JAVA中volatile介绍
在并发编程中谈及到的无非是可见性、有序性及原子性。而这里的 Volatile 只能够保证前两个性质,对于原子性还是不能保证的,只能通过锁的形式帮助他去解决原子性操作。
package com.montos.detail;
public class Singleton {
public static volatile Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (instance) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
复制代码
上面的代码是利用了单例模式里面的一个双重校验的写法,里面的实例变量中就是加上了 volatile 关键字,可能大家对于加不加这个关键字没啥感觉,因为去除这个关键字就可以保证多线程的情况下,外部能够拿到唯一的对象,还需要加上这个关键字干什么?。
双重校验的写法:第一次判断是否为 null 是为了拒绝掉当对象不为空的时候剩余的线程。里面加锁是为了当对象为 null 的时候,此时同时进来两个线程(A和B两个线程),我们要保证只有一个线程才可以初始化对象,所以在这里面加上了锁,这样A拿到了锁进去初始化对象,然后进行返回,B再进去此时发现不为 null ,那么就不执行初始化的过程。这样就能保证上面的单例模式的正常运行,同时为系统也是节约了许多开销(避免每个线程进来加锁--懒汉式写法等。。)
在理解上面的为什么不安全的情况下,我们首先要理解对象实例化的步骤:
- 分配内存空间。
- 初始化对象。
- 将内存空间的地址赋值给对应的引用。
上面是正常情况下,对象实例化的步骤,但是由于操作系统方面的原因。上面的第二步可能与第三步进行对换,如果发生这种情况,那么此时拿到的对象也只是一个引用,对于后面的业务操作可能存在错误的发生。
操作系统中指令重排问题:
一条的指令包括:
| 序号 | 指令 | 说明 |
|---|---|---|
| 1 | IF | 取值 |
| 2 | ID | 译码和取寄存器操作数 |
| 3 | EX | 执行或者有效地址计算 |
| 4 | MEM | 存储器访问 |
| 5 | WB | 写回 |
未进行指令重排的Demo:
a = b + c; d = e -f ;
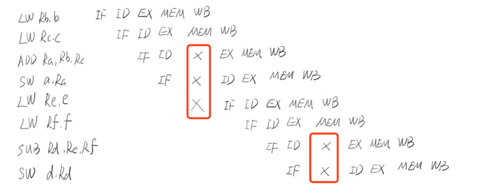
从上图可以看到有几个打x的地方,如果按照顺序执行的话,CPU是需要一个时钟周期来等待的,首先看第一个红色框的,第一个需要空出一个时钟周期是因为当前变量C还没有写入,此时是不可以进行两个值计算的,我们需要等待变量C的写入才可以进行执行两个数的求和,第二个空的时钟周期是因为当前一个时钟周期内,一个物理逻辑单位只能被一个指令执行,如果不空出一个时钟周期,那么就会与上面的 EX 起到冲突,第三个空档也是一样的道理。第二个红色框也是如此。
这上面就是如果计算机不进行指令重排的话,一个简单的计算,我们就可能浪费了5个时钟周期,即一条指令的从头到尾执行,所以计算机为了高效,就会对原来的指令进行重排,让 CPU 的资源能够得到很好的使用。
我们就将变量e的指令执行放在变量c之后,变量f的指令执行放在计算第一个表达式指令之后:
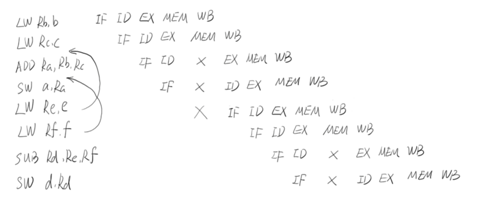
结果我们看到:
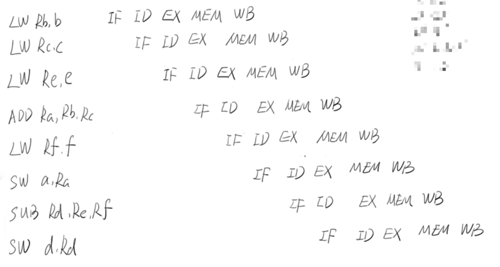
这个时候我们发现并没有浪费一个时钟周期,程序也达到了想要的计算效果,这就是计算机对于指令重排的一个优点,使得流水线更加的顺畅。
上面就说明了指令重排有时候对于程序执行是好的,但是有些情况下我们并不想发生这种情况,就是对象实例化的时候,我们就希望它能够按照顺序执行的方式执行下去。这个时候`volatile`就帮助了我们,它能够有效的防止指令重排。
Volatile有序性原理
volatile 之所以能够阻止指令重排,是因为底层 JVM 里面利用了内存屏障来实现的,内存屏障主要有三点功能:
- 它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
- 它会强制将对缓存的修改操作立即写入主存;
- 如果是写操作,它会导致其他CPU中对应的缓存行无效。
这里主要有四种类型的屏障操作:
(1)LoadLoad 屏障
执行顺序:Load1—>Loadload—>Load2
确保Load2及后续Load指令加载数据之前能访问到Load1加载的数据。
(2)StoreStore 屏障
执行顺序:Store1—>StoreStore—>Store2
确保Store2以及后续Store指令执行前,Store1操作的数据对其它处理器可见。
(3)LoadStore 屏障
执行顺序: Load1—>LoadStore—>Store2
确保Store2和后续Store指令执行前,可以访问到Load1加载的数据。
(4)StoreLoad 屏障
执行顺序: Store1—> StoreLoad—>Load2
确保Load2和后续的Load指令读取之前,Store1的数据对其他处理器是可见的。
通过上面内存屏障的限制,我们使用 volatile 就可以保证指令不会被操作系统进行重排。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

