聊聊微服务集群当中的自动化工具
本篇博客主要介绍了自动化工具这个概念,在微服务集群当中的作用,算抛砖引玉,欢迎大家提出自己的见解。
写在前面
在了解自动化工具的概念之前,我们先了解一下微服务和集群的概念。
什么是微服务
这个概念其实有些广泛,而我的知识广度也有限,我会尽量用通俗的语言来描述什么是微服务,什么是集群,以及为什么我们需要微服务集群 。为什么需要集群可以去看看 《小强开饭店-从单体应用到微服务》 ,这篇文章用非常通俗的语言和配图,通过一个漫画故事简单的解释了为什么我们需要微服务集群。
微服务
传统的后端服务多为单体应用,例如使用Sprint Boot或者Node又或者Gin搭建的简单的后端服务,在此基础之上,实现了基本的业务之后再部署到服务器上运行起来,这就成为了一个单体应用。
随着业务需求的增加、业务代码慢慢的累加,单体应用变的也越来越大。同时各个模块的大量业务代码相互纠缠在一起,开发以及维护变得尤其困难。想象一下一个刚刚加入项目的新人看到相互纠缠的、逻辑复杂的业务代码的绝望。

这个时候我们就需要了解微服务的概念了。如果想要讲这个庞大的单体应用可维护、可扩展以及高可用,我们就需要对单体应用按照模块进行业务拆分 。
例如将用户相关的所有逻辑单独搞成一个服务,又例如订单、库存可以搞成一个单独的服务。这样一来,业务代码被分散到几个单独的服务中,每个服务只需要关心、处理自己这个模块的业务逻辑。这样一来,业务代码的逻辑清晰,对开发人员来说,条理以及思路都很清晰。即使是后加入的项目开发人员,面对业务逻辑清晰的代码也十分容易上手。

微服务的拆分
其实我看到很多的文章关于微服务的介绍就基本到这了,但是还有个值得提的概念。首先,微服务怎么拆分其实是没有一个标准的。
你按照什么样的粒度去拆分你的服务其实是跟业务强相关的。并不是说一个服务的代码一定就很少,根据你的业务的量度,例如你的系统用户量特比的大,那么一个用户服务的代码量上千上万行我觉得都很正常。
当然我也见过用户不是很多,只是为了高可用和快速定位,而将系统拆分的非常细的系统,有好几十个服务。那么问题来了,有这么多服务,前端需要去维护的后端API的地址就相当的庞大了。
我们暂且先不讨论所有拆分的服务是否运行在同一个服务器上,就算是,那也得是不同的端口。前端也需要根据后端拆分的服务模块,去维护这样一张API的映射表。所以我们需要提出一个BFF,AKA Backend For Frontend.
BFF
其实BFF层最初被提出来,其实不是为了微服务拆分模块中提到的目的。其设计的目的是为了给不同的设备提供不同的API。例如一个系统的后端服务,同时需要支持不同的终端,例如移动端的iOS和Android,PC端。
这样一来,可以根据不同设备上的需求来提供对应的API,而且不需要更改我们现有的微服务。
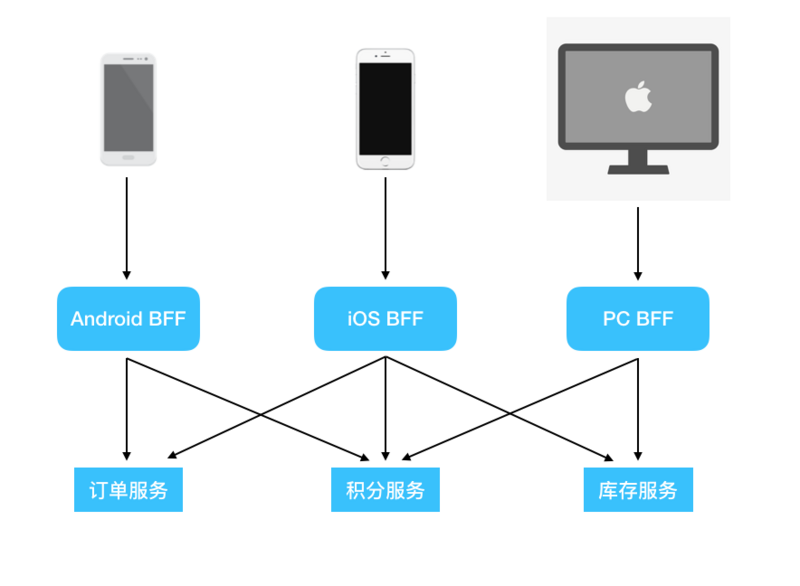
这样一来,我们的底层服务群就具有了很强的扩展性,我们不需要为一个新增的客户端来更改底层的服务代码,而是新增一层BFF层,来专门针对该终端类型去做适配。
大家从上面的图可以看出来,客户端都没有直接访问我们的底层服务。而是都先经过BFF层提供的接口,再由BFF层来根据不同的路由来调用不同的底层服务。总结一下,加了BFF层的优点如下。
- 扩展性强,可以适应不同的客户端
- 统一的API管理,客户端无须再维护API的映射表
- 可做集中鉴权,所有的请求都会先经过BFF,可在这一层对调用接口的合法性进行验证
当然,BFF也有缺点。
- 处理不当会有大量的代码冗余
- 因需要调用不同底层的服务而增大开发的工作量
当然在实际的生产环境下,我们也很少会将BFF层直接暴露给客户端。我们通常会在BFF层上再加一层网关。网关可以在请求还没有到BFF的时候,实现权限认证,限流熔断等等其他的功能。
集群
上面简单的聊了一下什么是微服务,现在我们来聊聊什么是集群。我们知道,当一个单体应用大的已经很难维护的时候,最好的办法就是将其拆分成微服务。这样有什么好处呢?
- 便于维护。每个微服务专注于自己这个模块的业务逻辑,不会存在各个模块的业务逻辑缠在一起的状况。
- 提高可用性。当单体应用挂掉的时候,我们系统的所有模块都将不可用。而拆分成微服务就可以尽量的避免这个问题。单个服务挂掉了,不会影响到其他服务的正常运行。
- 便于运维。单体应用重新部署的时候,会使整个系统不可用。而在微服务中,单个服务重新部署的代价明显要小的多。
概念
说了这么多,我们来给集群一个概念吧。集群就是将同一套服务部署在不同的服务器上,对外提供服务。
例子
我举个具体的例子。例如我们使用Docker Swarm来提供容器的集群服务。
在Docker Swarm中有节点这样一个概念,凡是运行了Docker的主机都可以主动的创建一个Swarm集群或者加入一个已经存在的集群,一旦加入,这个主机就成为了这个集群中的一个节点。在集群中节点分为两类,分别是管理节点(manager)和工作节点(worker)。我们可以用Portainer来管理Docker主机和Swarm集群。
我们以一个集群中的请求来举个例子。
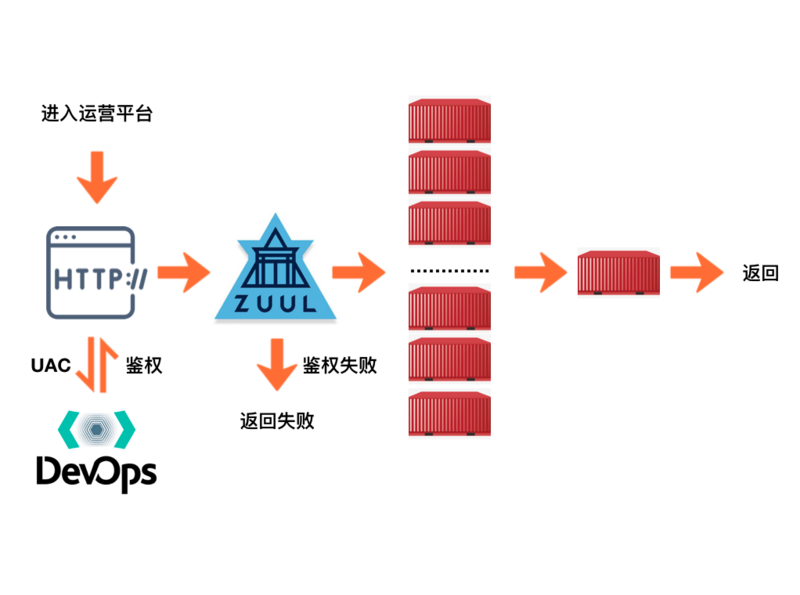
首先进入系统之后会先进入一个统一鉴权的系统去鉴权,鉴权成功之后就会到我们的微服务网关,如果这个地方还有系统自己的特殊鉴权的话,再次进行鉴权。之后网关这边会将我们的请求根据配置的路由来分发到具体的某个服务器上的某个容器中。
自动化工具
自动化工具的都包含了哪些技术呢?

其中的Java只是一个类比,代表你的编程语言。微服务中其实不是很关心具体用的什么语言,甚至每个服务都用不同的技术栈都行。
那么自动化工具是什么呢?其作用是什么?在集群中扮演了什么样的角色呢?我们通过一张图来简单的了解一下。
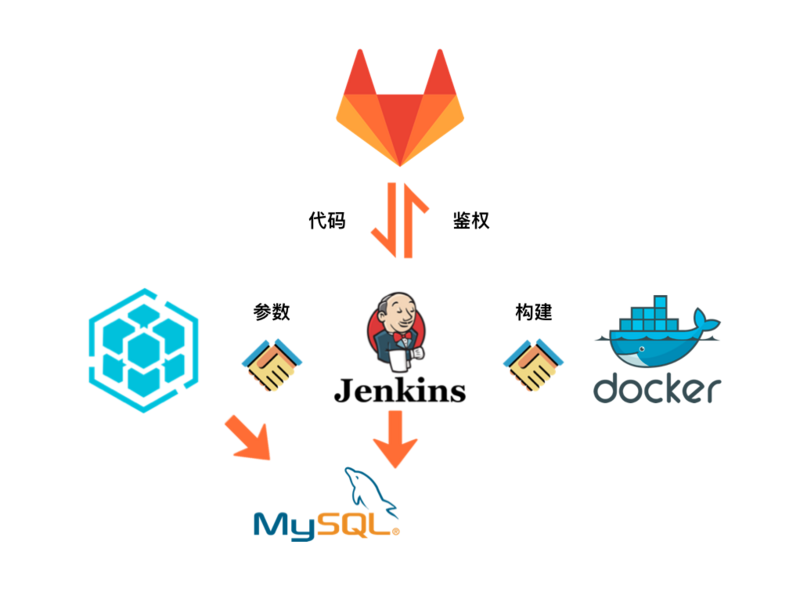
构建
简单的梳理一下逻辑。
- 首先自动化工具将Jenkins构建所需要的参数组织好,调用Jenkins的构建API,并记录构建操作到自动化工具的数据库
- 然后Jenkins用配置好的凭证去Gitlab的对应的项目的分支拉取代码,根据配置好的构建脚本开始构建,记录构建记录到自动化工具的数据库
- 构建好后再推送到docker的仓库中,并记录到自动化工具的数据库
到此构建的逻辑结束。
其他的功能
自动化工具还可以直接在项目列表中,选择查看当前项目的日志,而不需要每次重新打开Kibana然后再加筛选filter。
自动化工具的项目设置中,我们还可以更改docker容器的配置,而不需要再去portainer中或者通过命令行去修改;如果想要命令行进入容器,首先我们得找到对应的service,然后找到对应运行的service实例,然后才能进入,而如果我们直接使用portainer的Api,在endpoint已知的情况下,可以直接将这个功能做到自动化工具中,直接使用webshell一键连接。
其好处是什么呢?
- 对大部分开发屏蔽Swarm集群。对项目中非管理员的开发屏蔽Portainer,因为这个权限非常大,一旦不熟悉导致了误操作,那么有可能直接影响到线上的服务
- 统一权限控制。在自动化工具里做权限以及环境的统一控制
- 上手成本低。比起直接操作portainer和Jenkins和Kibana,自己搭建的自动化工具十分容易上手
功能总结
总结一下,其功能主要为以下几个。
- 构建
- 部署
- 回滚
- 查看elk日志
- 更改docker配置
- 管理集群的环境、项目和容器
- 命令行连接具体项目的容器
- …...
看到这大家可能会有疑问。

- 构建?你的意思是我Jenkins是摆设咯?
- 部署?更改 docker配置?命令行连接具体项目的容器?我的Iterm2也是个摆设?
- 回滚?等于是我之前的docker镜像的tag白打了?
- elk日志?我的Kibana是拿来看新闻的吗?
功能详解
构建
其实在构建这块,我个人认为自动化工具和Jenkins都很方便。而且自动化工具本身就是用的Jenkins,只不过是调用了Jenkins的API,传递了构建的参数,最终真正去构建的还是Jenkins。
只不过对于刚刚加入项目的测试来说,自己开发的Web UI对新人更加的友好,而且可以在自动化工具中做到权限控制。
部署和回滚
部署在自动化工具的后端通过docker-client实现。首先我们根据配置,创建docker client。然后如果已经有在运行的服务了,就调用update service更新服务,否则就创建服务。
回滚与其本质相同,只不过是用了之前的参数和不同的tag。
elk日志
首先,每个环境的配置中,会配置上kibana_host以及kibana_index,然后根据系统的projectKey,拼接成相应的Kibana日志的url,然后使用iframe嵌入到自动化工具中。这样一来就不用再手动的打开Kibana再去设置对应的filter了。特别是当你系统特别多的时候,添加和删除filter是很废时间的。
更新容器配置
这里也同样是调用对应的API更新对应服务的配置,而不用登录portainer去修改。
同时,在自动化工具中还可以针对不同的环境配置不同的Base Setting。后续在该环境下添加的应用不用再单独配置,直接继承环境的Docker Setting即可。
管理集群的环境、项目和容器
可以通过自动化工具统一的来创建和管理环境,同样有三种环境,研发、测试、生产环境。然后可以在自动化工具中创建角色和用户,分配给不同的角色不同的权限来达到控制权限的目的。
命令行连接具体项目的容器
通常我们因为某个需求,需要进入到容器中查看,然而此时我们就面临两种选择。
- 通过portainer进入对应service,找个某个具体的container,点击连接
- 命令行到容器具体运行的某个服务器上,然后再通过命令行连接
但是有了自动化工具,我们就有了第三种选择。
- 点击连接
怎么实现的呢?实际上就是通过endpointId去获取到所有的container的信息,然后遍历所有的container,找到与当前选中的containerId相同的容器,获取到其NodeName,这样一来我们就知道当前这个容器到底运行在哪个节点上的了。
然后通过已有的信息,构建WebSocket的url,最后前端通过xterm来建立ws连接,就这样直接连接了正在运行的容器实例。
总结
自动化工具只是一种思路,一种解决方案,它的好处在上面也列出了很多。当然,它肯定也有坏处,那就是需要专门投入人力和资源去开发。
这对于人手紧缺和项目周期较短的项目组来说,十分的不现实。但是如果一旦有精力和时间,我觉得值得一试。同时,基于portainer的API,我们还有可能将更多与集群相关的功能,集成到自动化工具上。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

