详解全链路监控架构--目标、功能模块、Dapper和方案比较
概述
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题。

全链路监控组件就在这样的问题背景下产生了。最出名的是谷歌公开的论文提到的 Google Dapper。想要在这个上下文中理解分布式系统的行为,就需要监控那些横跨了不同的应用、不同的服务器之间的关联动作。
分布式服务调用链路
在复杂的微服务架构系统中,几乎每一个前端请求都会形成一个复杂的分布式服务调用链路。一个请求完整调用链可能如下图所示:
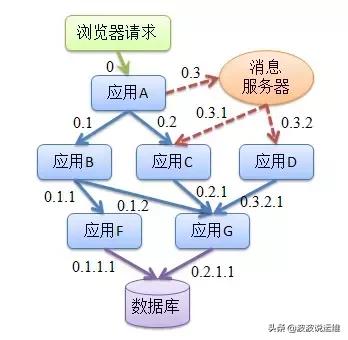
一个请求完整调用链
那么在业务规模不断增大、服务不断增多以及频繁变更的情况下,面对复杂的调用链路就带来一系列问题:
- 如何快速发现问题?
- 如何判断故障影响范围?
- 如何梳理服务依赖以及依赖的合理性?
- 如何分析链路性能问题以及实时容量规划?
同时需要关注在请求处理期间各个调用的各项性能指标,比如:吞吐量(TPS)、响应时间及错误记录等。
- 吞吐量,根据拓扑可计算相应组件、平台、物理设备的实时吞吐量。
- 响应时间,包括整体调用的响应时间和各个服务的响应时间等。
- 错误记录,根据服务返回统计单位时间异常次数。
全链路性能监控 从整体维度到局部维度展示各项指标,将跨应用的所有调用链性能信息集中展现,可方便度量整体和局部性能,并且方便找到故障产生的源头,生产上可极大缩短故障排除时间。
有了全链路监控工具,能够达到:
- 请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
- 可视化: 各个阶段耗时,进行性能分析。
- 依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化。
- 数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。
1、全链路监控目标
如上所述,那么我们选择全链路监控组件有哪些目标要求呢?Google Dapper中也提到了,总结如下:
1.探针的性能消耗
2.APM组件服务的影响应该做到足够小。
服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径。在一些高度优化过的服务,即使一点点损耗也会很容易察觉到,而且有可能迫使在线服务的部署团队不得不将跟踪系统关停。
3.代码的侵入性
4.即也作为业务组件,应当尽可能少入侵或者无入侵其他业务系统,对于使用方透明,减少开发人员的负担。
5.对于应用的程序员来说,是不需要知道有跟踪系统这回事的。
如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统也太脆弱了,往往由于跟踪系统在应用中植入代码的bug或疏忽导致应用出问题,这样才是无法满足对跟踪系统“无所不在的部署”这个需求。
6.可扩展性
7.一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性。能够支持的组件越多当然越好。
或者提供便捷的插件开发API,对于一些没有监控到的组件,应用开发者也可以自行扩展。
8.数据的分析
9.数据的分析要快 ,分析的维度尽可能多。
跟踪系统能提供足够快的信息反馈,就可以对生产环境下的异常状况做出快速反应。分析的全面,能够避免二次开发。
2、全链路监控功能模块
一般的全链路监控系统,大致可分为四大功能模块:
1.埋点与生成日志
埋点即系统在当前节点的上下文信息,可以分为 客户端埋点、服务端埋点,以及客户端和服务端双向型埋点。埋点日志通常要包含以下内容traceId、spanId、调用的开始时间,协议类型、调用方ip和端口,请求的服务名、调用耗时,调用结果,异常信息等,同时预留可扩展字段,为下一步扩展做准备;
2.收集和存储日志
主要支持分布式日志采集的方案,同时增加MQ作为缓冲;
每个机器上有一个 deamon 做日志收集,业务进程把自己的Trace发到daemon,daemon把收集Trace往上一级发送;
多级的collector,类似pub/sub架构,可以负载均衡;
对聚合的数据进行 实时分析和离线存储;
离线分析 需要将同一条调用链的日志汇总在一起;
3.分析和统计调用链路数据,以及时效性
调用链跟踪分析:把同一TraceID的Span收集起来,按时间排序就是timeline。把ParentID串起来就是调用栈。
抛异常或者超时,在日志里打印TraceID。利用TraceID查询调用链情况,定位问题。
依赖度量:
- 强依赖:调用失败会直接中断主流程
- 高度依赖:一次链路中调用某个依赖的几率高
- 频繁依赖:一次链路调用同一个依赖的次数多
离线分析:按TraceID汇总,通过Span的ID和ParentID还原调用关系,分析链路形态。
实时分析:对单条日志直接分析,不做汇总,重组。得到当前QPS,延迟。
4.展现以及决策支持
3、Google Dapper
3.1 Span
基本工作单元,一次链路调用(可以是RPC,DB等没有特定的限制)创建一个span,通过一个64位ID标识它,uuid较为方便,span中还有其他的数据,例如描述信息,时间戳,key-value对的(Annotation)tag信息,parent_id等,其中parent-id可以表示span调用链路来源。
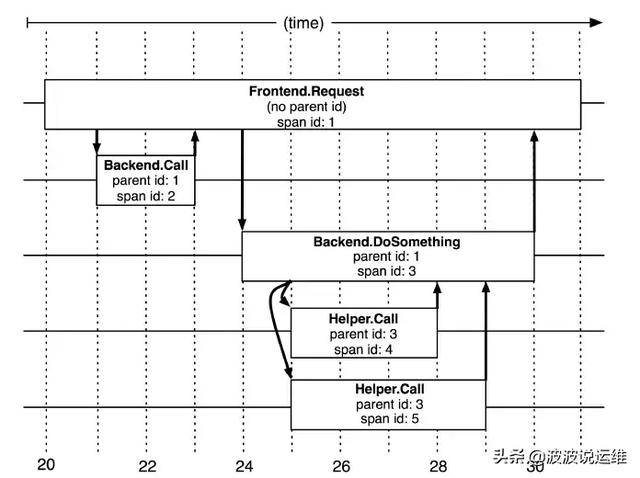
Span
上图说明了span在一次大的跟踪过程中是什么样的。Dapper记录了span名称,以及每个span的ID和父ID,以重建在一次追踪过程中不同span之间的关系。如果一个span没有父ID被称为root span。所有span都挂在一个特定的跟踪上,也共用一个跟踪id。
3.2 TRACE
类似于 树结构的Span集合,表示一次完整的跟踪,从请求到服务器开始,服务器返回response结束,跟踪每次rpc调用的耗时,存在唯一标识trace_id。比如:你运行的分布式大数据存储一次Trace就由你的一次请求组成。
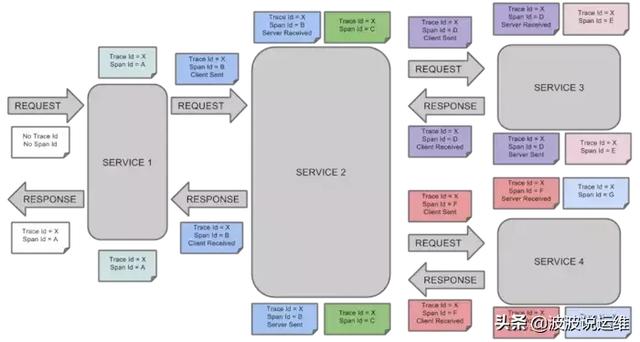
Trace
每种颜色的note标注了一个span,一条链路通过TraceId唯一标识,Span标识发起的请求信息。树节点是整个架构的基本单元,而每一个节点又是对span的引用。节点之间的连线表示的span和它的父span直接的关系。虽然span在日志文件中只是简单的代表span的开始和结束时间,他们在整个树形结构中却是相对独立的。
3.3 Annotation
注解,用来记录请求特定事件相关信息(例如时间),一个span中会有多个annotation注解描述。通常包含四个注解信息:
(1) cs:Client Start,表示客户端发起请求
(2) sr:Server Receive,表示服务端收到请求
(3) ss:Server Send,表示服务端完成处理,并将结果发送给客户端
(4) cr:Client Received,表示客户端获取到服务端返回信息
4、 方案比较
市面上的全链路监控理论模型大多都是借鉴Google Dapper论文,主要是以下三种APM组件:
Zipkin:由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。
Pinpoint:一款对Java编写的大规模分布式系统的APM工具,由韩国人开源的分布式跟踪组件。
Skywalking:国产的优秀APM组件,是一个对JAVA分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统。
相比之下,Pinpoint 具有压倒性的优势:无需对项目代码进行任何改动就可以部署探针、追踪数据细粒化到方法调用级别、功能强大的用户界面以及几乎比较全面的 Java 框架支持。
正文到此结束
- 本文标签: 端口 互联网 Google value 开源 Twitter 模型 插件开发 进程 API key 性能问题 ACE 分布式系统 2019 协议 tar 大数据 程序员 总结 http zipkin 部署 服务器 数据 App 开发 统计 分布式 tag root 负载均衡 开发者 CTO 快的 src id 微服务 探针 https UI 时间 软件 client 服务端 pinpoint zip ip 配置 需求 插件 Developer MQ QPS java db 集群 代码 谷歌 IO bug
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

