【快学springboot】7.使用Spring Boot Jpa
Jpa (Java Persistence API) 是 Sun 官方提出的 Java 持久化规范。它为 Java 开发人员提供了一种对象/关联映射工具来管理 Java 应用中的关系数据。它的出现主要是为了简化现有的持久化开发工作和整合 ORM 技术。值得注意的是,JPA只是一套规范,不是具体的实现。Java很喜欢自己去定义规范,然后让厂商自己去实现,比如JMS等。
Spring Data JPA
Spring Data JPA是 Spring 基于 ORM(hibernate) 框架、Jpa 规范的基础上封装的一套 Jpa 应用框架,按照约定好的【方法命名规则】写数据库(DAO)层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
springboot整合JPA
- maven依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency> 复制代码
这里我引入了阿里巴巴的druid数据库连接池。
在application.properties配置数据库连接
spring.datasource.druid.url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai spring.datasource.druid.username=root spring.datasource.druid.password=123456 spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.type=com.alibaba.druid.pool.DruidDataSource 复制代码
这里基本是固定的写法了,不同的是,这里的数据库连接池我使用了阿里巴巴的连接池。
在application.properties配置spring data jpa一些信息
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect spring.jpa.hibernate.ddl-auto=update spring.jpa.show-sql=true 复制代码
spring.jpa.database-platform主要是指定生成表名的存储引擎为 InnoDBD
show-sql 是否打印出自动生成的 SQL,方便调试的时候查看
spring.jpa.hibernate.ddl-auto参数的作用主要用于:自动创建更新验证数据库表结构,有五个值
- create: 每次加载 hibernate 时都会删除上一次的生成的表,然后根据你的 model 类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。
- create-drop :每次加载 hibernate 时根据 model 类生成表,但是 sessionFactory 一关闭,表就自动删除。
- update:最常用的属性,第一次加载 hibernate 时根据 model 类会自动建立起表的结构(前提是先建立好数据库),以后加载 hibernate 时根据 model 类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。要注意的是当部署到服务器后,表结构是不会被马上建立起来的,是要等 应用第一次运行起来后才会。
- validate :每次加载 hibernate 时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。
- none:什么都不做
添加一个实体类UserEntity
@Entity
@Table(name = "user")
@Data
public class User {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Integer id;
@Column(name = "username", unique = true, nullable = true, length = 50)
private String username;
private String password;
}
复制代码
可以使用Column注解来定义一些数据库表结构的东西,如果不使用,会自动使用驼峰的命名规则映射默认值。
启动springboot项目,自动生成数据库表
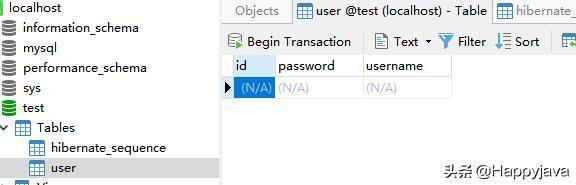
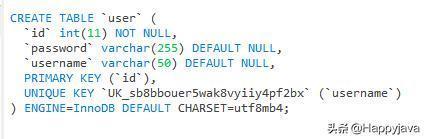
这里生成了User表,可以看下它的表结构:
这里还生成了一个hibernate_sequence表:
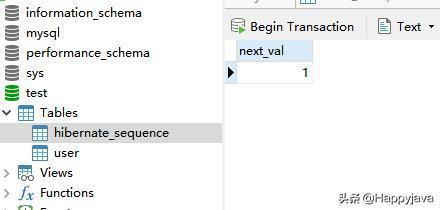
主要是因为我设置了主键的值策略为GenerationType.SEQUENCE,它是根据这个表来实现自增的。
添加一个UserRepo接口
public interface UserRepo extends PagingAndSortingRepository<User, Integer>, JpaSpecificationExecutor<User> {
}
复制代码
这里继承了PagingAndSortingRepository和JpaSpecificationExecutor两个接口,前者帮我们实现了CRUD、排序和分页等简单查询,后者是用来构造一些比较复杂的查询用的。
UserRepo默认给我们提供的方法
userRepo.findById(1); userRepo.findAll(); userRepo.findAll(PageRequest.of(0, 10)); userRepo.deleteById(1); User user = new User(); userRepo.save(user); 复制代码
这里是基础的CRUD的使用方法了。需要注意的是,修改实体的话,是根据save方法来判断的,如果save的实体是从数据库里查出来的,save的时候就是修改。
自定义查询方法
User findUserByUsername(String username); User findUserByUsernameAndPassword(String username,String password); 复制代码
spring data jpa有一套映射到sql查询的方法命名规则。整理如下:
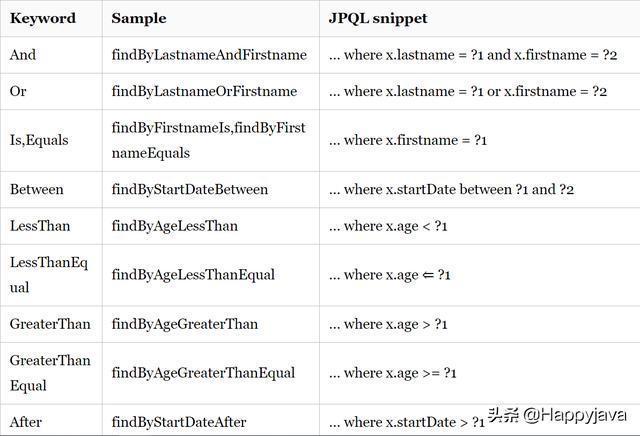

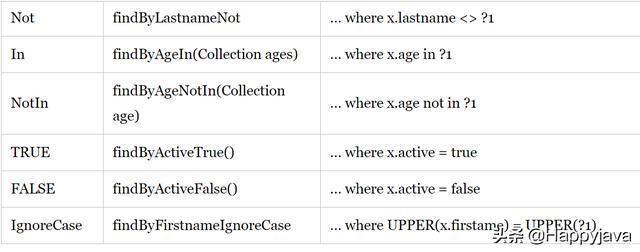
使用这些提供的查询方法,基本上可以应付我们需要的单表查询了。
分页查询
Page<User> findALL(Pageable pageable); Page<User> findByUserName(String userName,Pageable pageable); 复制代码
可以使用PageRequest.of(0, 10)来构建一个pageable。需要注意的是,这里分页从0开始。
自定义SQL查询
在UserRepo上,自定义方法。在 SQL 的方法上面使用@Query注解来写SQL,如涉及到删除和修改在需要加上@Modifying.也可以根据需要添加 @Transactional对事物的支持
@Transactional
@Modifying
@Query("update User u set u.username= ?1 where u.id = ?2")
int modifyByIdAndUserId(String username, Integer id);
@Transactional
@Modifying
@Query("delete from User where id = ?1")
void deleteByUserId(Long id);
复制代码
正文到此结束
- 本文标签: sql IO CTO 部署 src update find Persistence 数据 session 参数 删除 db 阿里巴巴 executor 代码 druid lib java JMS tar 调试 springboot 分页 http tab cat 自动生成 API JDBC MySQL5 spring JPA UI Spring Boot value DDL 服务器 数据库 ORM 管理 连接池 dataSource mysql ACE https 配置 id App entity root grep Action NSA 存储引擎 开发 Word maven
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

