( this happened ),但我们需要 知道的是: 发生了什么 ( what happened )。
第三种选择:同时带上订单信息和索引,这样事件发生时,邮件系统既能及时得到最新通知 ,在未来一段时间又能主动根据索引去查询当前详情。
Versioning
Defer It as Long as Possible
客户端对消息的解析要有足够的兼容性,老版本客户端收到新字段时不做处理,称为 Tolerant Reader 模式。
健壮性定理(the robustness principle):
Be conservative in what you do, be liberal in what you accept from others.
Catch Breaking Changes Early
消费者驱动型合约(consumer-driven contracts)。
Use Semantic Versioning
版本号格式: <major>.<minor>.<patch> ,含义:
<major> <minor> <patch>
Coexist Different Endpoints(同时支持不同版本的 API)
引入不兼容 API 时,同时支持新老版本:
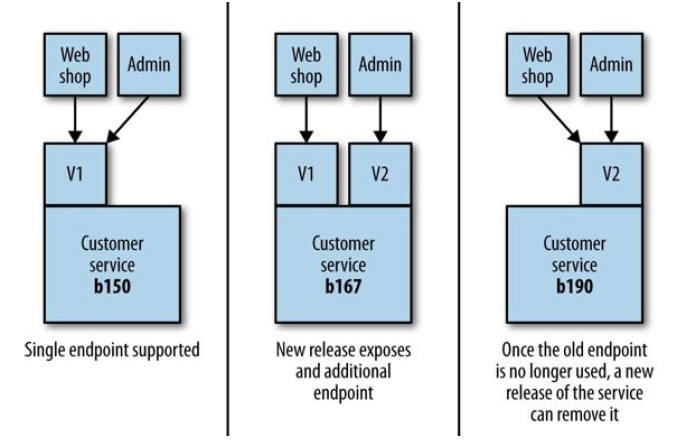
图 4-5
这是 扩展与合约模式 (expand and contract pattern)的一个例子,用于分阶段引入 不兼容更新(phase breaking changes in)。首先扩展(expand)我们提供的功能,同时 提供新老方式;当老用户迁移到新方式后,按照 API 合约(contract),删除老功能。
Integration with Third-Party Software
The Strangler Pattern(阻气门模式)
在老系统前面加一层服务专门做代理,屏蔽背后的系统。这样后面的系统不论是升级、改造 甚至完全换掉,对其他系统都是无感知的。
with a strangler you capture and intercept calls to the old system. This allows you to decide if you route these calls to existing, legacy code, or direct them to new code you may have written. This allows you to replace functionality over time without requiring a big bang rewrite.
总结
保持系统解耦的建议:
- 不要通过数据库集成
- 理解 REST 和 RPC 的区别,推荐先从基于 REST 的request/response 模式开始做起
- 优先考虑 舞蹈编排模式 (Prefer choreography over orchestration)
- 避免不兼容更新,理解版本化的必要,理解健壮性定理、tolerant reader 模式
5 拆分单体应用
It’s All About Seams
Working Effictively with Legacy Code (Prentice Hall)一书中定义了 Seam 的 概念:隔离的、独立的代码块。
Bounded contexts make excellent seams.
一些语言提供了 namespace,可以隔离代码。
将不同部分实现为不同模块(module 或 package)。
应该采用渐进式拆分。
拆分单体应用的原因
1. 局部频繁变化(Pace of Change)
预见到某一部分接下来会频繁变化,将其单独抽离出来。更新部署会更快,单元测试也更 方便。
2. 团队结构变化(Team Structure)
团队拆分、合并等变化,软件系统能跟随组织结构变化,会提高开发效率。康威定律。
3. 新技术应用方便(Technology)
便于某一部分功能采用新技术,如新语言、新框架等等。
错综复杂的依赖(Tangled Dependencies)
有向无环图(DAG)可以帮助分析依赖。
The mother of all tangled dependencies: the database.
使用一些可视化工具查看数据库表之间的依赖,例如 SchemaSpy 等。
例子:外键关联
数据库依赖解耦:去除不同 bounded context 之间的外键关联。
例子:共享的静态数据
例如,国家代码,原来可能存在数据库,所有组件都访问。
解决方式:
- 每个服务都复制一份:以代码或配置文件的方式存储;如果数据会被修改,需要解决数据一致性问题
- 单独抽象一个服务,提供静态数据服务:适用于静态数据很复杂的场景
例子:共享的可变数据(mutable data)
两个服务都需要更新同一张表。
解决方式:需要抽象出两个服务间的公共部分,单独一个组件,完成对表的更新。
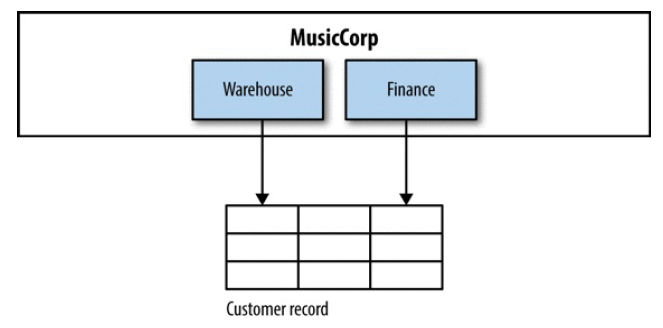
图 5-5 Accessing customer data: are we missing something?
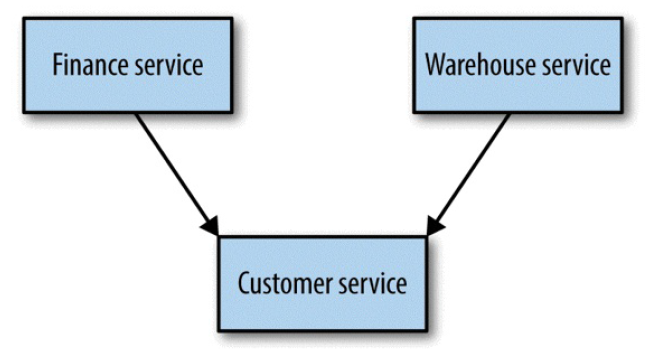
图 5-6 Recognizing the bounded context of the customer
例子:共享表
拆表。
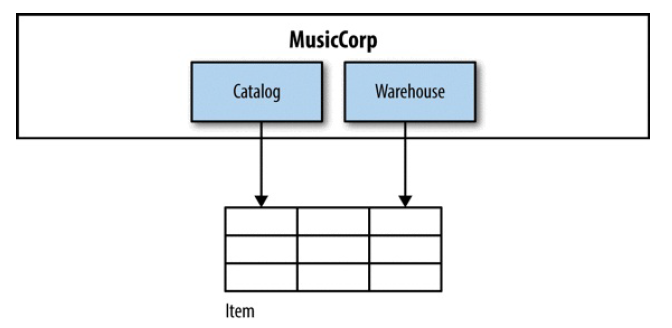
图 5-7 Tables being shared between different contexts
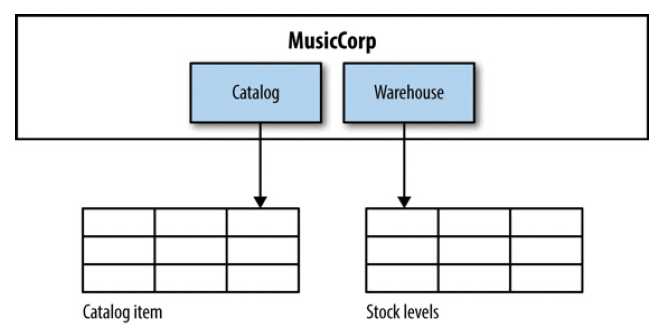
图 5-8 Pulling apart the shared table
数据库重构
Book: Refactoring Database , Addison-Wesley
Staging the Break
先拆分库,再拆分服务,步子不要迈得太大:
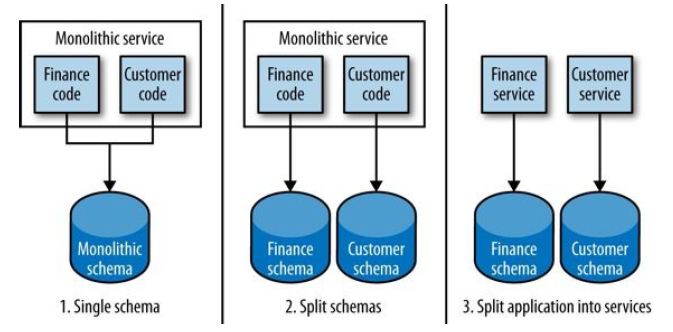
图 5-9 Staging a service separation
事务边界(Transactional Boundaries)
拆分成独立服务后,原来单体应用中的事务边界就丢失了,拆分后需要解决原子性的问题。
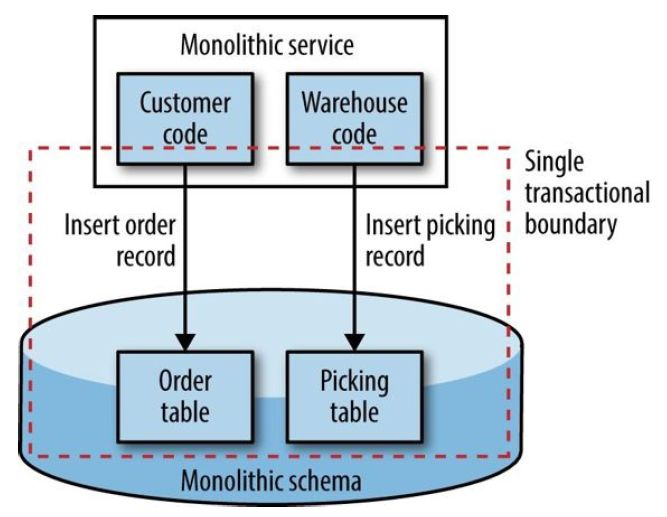
图 5-10 Updating two tables in a single transaction
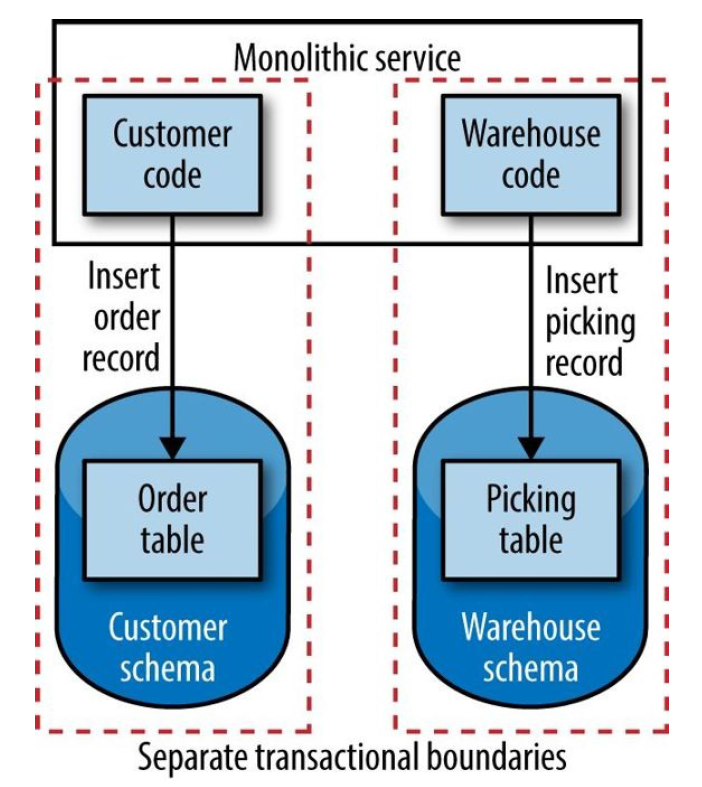
图 5-11 Spanning transactional boundaries for a single operation
重试(Try Again Later)
将失败的操作放到一个 queue 或 logfile 里,稍后重试。对于一部分类型的应用来说这样 是可行的。
属于 最终一致性 (eventual consistency)。第 11 章会详细讨论。
全部回退(Abort The Entire Operation)
需要一个补偿事务(compensating transaction)执行回退操作。
如果补偿事务又失败了怎么办?
- 重试
- 直接报错,人工介入清理脏数据
- 有相应的后台进程或服务,定期清理脏数据
当只有两个步骤时,保持两个事务的原子性还算简单。但假如有三个、四个、五个步骤时呢 ?补偿事务方式显然将极其复杂,这时候就要用到分布式事务。
分布式事务
有一个中心的 transaction manager。跨服务编排事务。
最常见的 short-lived transaction 算法:两阶段提交(two-phase commit)。
- 投票(voting)阶段:每个参与方分别向事务管理员汇报它是否可以执行事务
- 提交(commit)阶段:如果所有参与方投票都是 yes,事务管理员就下达提交命令,参 与方开始执行事务
缺点:
- 依赖一个中心的 transaction manager 发号施令,transaction manager 出问题时整个 系统将无法执行事务操作
- 任何一个参与方无法应答 transaction manager 时,事务都会无法进行
- 参与方提交阶段失败: 两阶段提交算法假设每个参与方的提交阶段只会成功不会失败 , 但这个假设并不成立。这意味着这个算法在理论上不是 可靠的 (foolproof), 只能解决大部分场景(参与方提交成功的场景)
- 提交失败的情况:参与方会锁住资源无法释放,极大限制了系统的可扩展性
两阶段提交算法原理简单,实现复杂,因为可能导致失败的条件非常多,代码都得做相应处理。
建议:
- 能不用就不用
- 必须得用时,优先考虑找一个已有的实现,而不是自己写
到底怎么办呢?
分布式事务不可靠,补偿事务太复杂,那到底该怎么办呢?
面对这种问题时,首先考虑,是否真的需要保持分布式事务属性?能否用多个本地事务加最 终一致性代替?后者更容易构建和扩展。
如果真的是必须要保持事务属性,那建议:尽最大努力保持为单个事务,不要做事务拆分。
If you do encounter state that really, really wants to be kept consistent, do everything you can to avoid splitting it up in the first place. Try really hard. If you really need to go ahead with the split, think about moving from a purely technical view of the process (e.g., a database transaction) and actually create a concrete concept to represent the transaction itself.
报表(Reporting)
将位于一个或多个地方的数据集中到一起,生成报表。
模型 1:数据库复制
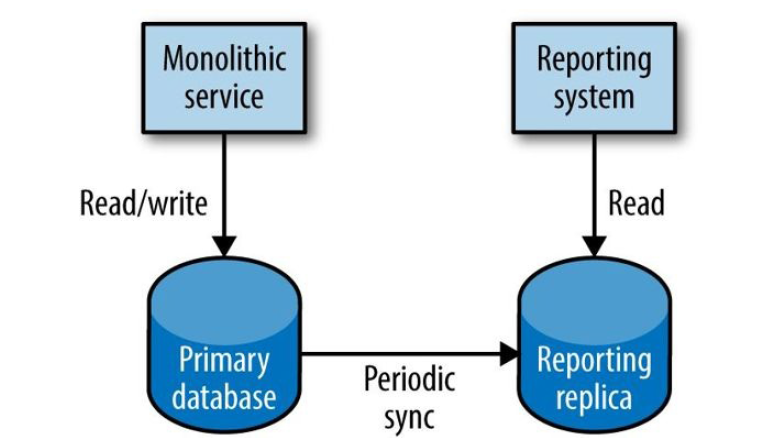
图 5-12 Standard read replication
典型的报表数据库是独立的,定期从主数据库同步。
优点:简单直接。
缺点:
- 主数据库的表结构共享给力报表系统,二者产生了耦合。主数据库的修改可能会 break 报表系统;而且,表结构修改阻力更大,因为对接的团队肯定不想总是跟着改
- 数据库优化手段会更受限:到底是该为主业务进行优化,还是该对报表系统进行优化, 二者可能是冲突的
- 报表系统和主业务绑定到了一种数据库,无法用到比较新的、可能更合适的数据库,例 如非关系型数据库
模型 2:Pull 模型
通过服务调用的方式主动去拉取所需的数据。
存在的问题:
- 服务方的 API 不是为报表系统设计的,取一份想要的数据得调用多次 API
- 取回来的数据量可能很大,而且还不能做缓存,因为原始数据可能会被修改,导致缓存 失效
- 数据量太大,API 太慢,解决方式:提供批量 API
批量 API 参考流程:
- 客户端调用批量 API
- 服务端返回 202:请求已接受,但还没开始处理
- 客户端轮询状态
- 服务端返回 201:已创建
Pull 模型的缺点:
- 请求量很大时,HTTP 头开销比较大
- 服务端可能还要专门为报表系统提供 API
模型 3:Push 模型
主动向报表系统推送数据。
一个单独的程序从数据源拉取数据,存储到报表系统的数据库。
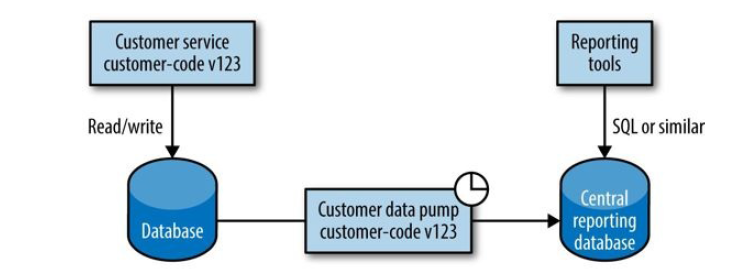
图 5-13 Using a data pump to periodically push data to a central reporting database
效果如下,每个模块也可有自己独立的报表数据库 schema:
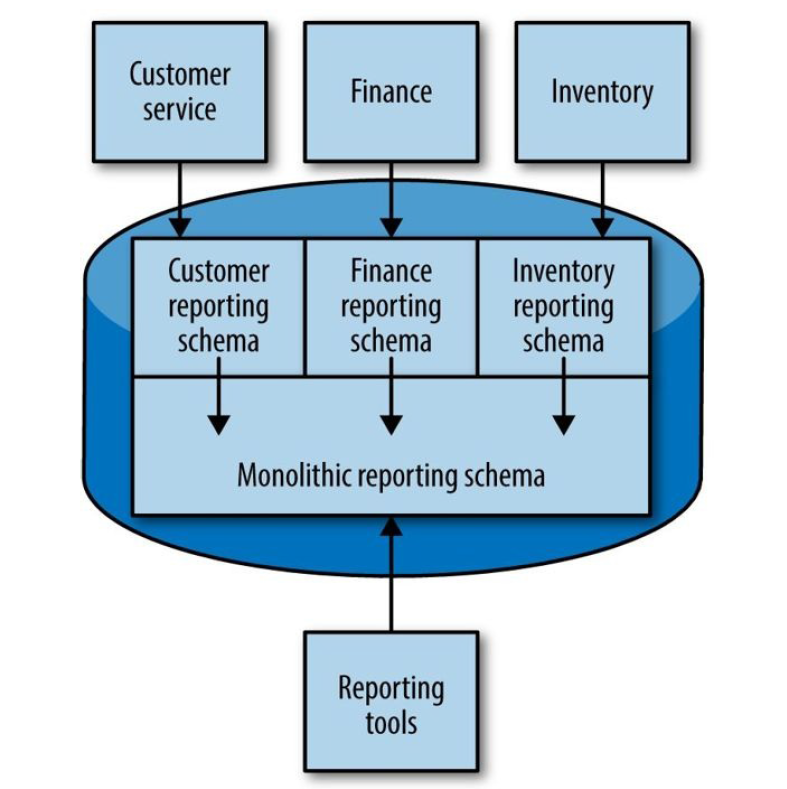
图 5-14 Utilizing materialized views to form a single monolithic reporting schema
模型 4:事件或消息队列模型

图 5-15 An event data pump using state change events to populate a reporting database
优点:
- 比定时同步的方式时效性更高
- 耦合更低
缺点:当数据量非常大时,效率没有基于数据库层的 push 模型高。
模型 5:备份数据模型
和数据库复制类似,但复制的是文件或其他元数据,存储在对象存储系统中,再用 Hadoop 之类的平台读取文件进行分析。适用于超大规模系统的报表。
实时性
不同类型的报表对实时性的要求是不同的。
6 部署(Deployment)
持续集成简史
With CI, the core goal is to keep everyone in sync with each other, which we achieve by making sure that newly checked-in code properly integrates with existing code. To do this, a CI server detects that the code has been committed, checks it out, and carries out some verification like making sure the code compiles and that tests pass.
持续发布

图 6-2 A standard release process modeled as a build pipeline
7 测试
8 监控
9 安全
10 康威定律和系统设计
Melvin Conway, 1968:
Any organization that designs a system will inevitably produce a design whose structure is a copy of the organization’s communication structure.
Eric S. Raymond, The New Hacker’s Dictionary (MIT Press):
If you have four groups working on a compiler, you’ll get a 4-pass compiler.
讽刺的是,康威的论文提交给《哈佛商业评论》的时候被拒了,理由是这个定理未经证明。
反面教材:Windows Vista
证明教材:Amazon 和 Netflix
Amazon 很早就意识到了每个团队负责自己的系统的整个生命周期的重要性。另外,它也意 识到小团队比大团队运转起来更加高效。
这产生了著名的 two-pizza team :如果一个团队两个披萨还吃不饱,那这个团队就该 拆分了。
Netflix 也是从一开始就规划为小的、独立的团队。
11 大规模微服务
服务降级
架构安全
避免系统雪崩,级联崩溃。
措施
- 超时
- 熔断
- bulkhead(防水仓),来自 Release It! 的概念,丢弃发生错误的部分,保持核 心功能的正常
- 隔离(isolation):及时隔离发生故障的下游应用,这样上游压力就会减轻
回源的系统,需要考虑到极端情况下全部 miss 时,所有请求都将打到源节点,是否会发生 雪崩。其中一种解决方式是:隐藏源站,miss 时直接返回 404,源站异步地将内容同步到 缓存。
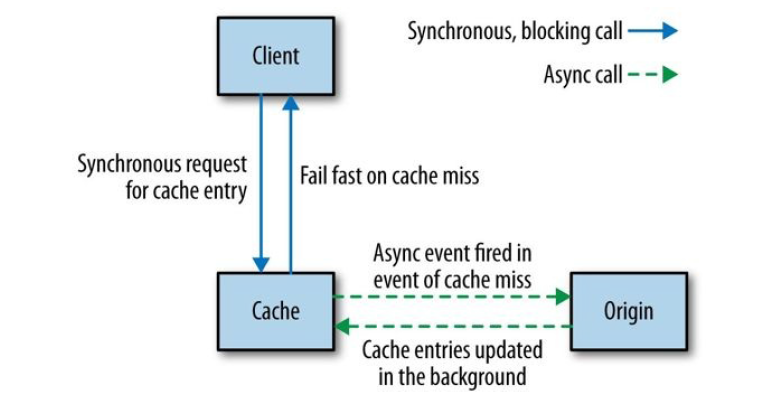
图 11-7 Hiding the origin from the client and populating the cache asynchronously
这种方式只对一部分系统有参考意义,但它至少能在下游发生故障的时候,保护自己不受影 响。
CAP 极简笔记
三句话:
- 三者无法同时满足
- 无 P 不成分布式系统
- 可选:CP 或 AP
12 总结
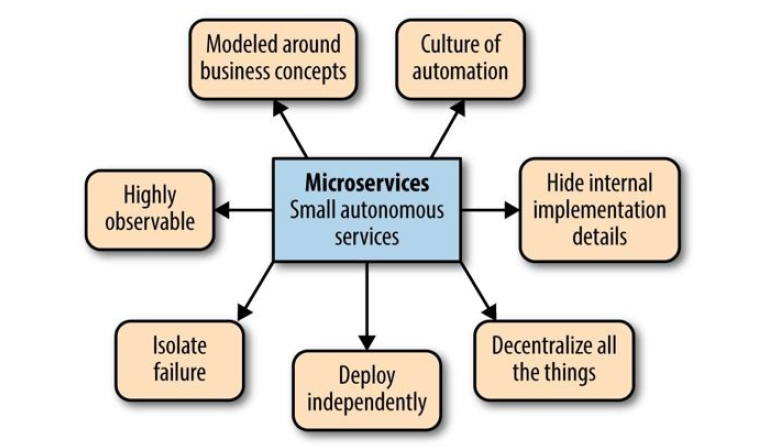
图 12-1 Principles of microservices
Change is inevitable. Embrace it.
正文到此结束
- 本文标签: 2015 数据库 Excel 十年 配置 锁 工程师 GitHub schema Hadoop 生命 git 微服务 DOM Service 压力 REST 分布式系统 IDE consumer 备份 bus 响应式 src db Architect tar XML IO 安全 开发 bug API 自适应 测试 struct 单元测试 解析 删除 Action 进程 软件 分布式 数据 rewrite Netflix 时间 lib 端口 Enterprise 分布式事务 NIO 功夫 操作系统 专注 SOA Developer 协议 ip 缓存 Cassandra http queue 线程 组织 id 开发者 性能问题 rmi 架构设计 需求 client windows 数据模型 js 部署 消息队列 cache cat dependencies 一致性 管理 Amazon 编译 邮件系统 索引 App DDL 线程池 教材 敏捷 服务端 UI 总结 虚拟化 本质 代码 build tab ACE https tag json ORM 产品 分页 模型 NSA 同步 服务器 自动化 架构师 CTO core
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐








相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

