SpringBoot+Lucene案例介绍
SpringBoot+Lucene案例介绍
一、案例介绍
- 模拟一个商品的站内搜索系统(类似淘宝的站内搜索);
- 商品详情保存在mysql数据库的product表中,使用mybatis框架;
- 站内查询使用Lucene创建索引,进行全文检索;
- 增、删、改,商品需要对Lucene索引修改,搜索也要达到近实时的效果。
对于数据库的操作和配置就不在本文中体现,主要讲解与Lucene的整合。
一、引入lucene的依赖
向pom文件中引入依赖
<!--核心包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.6.0</version>
</dependency>
<!--对分词索引查询解析-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.6.0</version>
</dependency>
<!--一般分词器,适用于英文分词-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.6.0</version>
</dependency>
<!--检索关键字高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>7.6.0</version>
</dependency>
<!-- smartcn中文分词器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>7.6.0</version>
</dependency>
三、配置初始化Bean类
初始化bean类需要知道的几点:
1.实例化 IndexWriter,IndexSearcher 都需要去加载索引文件夹,实例化是是非常消耗资源的,所以我们希望只实例化一次交给spring管理。
2.IndexSearcher 我们一般通过SearcherManager管理,因为IndexSearcher 如果初始化的时候加载了索引文件夹,那么
后面添加、删除、修改的索引都不能通过IndexSearcher 查出来,因为它没有与索引库实时同步,只是第一次有加载。
3.ControlledRealTimeReopenThread创建一个守护线程,如果没有主线程这个也会消失,这个线程作用就是定期更新让SearchManager管理的search能获得最新的索引库,下面是每25S执行一次。
5.要注意引入的lucene版本,不同的版本用法也不同,许多api都有改变。
@Configuration
public class LuceneConfig {
/**
* lucene索引,存放位置
*/
private static final String LUCENEINDEXPATH="lucene/indexDir/";
/**
* 创建一个 Analyzer 实例
*
* @return
*/
@Bean
public Analyzer analyzer() {
return new SmartChineseAnalyzer();
}
/**
* 索引位置
*
* @return
* @throws IOException
*/
@Bean
public Directory directory() throws IOException {
Path path = Paths.get(LUCENEINDEXPATH);
File file = path.toFile();
if(!file.exists()) {
//如果文件夹不存在,则创建
file.mkdirs();
}
return FSDirectory.open(path);
}
/**
* 创建indexWriter
*
* @param directory
* @param analyzer
* @return
* @throws IOException
*/
@Bean
public IndexWriter indexWriter(Directory directory, Analyzer analyzer) throws IOException {
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 清空索引
indexWriter.deleteAll();
indexWriter.commit();
return indexWriter;
}
/**
* SearcherManager管理
*
* @param directory
* @return
* @throws IOException
*/
@Bean
public SearcherManager searcherManager(Directory directory, IndexWriter indexWriter) throws IOException {
SearcherManager searcherManager = new SearcherManager(indexWriter, false, false, new SearcherFactory());
ControlledRealTimeReopenThread cRTReopenThead = new ControlledRealTimeReopenThread(indexWriter, searcherManager,
5.0, 0.025);
cRTReopenThead.setDaemon(true);
//线程名称
cRTReopenThead.setName("更新IndexReader线程");
// 开启线程
cRTReopenThead.start();
return searcherManager;
}
}
四、创建需要的Bean类
创建商品Bean
/**
* 商品bean类
* @author yizl
*
*/
public class Product {
/**
* 商品id
*/
private int id;
/**
* 商品名称
*/
private String name;
/**
* 商品类型
*/
private String category;
/**
* 商品价格
*/
private float price;
/**
* 商品产地
*/
private String place;
/**
* 商品条形码
*/
private String code;
......
创建一个带参数查询分页通用类PageQuery类
/**
* 带参数查询分页类
* @author yizl
*
* @param <T>
*/
public class PageQuery<T> {
private PageInfo pageInfo;
/**
* 排序字段
*/
private Sort sort;
/**
* 查询参数类
*/
private T params;
/**
* 返回结果集
*/
private List<T> results;
/**
* 不在T类中的参数
*/
private Map<String, String> queryParam;
......
五、创建索引库
1.项目启动后执行同步数据库方法
项目启动后,更新索引库中所有的索引。
/**
* 项目启动后,立即执行
* @author yizl
*
*/
@Component
@Order(value = 1)
public class ProductRunner implements ApplicationRunner {
@Autowired
private ILuceneService service;
@Override
public void run(ApplicationArguments arg0) throws Exception {
/**
* 启动后将同步Product表,并创建index
*/
service.synProductCreatIndex();
}
}
2.从数据库中查询出所有的商品
从数据库中查找出所有的商品
@Override
public void synProductCreatIndex() throws IOException {
// 获取所有的productList
List<Product> allProduct = mapper.getAllProduct();
// 再插入productList
luceneDao.createProductIndex(allProduct);
}
3.创建这些商品的索引
把List中的商品创建索引
我们知道,mysql对每个字段都定义了字段类型,然后根据类型保存相应的值。
那么lucene的存储对象是以document为存储单元,对象中相关的属性值则存放到Field(域)中;
Field类的常用类型 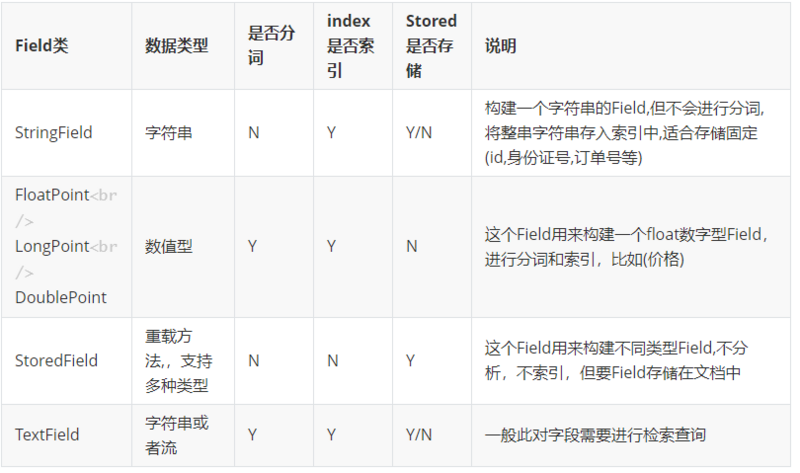
上面是一些常用的数据类型, 6.0后的版本,数值型建立索引的字段都更改为Point结尾,FloatPoint,LongPoint,DoublePoint等,对于浮点型的docvalue是对应的DocValuesField,整型为NumericDocValuesField,FloatDocValuesField等都为NumericDocValuesField的实现类。
commit()的用法
commit()方法,indexWriter.addDocuments(docs);只是将文档放在内存中,并没有放入索引库,没有commit()的文档,我从索引库中是查询不出来的;
许多博客代码中,都没有进行commit(),但仍然能查出来,因为每次插入,他都把IndexWriter关闭.close(),Lucene关闭前,都会把在内存的文档,提交到索引库中,索引能查出来,在spring中IndexWriter是单例的,不关闭,所以每次对索引都更改时,都需要进行commit()操作;
这样设计的目的,和数据库的事务类似,可以进行回滚,调用rollback()方法进行回滚。
@Autowired
private IndexWriter indexWriter;
@Override
public void createProductIndex(List<Product> productList) throws IOException {
List<Document> docs = new ArrayList<Document>();
for (Product p : productList) {
Document doc = new Document();
doc.add(new StringField("id", p.getId()+"", Field.Store.YES));
doc.add(new TextField("name", p.getName(), Field.Store.YES));
doc.add(new StringField("category", p.getCategory(), Field.Store.YES));
// 保存price,
float price = p.getPrice();
// 建立倒排索引
doc.add(new FloatPoint("price", price));
// 正排索引用于排序、聚合
doc.add(new FloatDocValuesField("price", price));
// 存储到索引库
doc.add(new StoredField("price", price));
doc.add(new TextField("place", p.getPlace(), Field.Store.YES));
doc.add(new StringField("code", p.getCode(), Field.Store.YES));
docs.add(doc);
}
indexWriter.addDocuments(docs);
indexWriter.commit();
}
六、多条件查询
按条件查询,分页查询都在下面代码中体现出来了,有什么不明白的可以单独查询资料,下面的匹配查询已经比较复杂了.
searcherManager.maybeRefresh()方法,刷新searcherManager中的searcher,获取到最新的IndexSearcher。
@Autowired
private Analyzer analyzer;
@Autowired
private SearcherManager searcherManager;
@Override
public PageQuery<Product> searchProduct(PageQuery<Product> pageQuery) throws IOException, ParseException {
searcherManager.maybeRefresh();
IndexSearcher indexSearcher = searcherManager.acquire();
Product params = pageQuery.getParams();
Map<String, String> queryParam = pageQuery.getQueryParam();
Builder builder = new BooleanQuery.Builder();
Sort sort = new Sort();
// 排序规则
com.infinova.yimall.entity.Sort sort1 = pageQuery.getSort();
if (sort1 != null && sort1.getOrder() != null) {
if ("ASC".equals((sort1.getOrder()).toUpperCase())) {
sort.setSort(new SortField(sort1.getField(), SortField.Type.FLOAT, false));
} else if ("DESC".equals((sort1.getOrder()).toUpperCase())) {
sort.setSort(new SortField(sort1.getField(), SortField.Type.FLOAT, true));
}
}
// 模糊匹配,匹配词
String keyStr = queryParam.get("searchKeyStr");
if (keyStr != null) {
// 输入空格,不进行模糊查询
if (!"".equals(keyStr.replaceAll(" ", ""))) {
builder.add(new QueryParser("name", analyzer).parse(keyStr), Occur.MUST);
}
}
// 精确查询
if (params.getCategory() != null) {
builder.add(new TermQuery(new Term("category", params.getCategory())), Occur.MUST);
}
if (queryParam.get("lowerPrice") != null && queryParam.get("upperPrice") != null) {
// 价格范围查询
builder.add(FloatPoint.newRangeQuery("price", Float.parseFloat(queryParam.get("lowerPrice")),
Float.parseFloat(queryParam.get("upperPrice"))), Occur.MUST);
}
PageInfo pageInfo = pageQuery.getPageInfo();
TopDocs topDocs = indexSearcher.search(builder.build(), pageInfo.getPageNum() * pageInfo.getPageSize(), sort);
pageInfo.setTotal(topDocs.totalHits);
ScoreDoc[] hits = topDocs.scoreDocs;
List<Product> pList = new ArrayList<Product>();
for (int i = 0; i < hits.length; i++) {
Document doc = indexSearcher.doc(hits[i].doc);
System.out.println(doc.toString());
Product product = new Product();
product.setId(Integer.parseInt(doc.get("id")));
product.setName(doc.get("name"));
product.setCategory(doc.get("category"));
product.setPlace(doc.get("place"));
product.setPrice(Float.parseFloat(doc.get("price")));
product.setCode(doc.get("code"));
pList.add(product);
}
pageQuery.setResults(pList);
return pageQuery;
}
七、删除更新索引
@Override
public void deleteProductIndexById(String id) throws IOException {
indexWriter.deleteDocuments(new Term("id",id));
indexWriter.commit();
}
八、补全Spring中剩余代码
Controller层
@RestController
@RequestMapping("/product/search")
public class ProductSearchController {
@Autowired
private ILuceneService service;
/**
*
* @param pageQuery
* @return
* @throws ParseException
* @throws IOException
*/
@PostMapping("/searchProduct")
private ResultBean<PageQuery<Product>> searchProduct(@RequestBody PageQuery<Product> pageQuery) throws IOException, ParseException {
PageQuery<Product> pageResult= service.searchProduct(pageQuery);
return ResultUtil.success(pageResult);
}
}
public class ResultUtil<T> {
public static <T> ResultBean<T> success(T t){
ResultEnum successEnum = ResultEnum.SUCCESS;
return new ResultBean<T>(successEnum.getCode(),successEnum.getMsg(),t);
}
public static <T> ResultBean<T> success(){
return success(null);
}
public static <T> ResultBean<T> error(ResultEnum Enum){
ResultBean<T> result = new ResultBean<T>();
result.setCode(Enum.getCode());
result.setMsg(Enum.getMsg());
result.setData(null);
return result;
}
}
public class ResultBean<T> implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 返回code
*/
private int code;
/**
* 返回message
*/
private String msg;
/**
* 返回值
*/
private T data;
...
public enum ResultEnum {
UNKNOW_ERROR(-1, "未知错误"),
SUCCESS(0, "成功"),
PASSWORD_ERROR(10001, "用户名或密码错误"),
PARAMETER_ERROR(10002, "参数错误");
/**
* 返回code
*/
private Integer code;
/**
* 返回message
*/
private String msg;
ResultEnum(Integer code, String msg) {
this.code = code;
this.msg = msg;
}
正文到此结束
- 本文标签: CTO list src ACE id https map 代码 value build Word 希望 category pom sql API key 同步 博客 MQ zab apache expat 管理 实例 final 删除 IO equals spring cat IDE Document 参数 http mapper ArrayList mysql 线程 数据 parse 分页 core bean 索引 数据库 UI 解析 mybatis entity Service Mysql数据库 tar 配置 App REST 中文分词 message springboot
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

