大型互联网系统云原生微服务架构,亿级海量数据治理实践
 本文转载自公众号IT168企业级(ID:IT168qiye)
本文转载自公众号IT168企业级(ID:IT168qiye)
黄哲铿,前1号店高级技术总监、海尔农业电商 CTO、 1药网技术VP ,畅销书《技术管理之巅》作者,“技术领导力社区”发起人,擅长大型电商系统研发、供应链系统研发、大型技术团队治理,个人拥有多项技术发明和专利。
本文根据黄哲铿老师在DTCC数据库大会分享内容整理而成,将进行每日亿级增量数据的实时读写、复杂查询场景实践介绍,涉及 MySQL 分表分库策略、数据异构、TiDB 使用和优化、微服务架构等等。
首先做下自我介绍,我叫黄哲铿,之前在互联网的一些企业,像1号店、1药网,担任技术开发以及技术管理等职位。 同时,我在2015年的时候出版过一本技术治理方面的书《技术管理之巅》。
本次分享将由以下几个部分组成:
-
多租户SAAS系统场景简介
-
系统面临的挑战
-
亿级数据实时读写的系统架构
-
不足及展望
1
多租户SAAS系统场景简介

首先介绍一下多租户SaaS系统的应用场景,案例中的系统是给快递末端网点做管理系统。 结算每天的派费、收入以及其他费用等等。 那这个系统的使用量大概是多少? 全国范围内有大概几万的网点,同时在线的人数大概有数万人左右,每天的结算数据时单表的行数增量大概会达到亿级别的增量(假设不分表分库)。
同时,应用中会有实时读写,大量的复杂的SQL分页查询。 在座很多做金融系统或来自银行的朋友们应该很清楚,结算系统或者说金融系统对数据的实时性、一致性的要求非常高。 用户的使用习惯是把明细数据导出来,比如说每天可能有几十万甚至百万的数据要去用Excel导出来,这里面其实会有很多工程方面的优化,以及SQL方面的一些优化。
2
系统面临的挑战

接下来是我们面临的一些挑战,大家有做结算系统或财务方面的朋友应该知道,用户对自己账户里的钱是非常敏感的,比如有很多人排队去把OFO账户中的钱兑现,其实没多少钱,但大家觉得这个是我的钱,我要随时、马上看到,拿到。 在结算系统中也一样的道理,这个数据我改了马上就能够在系统里面得到反映。 一般的小系统很好实现,但是如果每天有上亿增量数据的系统,这其实是个比较大的挑战。
刚才我们提到应用场景所面临的一些挑战和对系统的挑战,包括亿级增量的结算和数据的存储,单表肯定是放不下的,自然而然会想到去分表、分库。 那按照什么样的逻辑去分? 这又是一个问题,我们接下来会讲。
应用场景刚才也介绍过了,结算系统对一致性、实时性、可用性都有非常高的要求,我们的应用部署的规模大概有几百个应用实例,部署在系统上。 那几百个实例对数据库本身就是一个很大的压力。 假设说有两百个应用,每个应用有三十个数据库的链接,那就是有六千个链接,对吗? 所以,这对整个系统的压力、架构方式都是非常大的挑战,以及我们的结算系统要求这种高可用,99.9%、99.99%之类的要求。
我们的数据主要来源于消费,消费的数据需要做实时的处理,虽然他是跑批的,用分布式job来跑。 但是在跑批的过程中,单个业务逻辑的处理的业务复杂度其实是非常高的。 单个业务逻辑算一条账单、一条费用时,可能会涉及到十几、二十个逻辑规则。 那这些数据是实时去抽,做一些预处理,放在缓存里面,但是在数据量大的时候,缓存可能又不一定是非常好的一个解决方案。 这就是我们遇到的一些问题。
其实大家可以想想看,以电商系统为例,电商系统其实只是在下订单的环节才有这样的一个应用场景。 在下订单的时候要扣积分,扣库存等等,那个时候需要用实时数据去计算,对系统我压力比较大。
那我们的结算场景的复杂度相当于什么? 相当于有五万多个用户同时在下单。 国内可能也没有几家电商公司能够达到这样的数量。 那么这个系统它的难度,它的挑战在什么地方呢?
3
亿级数据实时读写的系统架构
所以接下来介绍的是我们如何架构一个这样的系统去应对刚才我们所面临的这些挑战。
1、云原生微服务架构
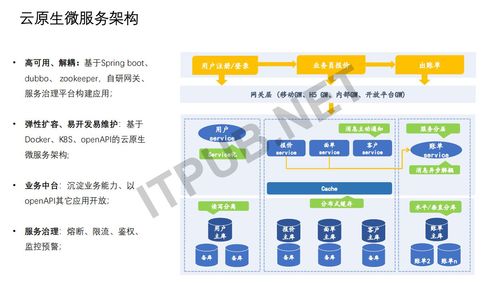
首先我们采用的是云原生的微服务架构,微服务架构的好处其实大家应该都很清楚。 就是它的解耦性、横向可扩、团队之间的独立性以及沉淀的业务逻辑等等。
其实微服务也带来了一些问题,最明显的一个问题是什么? 原本一个团队开发一个中台,那我现在按照业务线去拆,比如说你是用户组,右边的这张图就是用户下单的场景,从左到右注册、下订单、结算等等。 那竖着来看,按照业务逻辑来垂直去拆分它的微服务,从应用到数据存储一条线打通。 那它带来的问题就是团队协作的问题、团队之间的程序联调的问题以及服务治理和服务依赖的问题。 所以为什么从以前的SOA发展到微服务,再发展到现在所谓的云原生微服务,要用容器化的方式以及DevOps的这些工具,来使微服务的开发能够快速地、独立地运行下去。
我个人认为小的应用及小团队碰不到微服务的一些架构,因为根本用不上。 十几个人的团队或者是几十个人的团队,你的架构只要解决: 加机器就能够实现横向可扩,能够支撑你的业务量,比如一天几十万单的规模,所以不要轻易去尝试这样的一些架构。 这个系统其实也是一样的,我们一开始在设计的时候它并不是现在的架构。 刚开始它就是单体应用,然后通过这个几千人、上万人用的时候,我们开始思考,接下来可能就是几万人同时在线的这种场景,怎么办呢? 我们也经历了应用的拆分、分表、分库,然后怎么去抽取中台等等,也是这样演变过来的。
这里面提到一个业务中台,包括业务中台、数据中台、AI中台。 我个人认为就是说基于公司的一些规模,其实不是所有公司都需要有这么一个中台。 首先你没那么大的体量,你的业务没那么复杂,服务化就可以了。 刚才也有提到,其实微服务比较难的地方就是它的这种服务之间的调用、依赖等等。 那我们就需要有一个服务治理的平台,去管理每一组服务,不能因为单个服务的故障,使整体系统可用性受到影响,所以要有这种熔断机制以及限流机制。 这个其实是系统架构和工程方面的一些实践和经验,就不细讲了。
2、MySQL 分表分库策略
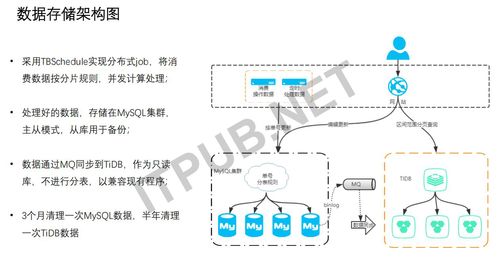
那下面我们通过这样的一个系统,看我们在数据存储方面做了一些什么样的调整。 首先,刚才介绍过,我们的数据源主要是来自于消息同步,当然消息的量是非常大的。 我们会用分布式Job去处理这些数据,所以我们会采用TBSchedule,淘宝的一个开源的分布式job。 我们会把这些消费的数据按分配规则进行分片,然后做处理,这是一个比较灵活的框架。
从这张图来看,消费数据进了我们的业务库,当然这不是所有的业务库,我们是按照这个不一样的业务场景、业务逻辑去进行了库的拆分。
因为这个场景它是一个写多读少或者说基本不太读的这样一个场景,所以我们就落到主库,然后有一个从库用来做备份。 同时我们会把这些主库里计算完成并结算的数据,通过MQ的方式同步到TiTB,把它作为一个只读库。 把数据同步到TiTB其实是不再进行分表了,这样能够降低系统复杂性。
其实这个数据我们会定期地做删除,间隔大概是三到四个月,就是会把这些三到四个月之前主库产生的数据做一些清理,TiTB里面的数据也是一样。 也有一个做法是接下来会把它抽取到hadoop里面,做一些深度的数据挖掘。
刚才提到了我们对数据库分表分库的策略,基于我们的应用场景,我们使用的是sharding-jdbc来做了一些自己的定制化。 我们主要的分表规则有三个,一个是按照商家的ID进行分表,还有就是结算单号及时间。 刚才也提到说消费完之后,我们会把数据存下来,同时我们会做数据的异构,按照不同规则去拆。 比如说按商家来拆,它的应用场景是,商家登录进来就可以看到自己的账单,所以我们会把这些SQL都落在单表里面,就按照商家ID进行区分。 大概拆成1024张表,后续会再拆的更细一些,因为商家的业务量可能会越来越大。
另外还有一种场景就是多个商家之间的结算,那这种场景我们会按照结算单号去拆,每一单上面商家A和商家B的所有结算数据。 另外,我们也会统计按月或者是按天的、跨商家的数据,要看总报表也是按这样的维度来分。
拆分的过程中其实会遇到一个问题。 因为商家的业务规模有大有小,有的可能每天几千单,有的每天几千万,所以会使得小商家会受到某些大商家的海量数据的影响。 比如,有时候有的商家反映在查询非常的慢,查下来就会发现原来是大商家在里面占了很大的存储空间。 所以我们会基于sharding-jdbc做一些定制化的一些处理。 处理过后,当这个商家的数据达到一定程度的时候,比如说我们有一个阈值,如果每天增量达到十万条,那我可能就单独为它去拆分一张表。 所以我们大致的方式是通过MySQL主从、读写分离来应对目前数据存储的问题。 另外,读库方面我们正在逐步转到TiTB去做。
其实从刚才说的分表分库,大家就可以感受到最好的情况其实就是不分表、不分库,那对应用来说,程序写得可能就简单。 我们有这种MyCat、sharding-jdbc,虽然你写得不复杂,但是整个架构就变得复杂了,因为引入了一个中间层。 所以我们其实是基于这样的场景,做了一个适合当前应用的数据量的架构。 假设未来数据库强大到单表几亿的复杂查询都能够支持,那应用写得会非常简单。 所以现在是因为数据存储技术达不到,导致了应用架构复杂性的增加。
3、数据异构实践

接下来我们介绍数据异构以及数据聚合,其实刚才也有提到一些,比如基于不同的子系统,数据可能要被异构出来变成多份,甚至异构出来的是不存储在MySQL 里面,也不会存在像ES、Redis。 举个例子,比如说基于每天的账单数据算出每个商家的余额,可能就扔到Redis里面,它再去读取的时候就会快很多。 ES里面也是一样,要查账或者查明细历史数据,可能一个月范围内的就不用去数据库里面捞了,就在ES里面去做。 因为这种场景的实时性要求并不是很高的。 而且ES里面如果数据量大,分布式搜索引擎创建索引,在合并的时候是有一定的延迟的,而且ES里调优也是非常有技术含量的,需要花很多功夫。
另外我们还提到了数据聚合,因为现在大多数的应用都采用了前后台分离,就算是做APP的开发或者说做基于Web端的也是这样。 前面是JS,后面就是调各种微服务的API的一些接口。
前后端分离会导致一个怎样的问题呢? 当你进到这个页面的时候,展示一个完整的页面,但其实前端会向服务端发出,大概十几、二十个API请求。 这种一个是慢,另一个就是网络耗时、体验都会受影响,另外复杂性也是一个问题。 所以我们才会去做数据聚合,在服务端和应用端都会做一层。 举个例子,比如说刚进到结算系统的首页,那它展示的可能是今天的出勤率、今天的账单等等,大概十几、二十项的数据。 这些会在服务端去做一个数据的聚合,会有个job去跑,然后把数据先预存下来,存到比如说Redis或者MySQL里,这样在客户端去请求的时候,就能够做请求合并。 这样就对整个工程或者数据存储做了一个优化。
4、TiDB使用与优化

刚才有提到TiTB,那我们选型的主要思考是MySQL的单机性能和容量无法线性以及灵活扩展。 刚才也提到了为什么会用云原生微服务化,其实这个是很复杂的架构。 为什么很简单的一个结算系统会搞的那么复杂? 原因就是数据存储的技术受到一些挑战。
我们考虑选型的时候,因为主要的业务场景都是用MySQL来存,我们开始就没有再用Oracle。 所以至少不能让开发人员去把SQL重写一套。 另外就是强一致性、分布式事务方面的一些要求,这是基本的结算系统的一些要求,所以我们尝试使用TiTB来解决这样的问题。
在使用的过程中,我们首先是将TiTB替代MySQL的从库,因为TiTB支持海量数据的查询,所以我们TiDB里对刚才讲的各种数据异构、分表分库等进行了合并。 合并的方式遇到也约到了问题,比如说你分了1024张表,那每张表在MySQL里面的自增ID,就是表一表二,其实它可能是有重复主键的。 那要把它合过来的话,在TiTB里面可能也要重新做一个自增主键。
关于切换场景,我们会从离线业务开始切,然后在非核心业务以及核心业务切。 目前我们是做到了第二步即一些非核心业务,大概十几个节点的规模。 其实这也是在做初步的尝试,因为官方的建议,其实我们可能在硬件、部署各方面还没有调到最优。
同时,我们也发现在单表的字段方面,官方的建议是小于一百个字段。 因为我们的结算表的字段也是非常多的,大概用了八十几个字段。 所以查下来的话,其实整个的性能还是比较理想。 这是我们目前对于非核心业务场景的一个使用情况。 这也使得我们会加大对TiTB的尝试和使用。
另外,对于延时比较低的场景可能不太适合,比如刚才讲的账单实时编辑的这些场景。 我们也想过,在账单实时编辑,主库用MySQL,也分表分库,然后从库用TiTB。 所有的只读查询,都到TiTB里面去。 这个我们暂时还没有在核心业务中去尝试。
另外还有一个问题,涉及大量删除的会有GC性能的问题。 就是说这种场景在维护的时候肯定不会在业务高峰时间去做。
4
不足及展望

上面我们谈了SAAS系统多租户的结算系统以及它所面临的业务方面的挑战,还有我们如何使用微服务架构,以及如何使用分表分库、主从分离等等那些技术。
总结一下,首先我们这样的场景,因为业务还是不断增长的,所以MySQL作为存储,其实它的容量和性能,对我们的应用场景来说可能已经达到一个极限了。 保守来说,如果我们的业务量再翻个两三倍的话,可能就比较危险了。
分表分库的查询,就像我们刚才讲到的在中间层增加了架构的复杂性。 所以接下来假设我们做一些尝试,如果海量分布式数据库的应用能够大量去使用的话,可能在架构上就能够得到极大的简化。
另外,其实我们对于业务数据包括热数据、温数据以及冷数据,它应该是有一整套完备的数据处理系统,所以我们接下来会做这种工具桥,就是说把MySQL、TiDB等都打通,实现数据的一体化治理。
最后提一个概念,大型的互联网系统架构的探索,就是所谓的云原生的微服务,加上云原生数据库的概念。 提到云原生的微服务,上午其实还在跟嘉宾讨论云原生数据库的问题,可能接下来我们会加强在云原生数据库这块的一些应用和探索。
以上就是我跟大家分享的内容,谢谢大家!
-End-
看到这的,都是真爱,随便关注下吧!

想跟文章作者、100位互联网大咖交流学习?
加入“技术领导力社区”
长按扫描下方二维码,添加助理小姐姐Emma
稍后她会拉你进社区群

精彩文章推荐:
正文到此结束
- 本文标签: 领导 实例 数据挖掘 应用架构 缓存 mysql js 功夫 redis App 开源 Word 服务端 JDBC https cat CTO 总结 删除 MQ 索引 db 互联网 数据 空间 开发 http ORM sharding Hadoop 压力 UI 时间 分页 统计 Job 一致性 定制 数据库 金融 API 二维码 src 2015 高可用 部署 备份 Oracle 系统架构 SOA Excel 企业 文章 分布式 微服务 web 银行 sql 管理 分布式事务 同步 朋友们 id 限流 云 搜索引擎
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

