服务发现及NetflixEureka
| 编辑推荐: |
| 本文来自于segmentfault.com,文章主要介绍了 |
问题
CAP满足哪几部分
failover方式是怎样
语言机制
服务发现梳理
Open-Source Service Discovery
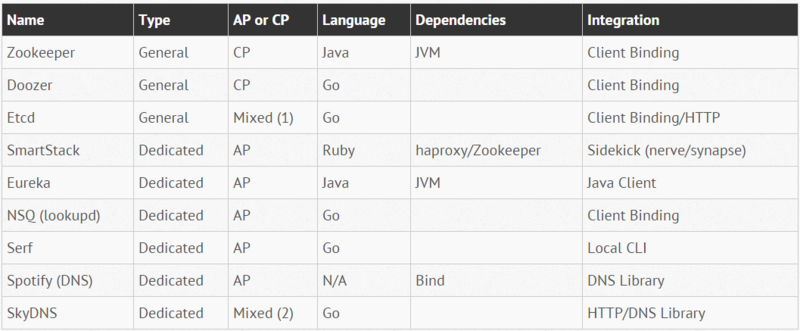
zk方案-对后端系统规模上升的一些思考
DNS
最原始的配置文件和 DNS 来做服务发现,Host、端口都是写在配置文件里的,发生变更的时候只能修改配置文件并重启服务。所以当某台机器挂掉的时候,依赖它上面服务的其他系统也都全部会出问题。而应急的步骤都是先在别的机器上运行新的实例,修改配置文件并重启关联的其他系统。这样做费时、费力、且会有一个时间窗口内系统无法提供服务。
通过 Nginx 来做了负载均衡/主备的
这样做还是有两个问题:(1)Nginx 本身成为一个故障点(2)连接数量翻倍,其中第二个问题曾导致我们的环境出现了 nf_conntrack table full 的问题。我们的关键服务都是多实例负载均衡的,当系统并发上升到一定程度的时候,某些服务器,尤其是跑着 Nginx 的机器很容易出现这个错误。
zk
服务实例注册的 Node 类型是 ephemeral node,这种类型的节点只有在客户端保持着连接的时候才有效。所以当某个服务实例被停止或者出现网络异常的时候,对应的节点也会被删掉。因此,任何时候从 ZooKeeper 里查询到的都是当前活跃的实例。借助 ZooKeeper 的推送功能,服务的消费者可以得知实例的变化,从而可以从容应对服务实例的宕机和新实例的添加,无需重启。
SmartStack: Airbnb的自动服务发现和注册框架
DNS 变更延迟问题
中心化负载均衡,单点问题
zk,多语言问题
SmartStack,在zookeeper和haproxy上封装一层
服务发现:etcd vs Consul vs Zookeeper
etcd(coreos开发,系统级别的)
etcd是一个采用HTTP协议的健/值对存储系统,它是一个分布式和功能层次配置系统,可用于构建服务发现系统。其很容易部署、安装和使用,提供了可靠的数据持久化特性。它是安全的并且文档也十分齐全。etcd比Zookeeper是比更好的选择,因为它很简单,然而,它需要搭配一些第三方工具才可以提供服务发现功能。
consul(go语言写的)
Consul是强一致性的数据存储,使用gossip形成动态集群。它提供分级键/值存储方式,不仅可以存储数据,而且可以用于注册器件事各种任务,从发送数据改变通知到运行健康检查和自定义命令,具体如何取决于它们的输出。与Zookeeper和etcd不一样,Consul内嵌实现了服务发现系统,所以这样就不需要构建自己的系统或使用第三方系统。这一发现系统除了上述提到的特性之外,还包括节点健康检查和运行在其上的服务。Zookeeper和etcd只提供原始的键/值队存储,要求应用程序开发人员构建他们自己的系统提供服务发现功能。而Consul提供了一个内置的服务发现的框架。客户只需要注册服务并通过DNS或HTTP接口执行服务发现。其他两个工具需要一个亲手制作的解决方案或借助于第三方工具。Consul为多种数据中心提供了开箱即用的原生支持,其中的gossip系统不仅可以工作在同一集群内部的各个节点,而且还可以跨数据中心工作。
Netflix的Eureka方案
github文档
spring-cloud-netflix文档 (里头有peer部署部分)
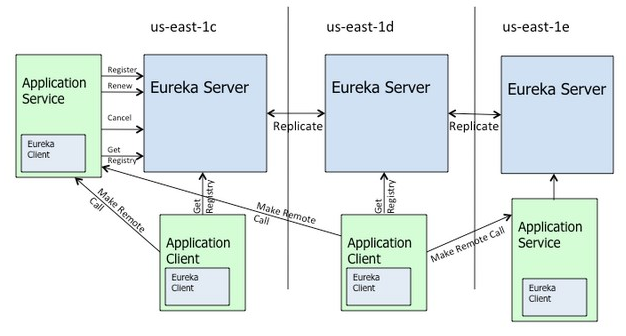
Eureka 由两个组件组成: Eureka 服务器 和 Eureka 客户端 。Eureka 服务器用作服务注册服务器。Eureka 客户端是一个 java 客户端,用来简化与服务器的交互、作为轮询负载均衡器,并提供服务的故障切换支持。Netflix 在其生产环境中使用的是另外的客户端,它提供基于流量、资源利用率以及出错状态的加权负载均衡。
当一个中间层服务首次启动时,他会将自己注册到 Eureka 中,以便让客户端找到它,同时每 30 秒发送一次心跳。如果一个服务在几分钟内没有发送心跳,它将从所有 Eureka 节点上注销。一个 Amazon 域中可以有一个 Eureka 节点集群,每个可用区(Availability Zone)至少有一个 Eureka 节点。AWS 的域相互之间是隔离的。
为什么不应该使用ZooKeeper做服务发现
zk是满足CP牺牲A,这个不对,看ZooKeeper和CAP理论及一致性原则 ,其实zk只是满足最终一致性C,可用性A这个是保证的,并且保证一半的节点是最新的数据,分区性P这个得看节点多少及读写情况,节点多,则写耗时长,另外节点多了Leader选举非常耗时, 就会放大网络的问题,容易分区。
对于Service发现服务而言,宁可返回某服务5分钟之前在哪几个服务器上可用的信息,也不能因为暂时的网络故障而找不到可用的服务器,而不返回任何结果。所以说,用ZooKeeper来做Service发现服务是肯定错误的。总结一句就是,service不是强一致的,所以会有部分情况下没发现新服务导致请求出错。当部分或者所有节点跟ZooKeeper断开的情况下,每个节点还可以从本地缓存中获取到数据;但是,即便如此,ZooKeeper下所有节点不可能保证任何时候都能缓存所有的服务注册信息。如果ZooKeeper下所有节点都断开了,或者集群中出现了网络分割的故障(注:由于交换机故障导致交换机底下的子网间不能互访);那么ZooKeeper会将它们都从自己管理范围中剔除出去,外界就不能访问到这些节点了,即便这些节点本身是“健康”的,可以正常提供服务的;所以导致到达这些节点的服务请求被丢失了。
Eureka处理网络问题导致分区。如果Eureka服务节点在短时间里丢失了大量的心跳连接(注:可能发生了网络故障),那么这个Eureka节点会进入”自我保护模式“,同时保留那些“心跳死亡“的服务注册信息不过期。此时,这个Eureka节点对于新的服务还能提供注册服务,对于”死亡“的仍然保留,以防还有客户端向其发起请求。当网络故障恢复后,这个Eureka节点会退出”自我保护模式“。所以Eureka的哲学是,同时保留”好数据“与”坏数据“总比丢掉任何”好数据“要更好,所以这种模式在实践中非常有效。
Eureka就是为发现服务所设计的,它有独立的客户端程序库,同时提供心跳服务、服务健康监测、自动发布服务与自动刷新缓存的功能。但是,如果使用ZooKeeper你必须自己来实现这些功能。
Eureka一致性分析
Eureka: How do I disable/configure peer replication?
通过配置eureka.serviceUrl.defaultZone来进行复制eureka.client.serviceUrl.defaultZone=http://<peer1host>:<peer1port&g...
How to config multiple Eureka Servers from client in Spring Cloud
貌似是根据配置的url的前后顺序来复制的
/**
* Replicates all eureka actions to peer eureka nodes except for replication
* traffic to this node.
*
*/
private void replicateToPeers(Action action, String appName, String id,
InstanceInfo info /* optional */,
InstanceStatus newStatus /* optional */, boolean isReplication) {
Stopwatch tracer = action.getTimer().start();
try {
if (isReplication) {
numberOfReplicationsLastMin.increment();
}
// If it is a replication already, do not replicate again as this
// will create a poison replication
if (peerEurekaNodes == Collections.EMPTY_LIST || isReplication) {
return;
}
for (final PeerEurekaNode node : peerEurekaNodes.get()) {
// If the url represents this host, do not replicate
// to yourself.
if (isThisMe(node.getServiceUrl())) {
continue;
}
replicateInstanceActionsToPeers(action, appName, id, info,
newStatus, node);
}
} finally {
tracer.stop();
}
}
触发的时机相当于热备:每增删改一次,就同步一次。然后默认是走url的第一个来查的,然后
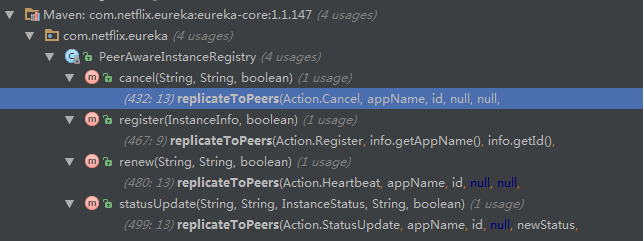
调用的时候,第一个挂了,自动去找第二,详见
/**
* Makes remote calls with the corresponding action(register,renew etc).
*
* @param action
* the action to be performed on eureka server.
* @return ClientResponse the HTTP response object.
* @throws Throwable
* on any error.
*/
private ClientResponse makeRemoteCall(Action action) throws Throwable {
return makeRemoteCall(action, 0);
}
具体内部catch异常后,递归调用
/**
* Makes remote calls with the corresponding action(register,renew etc).
*
* @param action
* the action to be performed on eureka server.
*
* Try the fallback servers in case of problems communicating to
* the primary one.
*
* @return ClientResponse the HTTP response object.
* @throws Throwable
* on any error.
*/
private ClientResponse makeRemoteCall(Action action, int serviceUrlIndex)
throws Throwable {
String urlPath = null;
Stopwatch tracer = null;
String serviceUrl = eurekaServiceUrls.get().get(serviceUrlIndex);
ClientResponse response = null;
logger.debug("Discovery Client talking to the server {}", serviceUrl);
try {
// If the application is unknown do not register/renew/cancel but
// refresh
if ((UNKNOWN.equals(instanceInfo.getAppName())
&& (!Action.Refresh.equals(action)) && (!Action.Refresh_Delta
.equals(action)))) {
return null;
}
WebResource r = discoveryApacheClient.resource(serviceUrl);
String remoteRegionsToFetchStr;
switch (action) {
case Renew:
tracer = RENEW_TIMER.start();
urlPath = "apps/" + appPathIdentifier;
response = r
.path(urlPath)
.queryParam("status",
instanceInfo.getStatus().toString())
.queryParam("lastDirtyTimestamp",
instanceInfo.getLastDirtyTimestamp().toString())
.put(ClientResponse.class);
break;
case Refresh:
tracer = REFRESH_TIMER.start();
final String vipAddress = clientConfig.getRegistryRefreshSingleVipAddress();
urlPath = vipAddress == null ? "apps/" : "vips/" + vipAddress;
remoteRegionsToFetchStr = remoteRegionsToFetch.get();
if (!Strings.isNullOrEmpty(remoteRegionsToFetchStr)) {
urlPath += "?regions=" + remoteRegionsToFetchStr;
}
response = getUrl(serviceUrl + urlPath);
break;
case Refresh_Delta:
tracer = REFRESH_DELTA_TIMER.start();
urlPath = "apps/delta";
remoteRegionsToFetchStr = remoteRegionsToFetch.get();
if (!Strings.isNullOrEmpty(remoteRegionsToFetchStr)) {
urlPath += "?regions=" + remoteRegionsToFetchStr;
}
response = getUrl(serviceUrl + urlPath);
break;
case Register:
tracer = REGISTER_TIMER.start();
urlPath = "apps/" + instanceInfo.getAppName();
response = r.path(urlPath)
.type(MediaType.APPLICATION_JSON_TYPE)
.post(ClientResponse.class, instanceInfo);
break;
case Cancel:
tracer = CANCEL_TIMER.start();
urlPath = "apps/" + appPathIdentifier;
response = r.path(urlPath).delete(ClientResponse.class);
// Return without during de-registration if it is not registered
// already and if we get a 404
if ((!isRegisteredWithDiscovery)
&& (response.getStatus() == Status.NOT_FOUND
.getStatusCode())) {
return response;
}
break;
}
if (logger.isDebugEnabled()) {
logger.debug("Finished a call to service url {} and url path {} with status code {}.",
new String[] {serviceUrl, urlPath, String.valueOf(response.getStatus())});
}
if (isOk(action, response.getStatus())) {
return response;
} else {
logger.warn("Action: " + action + " => returned status of "
+ response.getStatus() + " from " + serviceUrl
+ urlPath);
throw new RuntimeException("Bad status: "
+ response.getStatus());
}
} catch (Throwable t) {
closeResponse(response);
String msg = "Can't get a response from " + serviceUrl + urlPath;
if (eurekaServiceUrls.get().size() > (++serviceUrlIndex)) {
logger.warn(msg, t);
logger.warn("Trying backup: "
+ eurekaServiceUrls.get().get(serviceUrlIndex));
SERVER_RETRY_COUNTER.increment();
return makeRemoteCall(action, serviceUrlIndex);
} else {
ALL_SERVER_FAILURE_COUNT.increment();
logger.error(
msg
+ "/nCan't contact any eureka nodes - possibly a security group issue?",
t);
throw t;
}
} finally {
if (tracer != null) {
tracer.stop();
}
}
}
正文到此结束
- 本文标签: 递归 ip 总结 集群 Security IDE MQ 协议 value equals DNS src 安装 ORM App bug java 并发 node final cat 文章 数据 Haproxy 服务器 Collections consul js client zookeeper Service 时间 一致性 spring retry remote 开发 tar ACE UI HTTP协议 json 服务注册 Nginx 2019 https Amazon 安全 Action GitHub 分布式 端口 Eureka 缓存 http Region Collection 实例 Netflix web 部署 git 同步 apr Go语言 管理 id tab list Proxy 负载均衡 core 配置 IO URLs Spring cloud apache
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

