【深入浅出-VisualVM】(4): 分析CPU
有时候好好的程序放到生产服务器上一段时间后,就会发现服务器响应缓慢,进而进一步发现是cpu过高,于是就慌了,造成cpu过高的原因很多,不过大多是由于资源吃紧造成,例如:sql执行过慢,程序里存在死循环,数据库连接未释放,网络阻塞导致的第三方框架代码出现死循环,大量的操作导致死锁等,遇到此类问题不必紧张,coder君手把手教你克服心理障碍。
案例:死循环造成CPU过高
public class CpuTest {
public static void main(String[] args) throws InterruptedException {
loop();
endlessLoop();
}
public static void endlessLoop() throws InterruptedException {
while (true) {
System.out.println("hello world! loop!");
}
}
public static void loop(){
for (int i = 0; i < 10000; i++) {
System.out.println("hello world! endless loop!");
}
}
}
分析点击抽样器->CPU->查看CPU样例,发现endlessLoop()方法最耗CPU(这里有2个方法 loop和endlessLoop)

查看线程cpu耗时,发现main线程最耗时,点击增量,可以从此刻观察,cpu耗时的增长速率

查看线程dump,主要观察main线程,发现main线程当前状态下一直在执行 CpuTest.endlessLoop(CpuTest.java:14) ,这里可以定位问题位置,同时细心的童鞋可以观察看后面执行System.out.println(“”);方法是要先加锁的。
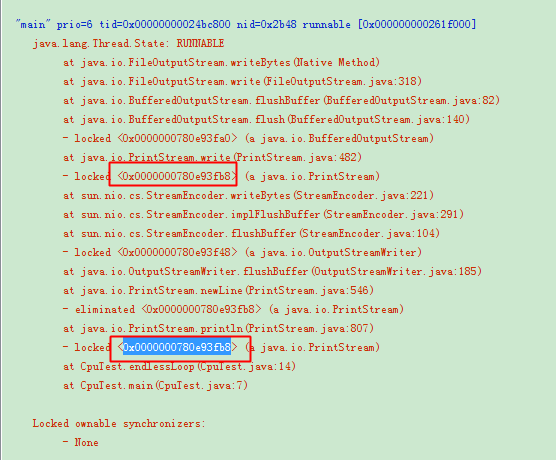
截图一段,我生产服务器(tomcat+springmvc)main线程的情况,其实只想说明web项目启动的main方法在中间件里。

补充
VisualVm只能定位JVM的cpu情况,但是生产主机上不光是Java程序,这时我们要采取另外的方案。
1.看监控数据是否正常,cpu,mem。
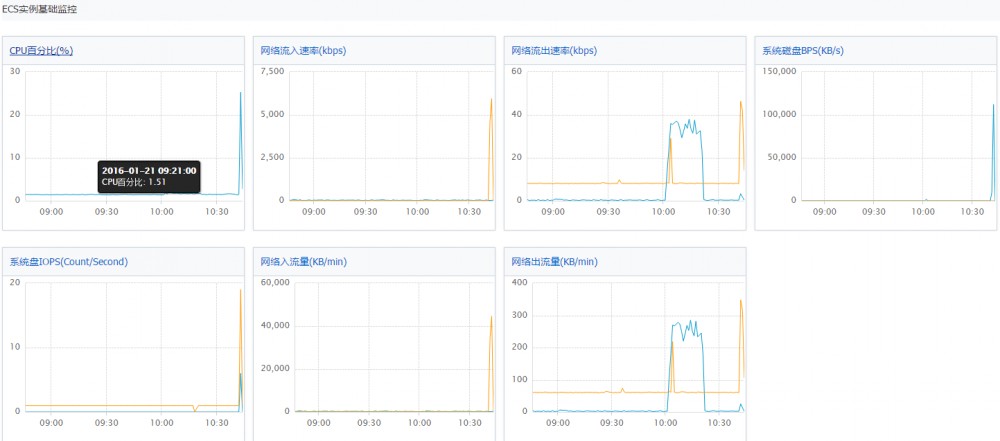
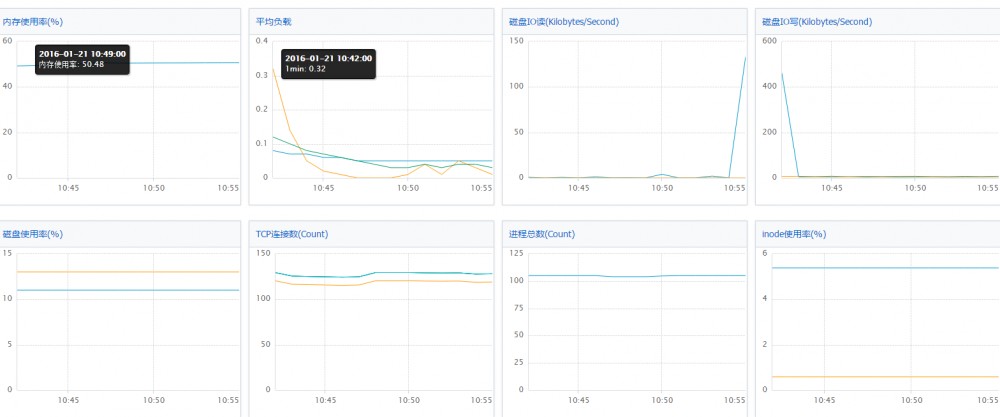
CPU占用1.5左右(100-98.0id) 内存占用50%(435/100*100%=43.5%) 阿里云监控内存大小转成实际占用内存大小,类似windows ,平均负载 0.1 差不多,其他几个参数,这里暂不介绍。
2.假设异常,找到异常的PID。
这里推荐 htop (清晰进程,线程, 命令行 ,排序支持鼠标双击,过滤,kill程序,标记某个线程或者进程,安装 apt-get install htop )
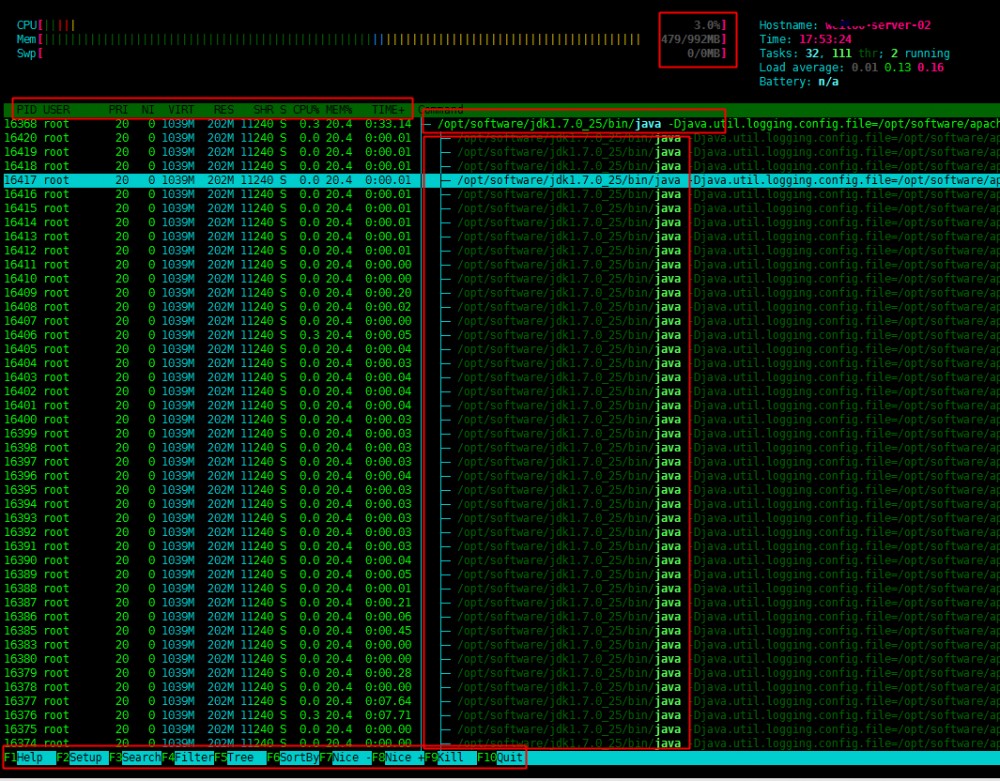
如果你没有服务器上安装软件的权限的话,就老老实实用 top 。通过 top 命令(默认3秒刷新,回车空格手动刷新, top -d 5 5秒刷新,也可以进入top后输入 d 设置刷新时间, top -p 4360 监控指定进程),然后按X ,默认按照CPU%排序,查看系统运行情况,如果想强制按CPU 降序,则输入大写P,如果强制按内存降序,则输入大写M(top命令是交互式的)。
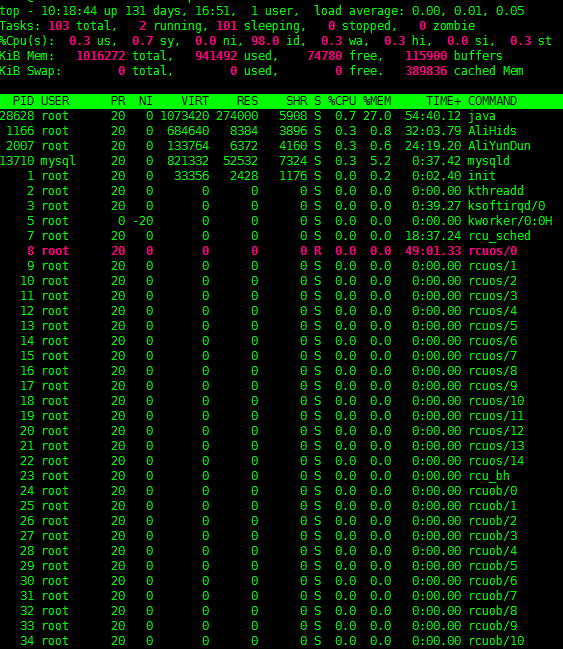
解读:
1).现在系统时间 10:18.44 ,系统一直运行了 131天16小时51分,当前有1个用户登录系统(相同账号也算不同用户),平均负载分别为0.00,0.01,0.05(分别为1分钟,5分钟,15分钟的负载情况,load average是每隔5秒钟检查一次活跃的进程数,用特定的算法得到的数值,然后除以逻辑CPU数量,如果负载持续大于cpu个数,则表明负载过高) 。大概可以看出系统负载很低,运行状态健康。
2).当前一共有103个 进程 ,处于运行的有2个,处于休眠状态的有101个,处于停止状态的有0个,处于僵尸状态的有0个。大概可以看出系统进程总数较少,环境比较单纯,运行中的进程不多。
3). 0.3 us 用户空间占用CPU 0.3%, 0.7 sy 内核占用CPU 0.7%, 0.0 ni 改变过优先级的进程占用CPU的百分比, 98.0 id 空闲CPU的百分比为98.0 , 0.3 wa IO等待所占用CPU的百分比为0.3, 0.3 hi 硬中断(Hardware IRQ)占用CPU的百分比为0.3(外设给CPU的异步信号(中断),例如:网卡收到数据包), 0.0 si 软中断占用cpu的百分比为0(软件本身给操作系统内核的中断信号,通常由硬中断处理程序对操作系统内核的中断), 0.3 st 虚拟机被hypervisor偷去CPU的时间。
4). KiB Mem 代表内存占用, 1016272 total 内存总的大小1g(以kb为单位), 941492 used 使用中的内存总量为0.9g, 74780 free 空闲内存总量为74m(吓一跳吧,才74M,这个不是实际剩余的内内存大小) , 115900 buffers 缓存的内存量为115m, 389836 cached cached大小380M。空闲内存总量只有74m,如果是windows去理解的话,此台服务器已经快挂了,实际内存大小等于74M+ buffers+cached = 580m(哈哈,够用,才占用一半呢), linux的内存管理和windows是不一样的,Linux会借用空闲的内存当作磁盘缓存, 磁盘数据缓存会让linux运行的更快,它永远不会从程序中拿出内存,它没有任何缺点,只是会混淆新手,如果你的应用程序需要更多的内存,他们会回收一部分用作磁盘数据缓存的物理内存,返回给应用程序,这个过程不需要启动交换,磁盘缓存(Disk caching)是不能禁用的, 但是可以释放磁盘缓存 1).只释放pagecache(文件缓存) echo 1 > /proc/sys/vm/drop_caches 2).释放dentries和inodes echo 2 > /proc/sys/vm/drop_caches 3).释放pagecache,dentries和inodes echo 3 > /proc/sys/vm/drop_caches
具体原理可以查看 linuxatemyram
我们利用 free 进一步证实上面的内容
 1).shared代表被线程共享的内存大小(大多数已经舍弃掉),buffer用来给块设备做缓存(记录文件系统的metadata和tracking in flight pages),cache缓存文件(第二次打开就很快),linux系统cached比较大,cached大小390m,buffers为110m。
1).shared代表被线程共享的内存大小(大多数已经舍弃掉),buffer用来给块设备做缓存(记录文件系统的metadata和tracking in flight pages),cache缓存文件(第二次打开就很快),linux系统cached比较大,cached大小390m,buffers为110m。
2).435288代表 -buffers/cache ( 应用程序实际使用330m内存 ) 580984 代表 +buffers/cache( 实际剩余内存大小580m )。
3).重要等式 total = used + free used(-buffers/cache) = used(Mem)-buffers(Mem)-cached(Mem) free(+buffers/cache) = free(Mem) + buffers(Mem) +cached(Mem) 。
4). free 命令的值是从 /proc/meminfo 文件里读到的。
5).Swap 交换区 总共大小 0 kb,已经使用0kb,释放了0Kb, 如果swap used > 0,则可以说明系统内存瓶颈了 。
6).内存总和 free -t 总和等于total(Mem) + total(Swap)。
7).一般常用命令 free -s 3 每3秒观察一次内存使用情况。
占用cpu最高的进程是java,PID为28628,USER进程所有者root,PR优先级20,NI为0(负值优先级高,正值优先级低,PR=NI+20) ,VIRT进程使用虚拟内存1G(java进程最高只能占用到1G),RES进程实际使用的物理内存270M(不包含swap和shared),SHR共享内存大小5M,S进程状态随眠状态(S睡眠,R运行,T停止或被跟踪,Z僵尸,D不可中断睡眠态),%CPU占用CPU 0.7%,%MEM占用内存27%,TIME+进程使用cpu的时间54分40.12秒。总体看java进程运行良好。
3.这里假设PID为16368的 进程 占用CPU比较高(因为做了多次实验,所以PID没办法和上面的28628保持一致),
先用 ps -ef | grep java ,也可以用 htop filter java,也可以 jps -v 找到 java的进程ID 16368(只能查看当前用户的java pid,不太建议使用,-v显示详细信息,也可以不加)


?代表终端设备未知,Sl代表休眠状态多线程
Linux通过进程查看线程的方法 1). htop 按t(显示进程线程嵌套关系)和H(显示线程) ,然后F4过滤进程名。2). ps -eLf | grep java (快照,带线程命令,e是显示全部进程,L是显示线程,f全格式输出) 3). pstree -p <pid> (显示进程树,不加pid显示所有) 4). top -Hp <pid> (实时) 5). ps -T -p <pid> (快照) 推荐程度按数字从小到大 。

4.利用 jstack 16368 > 2016-1-21.tdump (jstack是jdk自带的生成java stack和native stack的工具) 把threaddump输出到文件里,这里假设PID为16369(一般比进程号+1的是main线程,如果存在main线程貌似最先分配)的线程占用CPU最高,将其ID转成16进制0x3ff1(使用命令 printf "%x/n" 16369 输出3ff1)。
5.搜索threaddump文件,nid= 0x3ff1的线程堆栈,通过堆栈信息,就可以定位到占用CPU最高的代码地方(这里是正常的)。
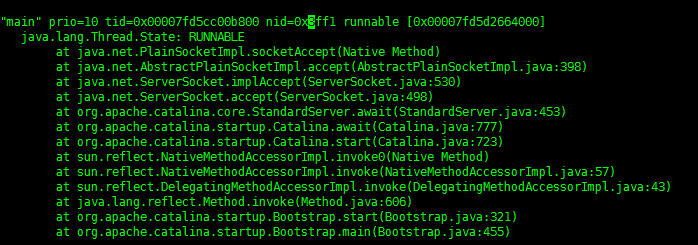
好啦,CPU冲高问题排查完毕,有了这样的知识体系,以后完全可以举一反三,coder君同时附上其他常用配合命令。
-
每隔一秒显示新生代,老年代,持久代垃圾回收情况
jstat -gcutil 16368 1000ms参考jstat -help,也可以查看远程主机的GC情况,需要远程主机开启jstatd服务。 -
观察堆内存情况
jmap -dump:format=b,file=2016-1-21.mdump 16368生成堆dump,放到mat或者vvm进行分析,上篇分析OOM有讲到。 -
查看jvm系统参数
jinfo 16368
正文到此结束
- 本文标签: SpringMVC 主机 IO ssl swap 安装 空间 进程数 数据缓存 缓存 服务器 map src cache JVM root js sql 时间 锁 SQL执行 id web https cat 代码 操作系统 ORM 物理内存 java 网卡 进程 多线程 参数 jstack 文件系统 spring tomcat 线程 管理 阿里云 CPU过高 虚拟内存 云 node 数据库 数据 软件 http 垃圾回收 linux windows grep UI
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

