解码器 与 编码器
解码器
ByteToMessageDecoder 抽象类
将字节解码为消息(或者另一个字节序列), Netty 为它提供了一个抽象的基类: ByteToMessageDecoder .
由于你不可能知道远程节点是否会一次性地发送一个完整的消息, 所以这个类会对入站数据进行缓冲, 直到它准备好处理. 只是将消息进行缓冲, 并不会进行解码操作. 如何缓冲的下面会说.
下面这张图说明了在网络传输中可能出现的情况.
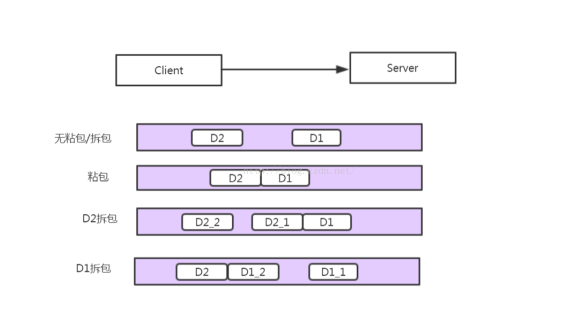
ByteToMessageDecoder 抽象类有两个重要方法.
| 方 法 | 描 述 |
|---|---|
| decode(ChannelHandlerContext ctx,ByteBuf in,List<Object> out) | 必须实现的唯一抽象方法. 方法被调用时传入一个包含新数据的ByteBuf, 和一个添加解码消息的List. 对方法的调用会重复进行, 直到没有新元素被添加到List, 或ByteBuf中没有更多可读取的字节. 如果List不为空 , 它的内容会被传递给 ChannelPipeline 中的下一个 ChannelInboundHandler . |
| decodeLast(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) | 简单调用 decode() 方法, 当 Channel 状态为非活动时, 这个方法会被调用一次. 可以重写该方法已提供特殊处理. |
ByteToMessageDecoder 的属性:
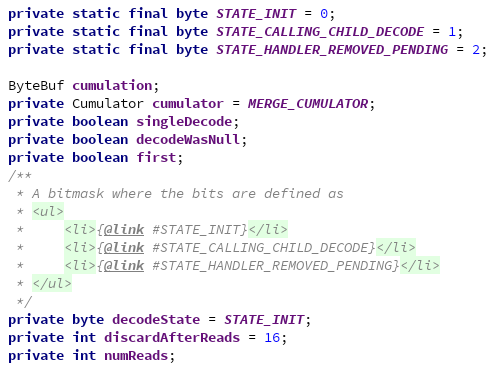
cumulation属性: 用来保存累计读取到的字节. 我们读到的新字节会保存(缓冲)在这里.
cumulator属性: 用来做累计的. 负责将读到的新字节写入 cumulation. 有两个实现 MERGE_CUMULATOR 和 COMPOSITE_CUMULATOR .
singleDecode: 设置为true后, 单个解码器只会解码出一个结果.
decodeWasNull: 解码结果为空.
first: 是否是第一次读取数据.
discardAfterReads: 多少次读取后, 丢弃数据 默认16次.
numReads: 已经累加了多少次数据了.
重点
我们实现 ByteToMessageDecoder 接口时, 最主要的方法就是 decode , 当有新数据进入时, 会先缓冲数据然后将缓冲后的数据传递给我们.
我们进行解码时, 当解码成功后我们将数据放入 decode 方法中的, List<Object> out 集合中, 这样就会传递给下个 ChannelInboundHandler . 如果解码失败就不用操作 List<Object> out 集合.
就向 io.netty.handler.codec.LineBasedFrameDecoder 实现类中的一样
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
if (decoded != null) {
out.add(decoded);
}
}
编解码器中的引用计数
引用计数需要特别的注意. 对于编码器和解码器来说, 其过程也是相当的简单: 一旦消息被编码或者解码, 它就会被 ReferenceCountUtil.release(message) 调用自动释放. 如果你需要保留引用以便稍后使用, 那么你可以调用 ReferenceCountUtil.retain(message) 方法. 这将会增加该引用计数, 从而防止该消息被释放.
MessageToMessageDecoder 抽象类
public abstract class MessageToMessageDecoder<I> extends ChannelInboundHandlerAdapter
与 ByteToMessageDecoder 抽象类一样, 最主要的还是 decode 方法.
decode (ChannelHandlerContext ctx, I msg, List<Object> out)
只不过会将接到的消息强制类型转换为 I , 而且不会对消息进行缓冲.
TooLongFrameException 类
由于 Netty 是一个异步框架, 所以需要在字节可以解码之前在内存中缓冲它们. 因此, 不能让解码器缓冲大量的数据以至于耗尽可用的内存. 为了解除这个常见的顾虑, Netty 提供了 TooLongFrameException 类, 其将由解码器在帧超出指定的大小限制时抛出.
为了避免这种情况, 你可以设置一个最大字节数的阈值, 如果超出该阈值, 则会导致抛出一个 TooLongFrameException (随后会被 ChannelHandler.exceptionCaught() 方法捕获). 然后, 如何处理该异常则完全取决于该解码器的用户. 某些协议 (如HTTP) 可能允许你返回一个特殊的响应. 而在其他的情况下, 唯一的选择可能就是关闭对应的连接.
public class ToIntegerDecoder extends ByteToMessageDecoder {
private static final int MAX_FRAME_SIZE= 1024;
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
int readable = in.readableBytes();
if (readable > MAX_FRAME_SIZE)//检查缓冲区中是否有超过MAX_FRAME_SIZE个字节
{
in.skipBytes(readable);//130第10章 编解码器框架将Integer消息转换为它的String表示,并将其添加到输出的List中跳过所有的可读字节,抛出TooLongFrame-Exception并通知ChannelHandler
throw new TooLongFrameException("Frametoo big!");
}
if (readable >= 4) {
out.add(in.readInt());
}
}
}
编码器
MessageToByteEncoder 抽象类
只有一个必须要实现的方法.
encode(ChannelHandlerContext ctx, I msg, ByteBuf out)
encode() 方法是你需要实现的唯一抽象方法. 它被调用时将会传入要被该类编码为 ByteBuf 的 (类型为I的) 出站消息. 该 ByteBuf 随后将会被转发给 ChannelPipeline 中的下一个 ChannelOutboundHandler .
这个类只有一个方法, 而解码器有两个. 原因是解码器通常需要在 Channel 关闭之后产生最后一个消息 (因此也就有了decodeLast()方法). 这显然不适用于编码器的场景——在连接被关闭之后仍然产生一个消息是毫无意义的.
示例, ShortToByteEncoder , 其接受一个 Short 类型的实例作为消息, 将它编码为 Short 的原子类型值, 并将它写入 ByteBuf 中, 其将随后被转发给 ChannelPipeline 中的下一个 ChannelOutboundHandler . 每个传出的 Short 值都将会占用 ByteBuf 中的2字节.
public class ShortToByteEncoder extends MessageToByteEncoder<Short> {
@Override
public void
encode(ChannelHandlerContext ctx, Short msg, ByteBuf out) throws Exception {
out.writeShort(msg);//将Short写入ByteBuf中
}
}
MessageToMessageEncoder 抽象类
encode(ChannelHandlerContext ctx,I msg,List<Object> out)
这是你需要实现的唯一方法. 每个通过 write() 方法写入的消息都将会被传递给 encode() 方法, 以编码为一个或者多个出站消息. 随后, 这些出站消息将会被转发给 ChannelPipeline 中的下一个 ChannelOutboundHandler .
示例, 编码器将每个出站 Integer 的 String 表示添加到了该 List 中.
public class IntegerToStringEncoder extends MessageToMessageEncoder<Integer> {
@Override
public void encode(ChannelHandlerContext ctx, Integer msg, List<Object> out) throws Exception {
out.add(String.valueOf(msg));
}
}
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

