Arthas线上实战:Dubbo线程池耗尽故障排查
上周末做了活动期间大量的限流告警提示。于是拜托运维大神先添加机器,暂时顶住压力。扩容一波增加了一些机器。然后,然后就看到了更多的接口响应超时告警。
2019-06-22 23:32:07,957 WARN [New I/O server worker #1-9] com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport:warn:54 [DUBBO] Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-172.***:62075, Pool Size: 200 (active: 200, core: 200, max: 200, largest: 200), Task: 771 (completed: 571), Executor status:(isShutdown:false, isTerminated:false, isTerminating:false), in dubbo://172.***:62075!, dubbo version: 2.5.3, current host: 172.16.6.3
Thread pool is EXHAUSTED!

问题排查
what ? 线程池耗尽。
1.客户端调用重试次数太多?
检查发现所有请求设置的重试次数都为0.
2.接口响应超时时间设置的过长?
单次请求超时时间3s.
3.是不是有线程阻塞?
打开 Arthas。
thread -b
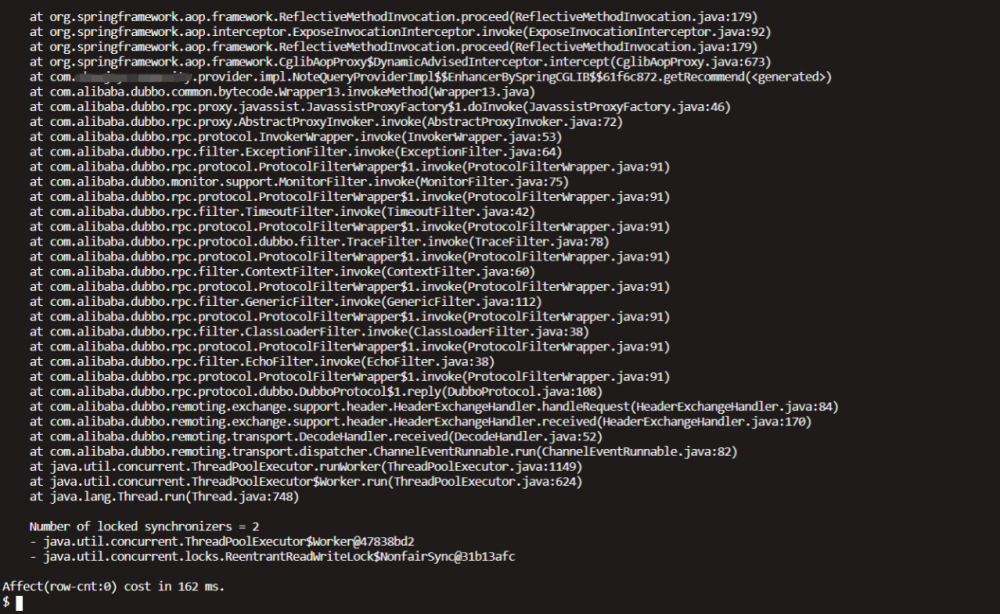
thread
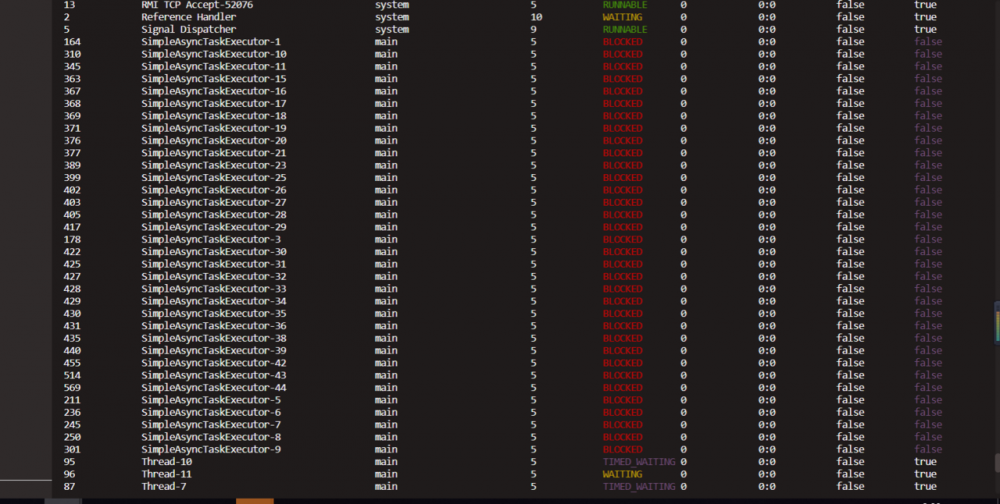
发现所有的SimpleAsyncTaskExecutor全部都是阻塞状态。那么它们在做什么呢?
插曲
运维重启了服务之后SimpleAsyncTaskExecutor 线程逐渐变成阻塞状态。(刚刚是全部为阻塞)


继续查看其中一个
thread 378
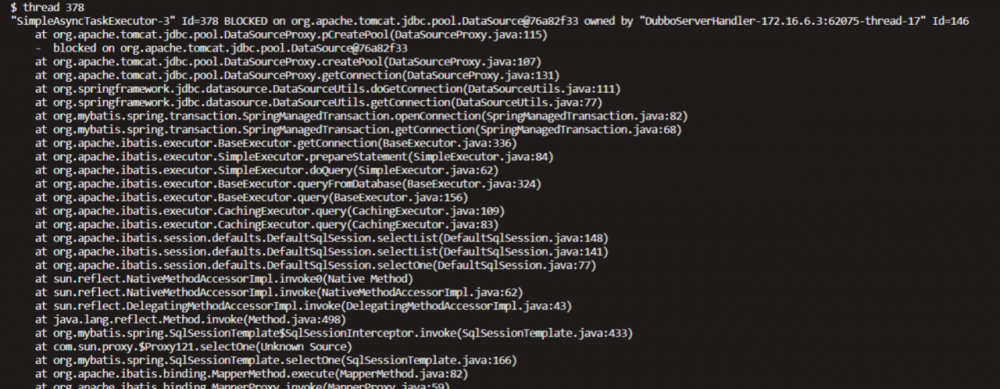
owned by DubboServerHandler 继续往下看
thread 146
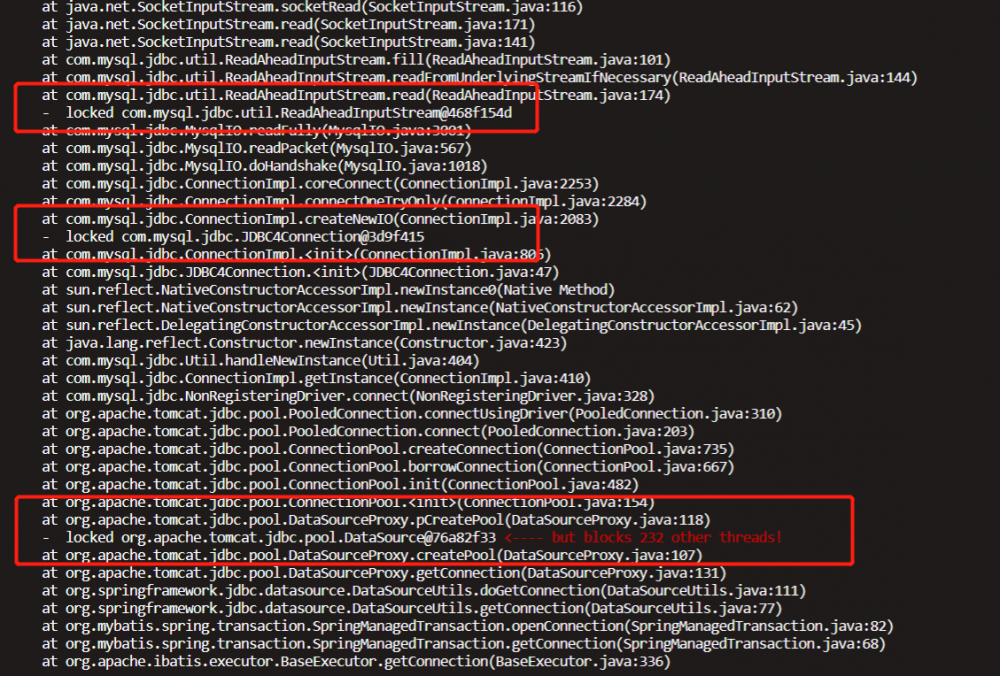
整理一下,目前的结论是并非死锁,是数据库查询这里出了异常。奇怪,如果数据库有问题别的同类 服务为什么没有告警?
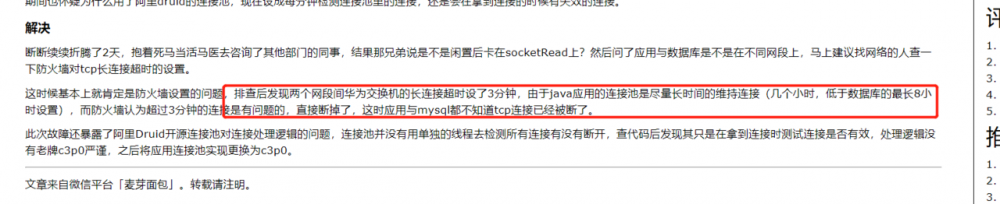
请运维大神排查,果然应用于数据库不在同一个网段,没有添加到ip白名单。
结论
扩容忽略了数据库链接。设置白名单问题修复。
思考
按照上面的排查看是与数据库连接出了问题,那这些跟Dubbo的dispatcher策略有没有关系呢? 网上搜索到了解决方案:(没有验证) 修改dubbo provider的dispatcher策略,设置为message
<dubbo:protocol name=“dubbo” port=“8888” threads=“500” dispatcher=“message” />
dispatcher默认为all,所有的请求,均会分发给业务线程池处理。 dubbo默认的业务线程池大小是200,等待队列长度为0, 当线程池全部满了之后,后续的请求会丢弃。 但丢弃的请求也会交给业务线程池处理, 此时可能出现服务端已拒绝,但consumer一直在等待,直到超时
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

