惊:FastThreadLocal吞吐量居然是ThreadLocal的3倍!!!
说明
接着上次 手撕面试题ThreadLocal!!! 面试官一听,哎呦不错哦!本文将继续上文的话题,来聊聊FastThreadLocal, 目前关于FastThreadLocal的很多文章都有点老有点过时了(本文将澄清几个误区),很多文章关于FastThreadLocal介绍的也不全,希望本篇文章可以带你彻底理解FastThreadLocal!!!
FastThreadLocal是Netty提供的,在池化内存分配等都有涉及到!
关于FastThreadLocal,零度准备从这几个方面进行讲解:
- FastThreadLocal的使用。
- FastThreadLocal并不是什么情况都快,你要用对才会快。
- FastThreadLocal利用字节填充来解决伪共享问题。
- FastThreadLocal比ThreadLocal快,并不是空间换时间。
- FastThreadLocal不在使用ObjectCleaner处理泄漏,必要的时候建议重写onRemoval方法。
- FastThreadLocal为什么快?
FastThreadLocal的使用
FastThreadLocal用法上兼容ThreadLocal
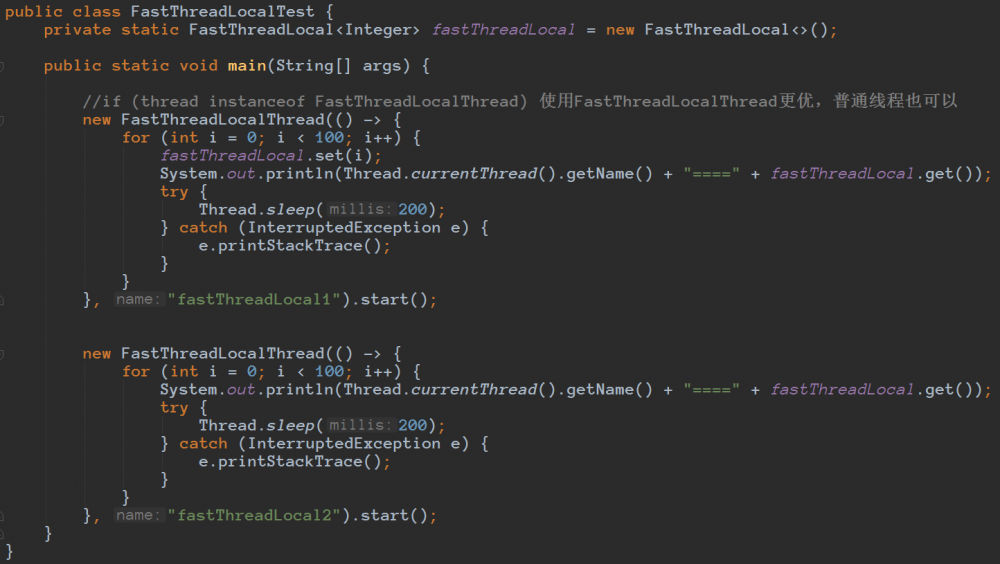
FastThreadLocal使用示例代码:
public class FastThreadLocalTest {
private static FastThreadLocal<Integer> fastThreadLocal = new FastThreadLocal<>();
public static void main(String[] args) {
//if (thread instanceof FastThreadLocalThread) 使用FastThreadLocalThread更优,普通线程也可以
new FastThreadLocalThread(() -> {
for (int i = 0; i < 100; i++) {
fastThreadLocal.set(i);
System.out.println(Thread.currentThread().getName() + "====" + fastThreadLocal.get());
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "fastThreadLocal1").start();
new FastThreadLocalThread(() -> {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + "====" + fastThreadLocal.get());
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "fastThreadLocal2").start();
}
}
代码截图:
代码运行结果:
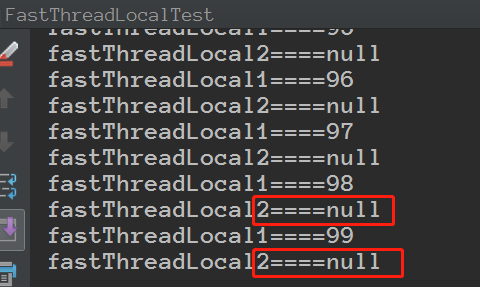
我们在回顾下之前的ThreadLocal的 最佳实践做法:
try {
// 其它业务逻辑
} finally {
threadLocal对象.remove();
}

备注:通过上面的例子,我们发现FastThreadLocal和ThreadLocal在用法上面基本差不多,没有什么特别区别, 个人认为,这就是FastThreadLocal成功的地方,它就是要让用户用起来和ThreadLocal没啥区别,要兼容!
使用FastThreadLocal居然不用像ThreadLocal那样先try ………………… 之后finally进行threadLocal对象.remove();
由于构造FastThreadLocalThread的时候,通过FastThreadLocalRunnable对Runnable对象进行了包装:
FastThreadLocalRunnable.wrap(target)从而构造了FastThreadLocalRunnable对象。

FastThreadLocalRunnable在执行完之后都会调用FastThreadLocal.removeAll();
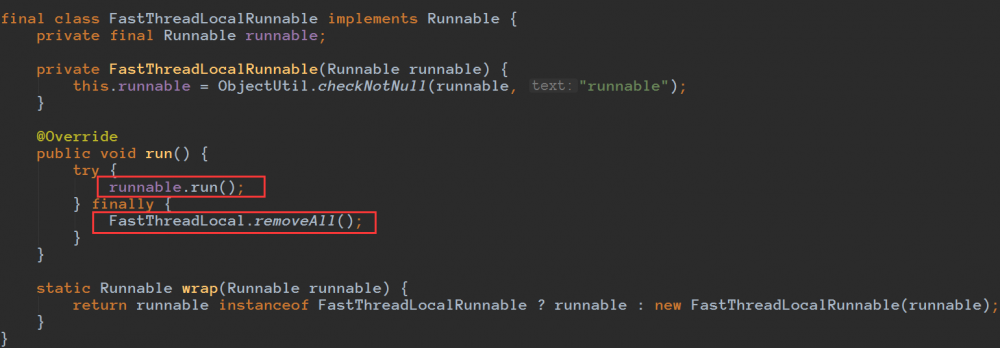
备注:FastThreadLocal不在使用ObjectCleaner处理泄漏,必要的时候建议重写onRemoval方法。关于这块将在本文后面进行介绍,这样是很多网上资料比较老的原因,这块已经去掉了。
如果是普通线程,还是应该最佳实践:
finally { fastThreadLocal对象.removeAll(); }
注意:如果使用FastThreadLocal就不要使用普通线程,而应该构建FastThreadLocalThread,关于为什么这样,关于这块将在本文后面进行介绍:FastThreadLocal并不是什么情况都快,你要用对才会快。
FastThreadLocal并不是什么情况都快,你要用对才会快
首先看看netty关于这块的测试用例: 代码路径:https://github.com/netty/netty/blob/4.1/microbench/src/main/java/io/netty/microbench/concurrent/FastThreadLocalFastPathBenchmark.java
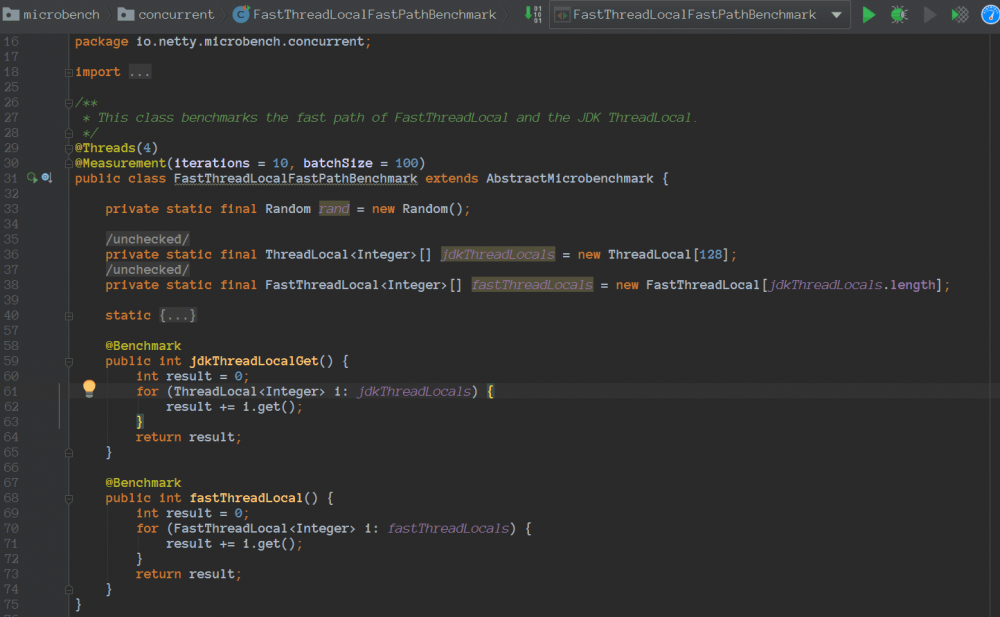
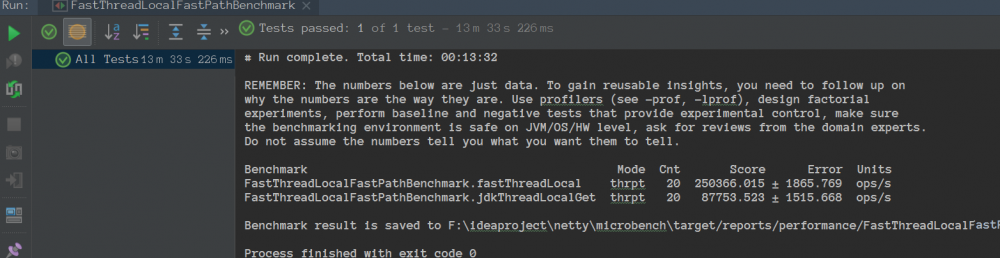
备注:在我本地进行测试,FastThreadLocal的吞吐量是jdkThreadLocal的3倍左右。机器不一样,可能效果也不一样,大家可以自己试试,反正就是快了不少。
关于ThreadLocal,之前的这篇: 手撕面试题ThreadLocal!!! 已经详细介绍了。
FastThreadLocal并不是什么情况都快,你要用对才会快!!!
注意:使用FastThreadLocalThread线程才会快,如果是普通线程还更慢! 注意: 使用FastThreadLocalThread线程才会快,如果是普通线程还更慢! 注意: 使用FastThreadLocalThread线程才会快,如果是普通线程还更慢!
netty的测试目录下面有2个类:
- FastThreadLocalFastPathBenchmark
- FastThreadLocalSlowPathBenchmark
路径:https://github.com/netty/netty/blob/4.1/microbench/src/main/java/io/netty/microbench/concurrent/
FastThreadLocalFastPathBenchmark测试结果:是ThreadLocal的吞吐量的3倍左右。
FastThreadLocalSlowPathBenchmark测试结果:比ThreadLocal的吞吐量还低。
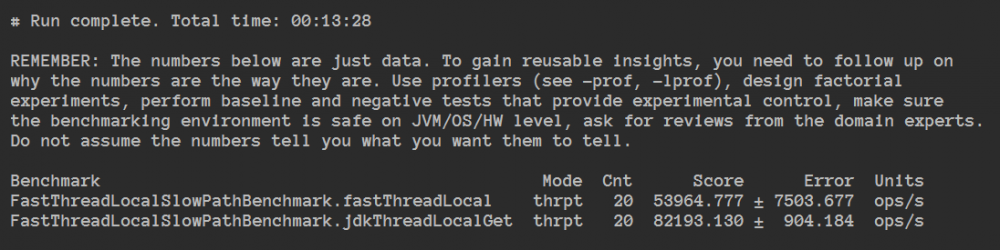
测试结论: 使用FastThreadLocalThread线程操作FastThreadLocal才会快,如果是普通线程还更慢!
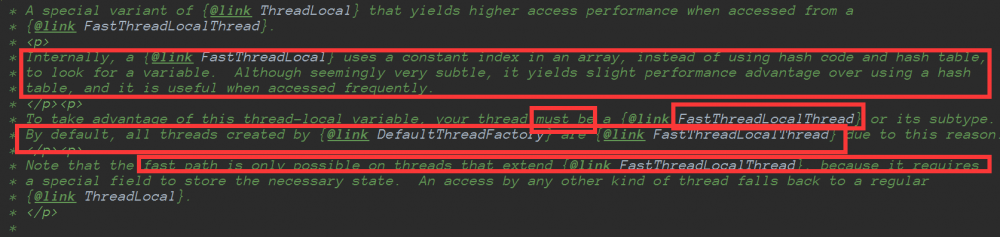
注释里面给出了三点:
-
FastThreadLocal操作元素的时候,使用常量下标在数组中进行定位元素来替代ThreadLocal通过哈希和哈希表,这个改动特别在频繁使用的时候,效果更加显著!
-
想要利用上面的特征,线程必须是FastThreadLocalThread或者其子类,默认DefaultThreadFactory都是使用FastThreadLocalThread的
-
只用在FastThreadLocalThread或者子类的线程使用FastThreadLocal才会更快,因为FastThreadLocalThread 定义了属性threadLocalMap类型是InternalThreadLocalMap。如果普通线程会借助ThreadLocal。
我们看看NioEventLoopGroup细节:
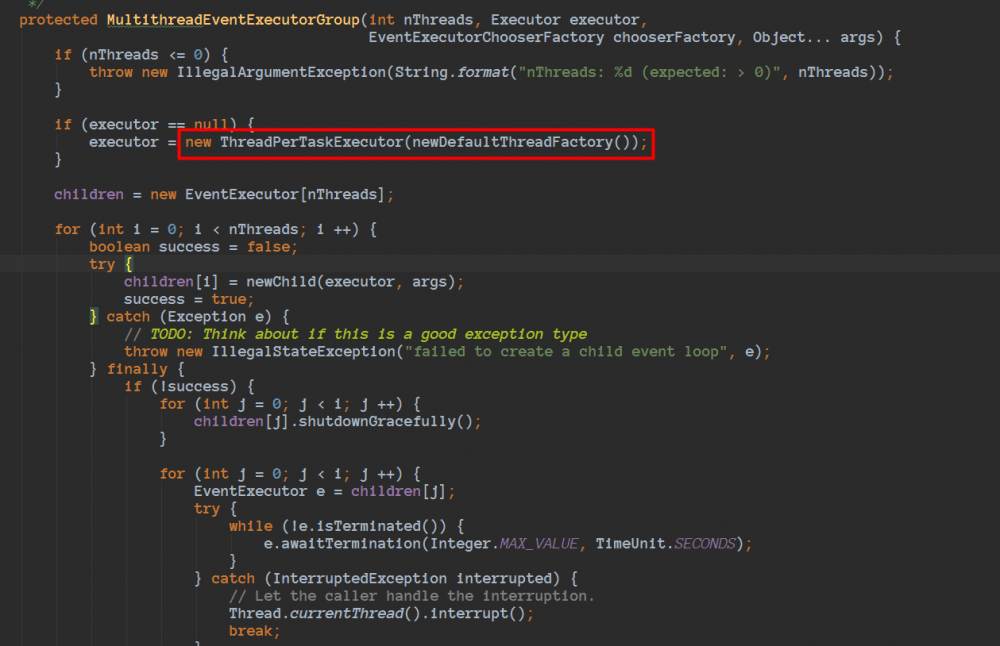

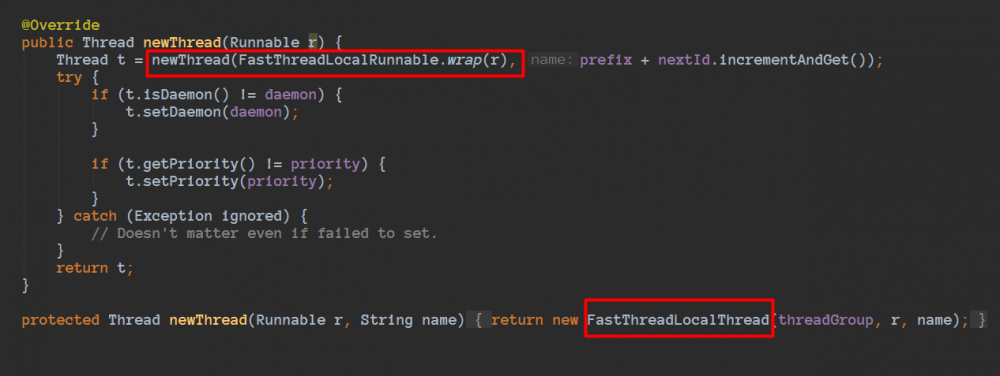
看到这里,和刚刚我们看到的注释内容一致的,是使用FastThreadLocalThread的。
netty里面使用FastThreadLocal的举例常用的:
池化内存分配:
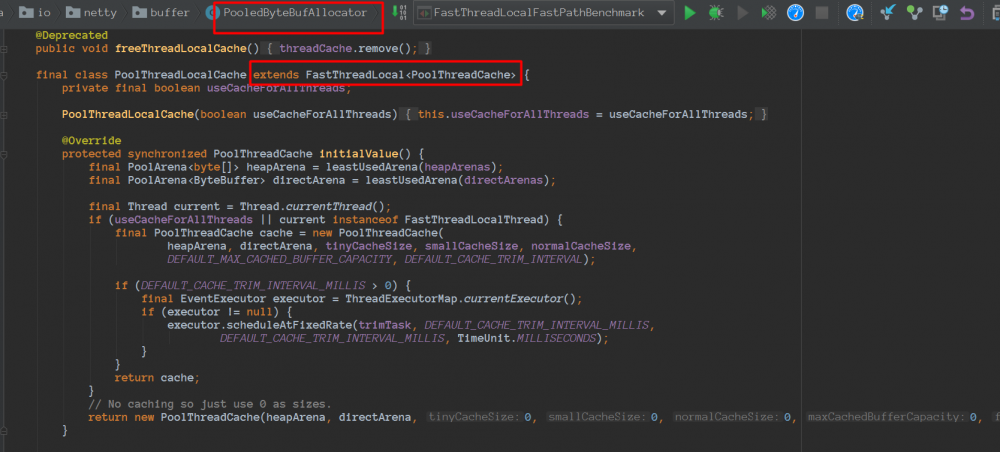
会使用到Recycler
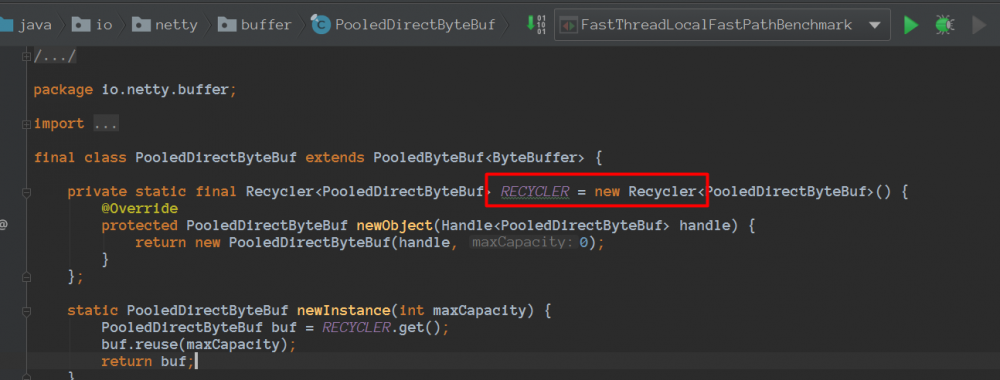
而Recycler也使用了FastThreadLocal
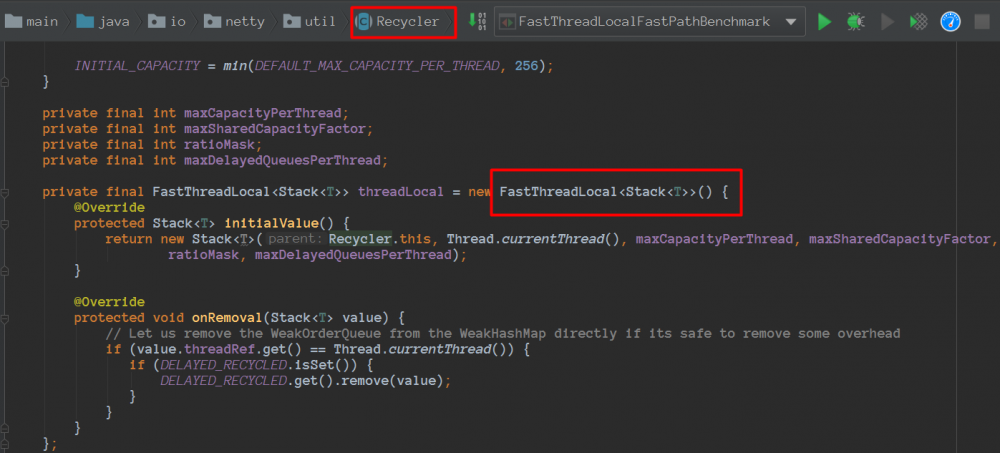
我们再看看看测试类:
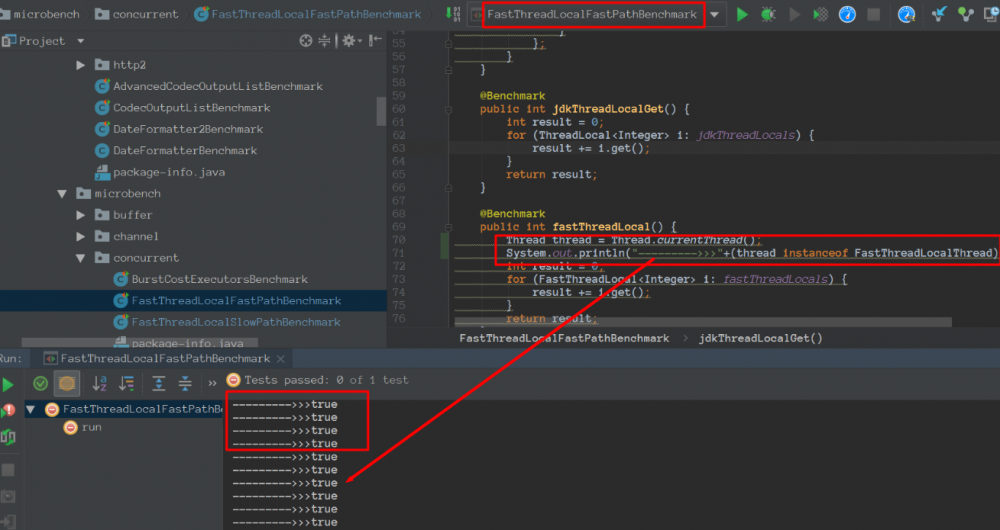
备注:我们会发现FastThreadLocalFastPathBenchmark里面的线程是FastThreadLocal。
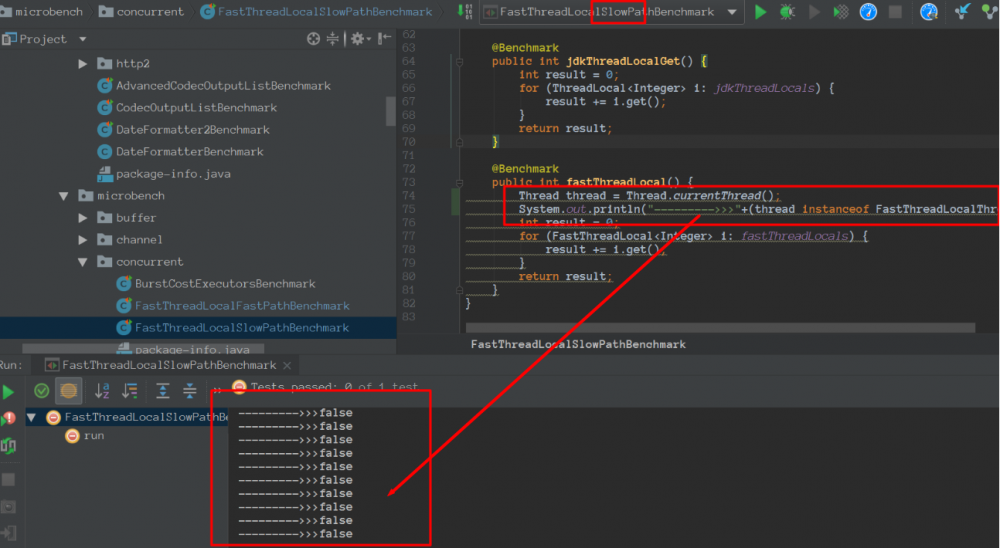
备注:我们会发现FastThreadLocalSlowPathBenchmark里面的线程 不是FastThreadLocal 。
FastThreadLocal只有被的线程是FastThreadLocalThread或者其子类使用的时候才会更快,吞吐量我这边测试的效果大概3倍左右,但是如果是普通线程操作FastThreadLocal其吞吐量比ThreadLocal还差!
FastThreadLocal利用字节填充来解决伪共享问题
关于CPU 缓存 内容来源于美团:https://tech.meituan.com/2016/11/18/disruptor.html
下图是计算的基本结构。L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。
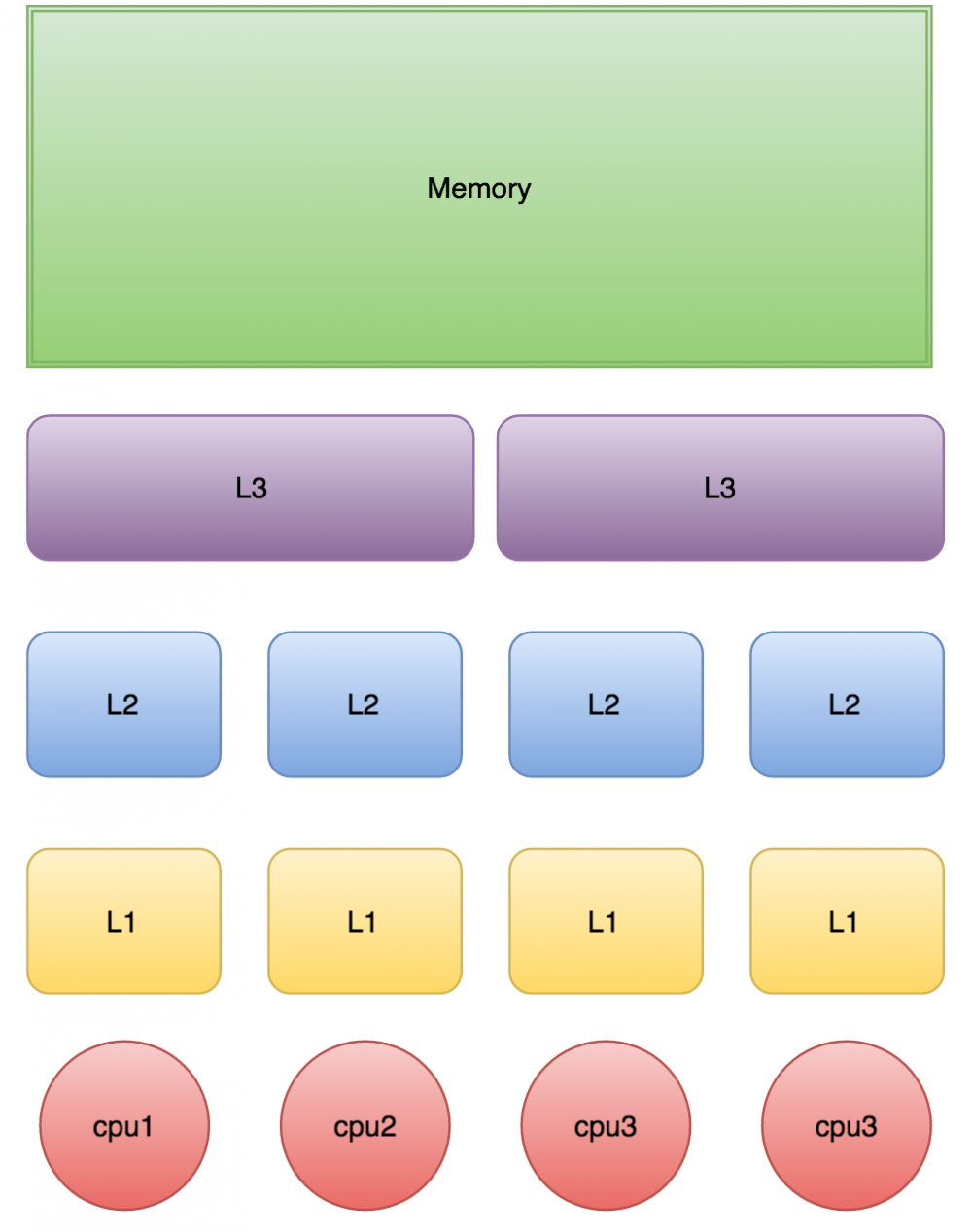
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。
另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。
下面是从CPU访问不同层级数据的时间概念:

可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级。
缓存行
Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块儿地址。一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。
CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。
在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。事实上,你可以非常快速的遍历在连续内存块中分配的任意数据结构。
伪共享
由于多个线程同时操作同一缓存行的不同变量,但是这些变量之间却没有啥关联,但是每次修改,都会导致缓存的数据变成无效,从而明明没有任何修改的内容,还是需要去主存中读(CPU读取主存中的数据会比从L1中读取慢了近2个数量级)但是其实这块内容并没有任何变化,由于缓存的最小单位是一个缓存行,这就是伪共享。
如果让多线程频繁操作的并且没有关系的变量在不同的缓存行中,那么就不会因为缓存行的问题导致没有关系的变量的修改去影响另外没有修改的变量去读主存了(那么从L1中取是从主存取快2个数量级的)那么性能就会好很多很多。
有伪共享 和没有的情况的测试效果
代码路径:https://github.com/jiangxinlingdu/nettydemo
nettydemo
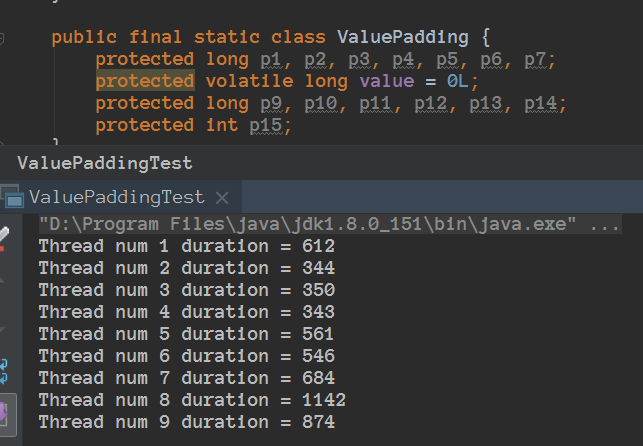
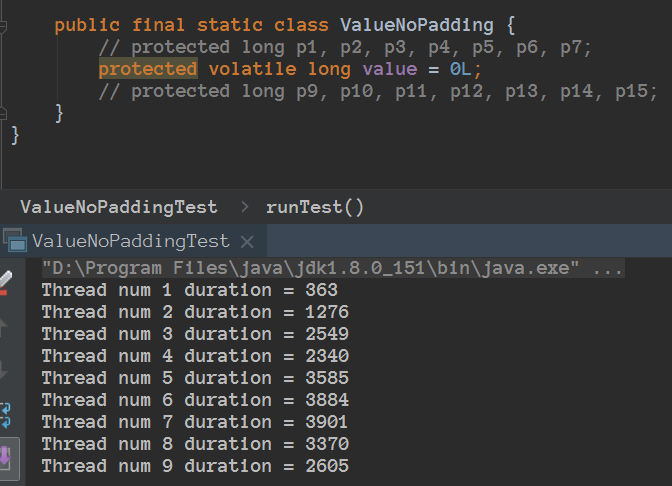
利用字节填充来解决伪共享,从而速度快了3倍左右。
FastThreadLocal使用字节填充解决伪共享
之前介绍ThreadLocal的时候,说过ThreadLocal是用在多线程场景下,那么FastThreadLocal也是用在多线程场景,大家可以看下这篇: 手撕面试题ThreadLocal!!! ,所以FastThreadLocal需要解决伪共享问题,FastThreadLocal使用字节填充解决伪共享。

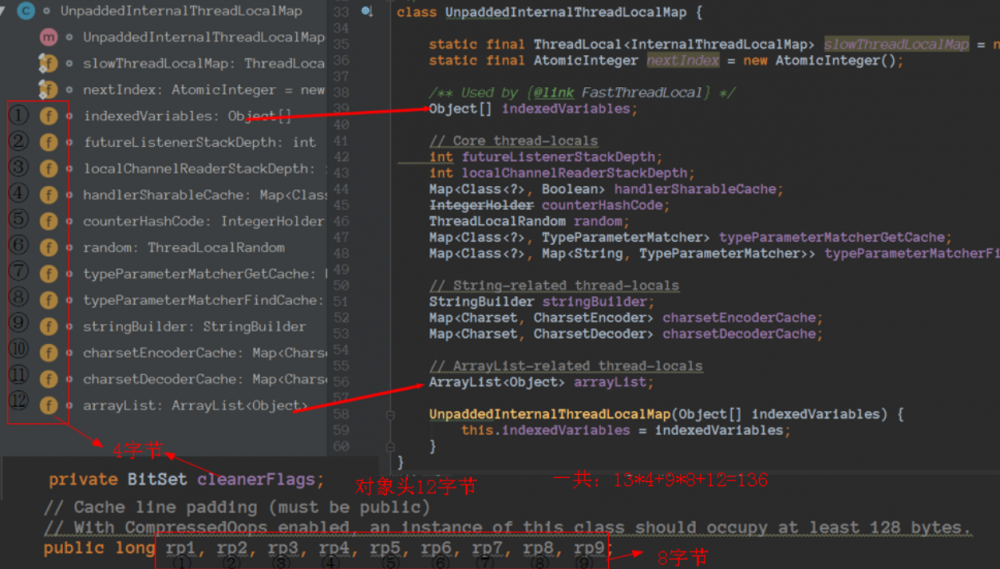
这个是我自己手算的,通过手算太麻烦,推荐一个工具 JOL 。
http://openjdk.java.net/projects/code-tools/jol/
推荐IDEA插件:https://plugins.jetbrains.com/plugin/10953-jol-java-object-layout
代码路径:https://github.com/jiangxinlingdu/nettydemo
nettydemo
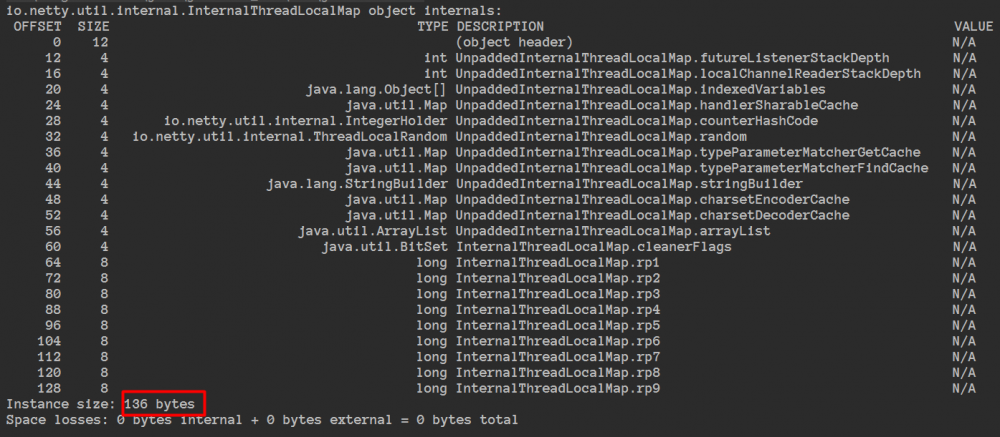
通过这个工具算起来就很容易了,如果以后有类似的需要看的,不用手一个一个算了。
FastThreadLocal被FastThreadLocalThread进行读写的时候也可能利用到缓存行
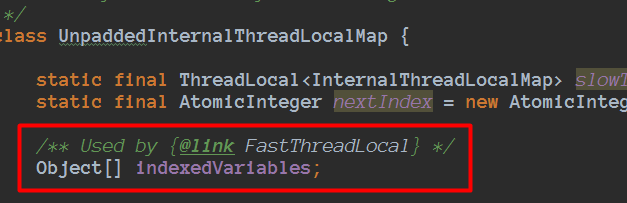
并且由于当线程是FastThreadLocalThread的时候操作FastThreadLocal是通过indexedVariables数组进行存储数据的的,每个FastThreadLocal有一个常量下标,通过下标直接定位数组进行读写操作,当有很多FastThreadLocal的时候,也可以利用缓存行,比如一次indexedVariables数组第3个位置数据,由于缓存的最小单位是缓存行,顺便把后面的4、5、6等也缓存了,下次刚刚好另外FastThreadLocal下标就是5的时候,进行读取的时候就直接走缓存了,比走主存可能快2个数量级。
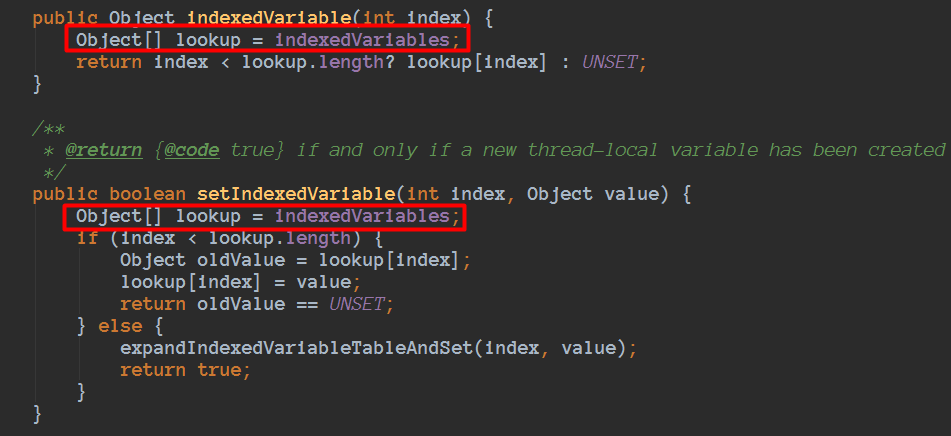
一点疑惑
问题:为什么这里填充了9个long值呢???
我提了一个issue:https://github.com/netty/netty/issues/9284

虽然也有人回答,但是感觉不是自己想要的,说服不了自己!!! 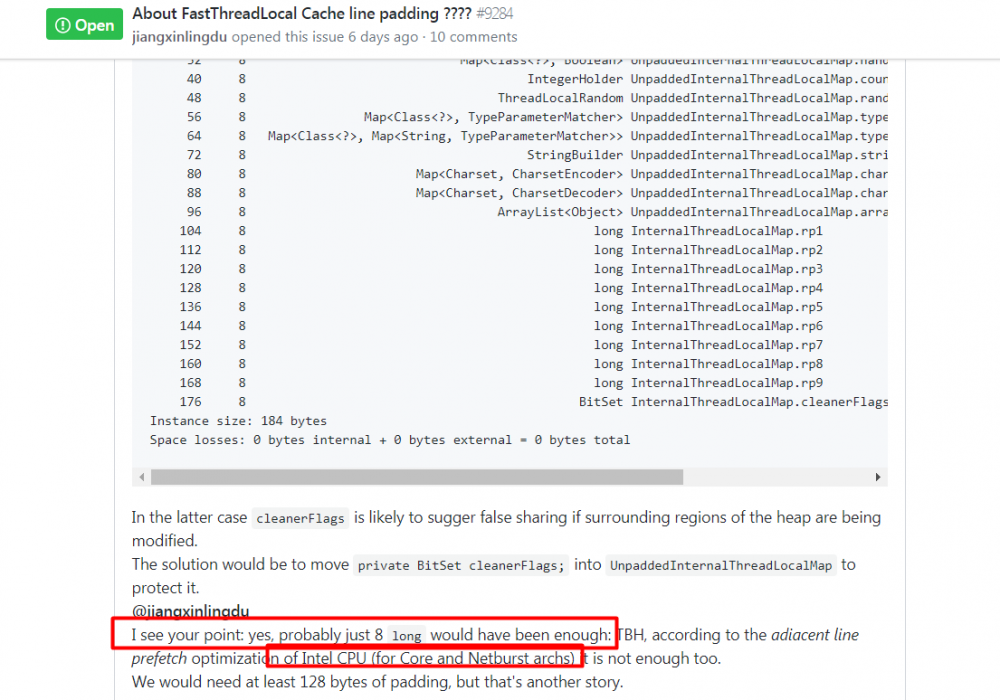
FastThreadLocal比ThreadLocal快,并不是空间换时间
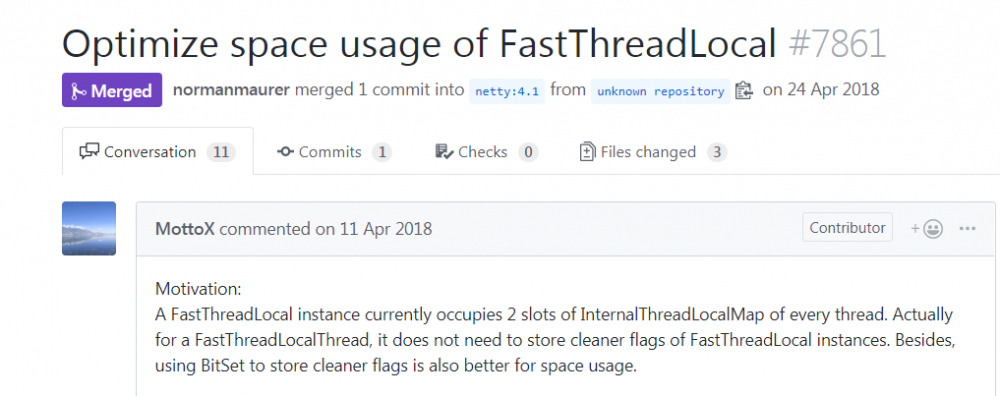

现在清理已经去掉,本文下面会介绍,所以FastThreadLocal比ThreadLocal快,并不是空间换时间,FastThreadLocal并没有浪费空间!!!
FastThreadLocal不在使用ObjectCleaner处理泄漏,必要的时候建议重写onRemoval方法
最新的netty版本中已经不在使用ObjectCleaner处理泄漏:
https://github.com/netty/netty/commit/9b1a59df383559bc568b891d73c7cb040019aca6#diff-e0eb4e9a6ea15564e4ddd076c55978de
https://github.com/netty/netty/commit/5b1fe611a637c362a60b391079fff73b1a4ef912#diff-e0eb4e9a6ea15564e4ddd076c55978de
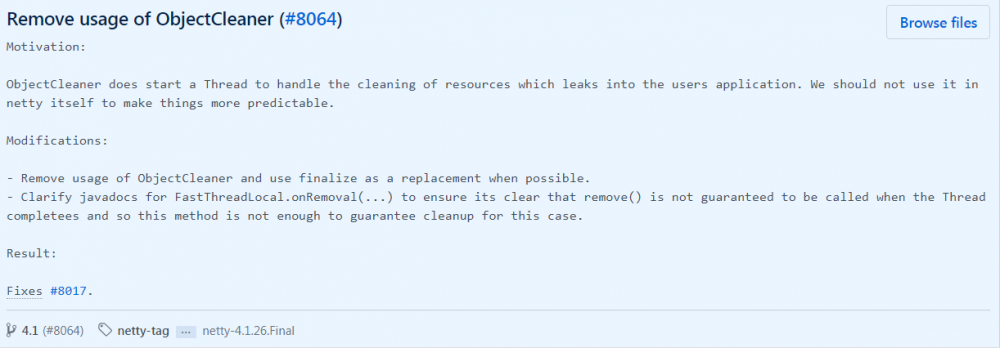
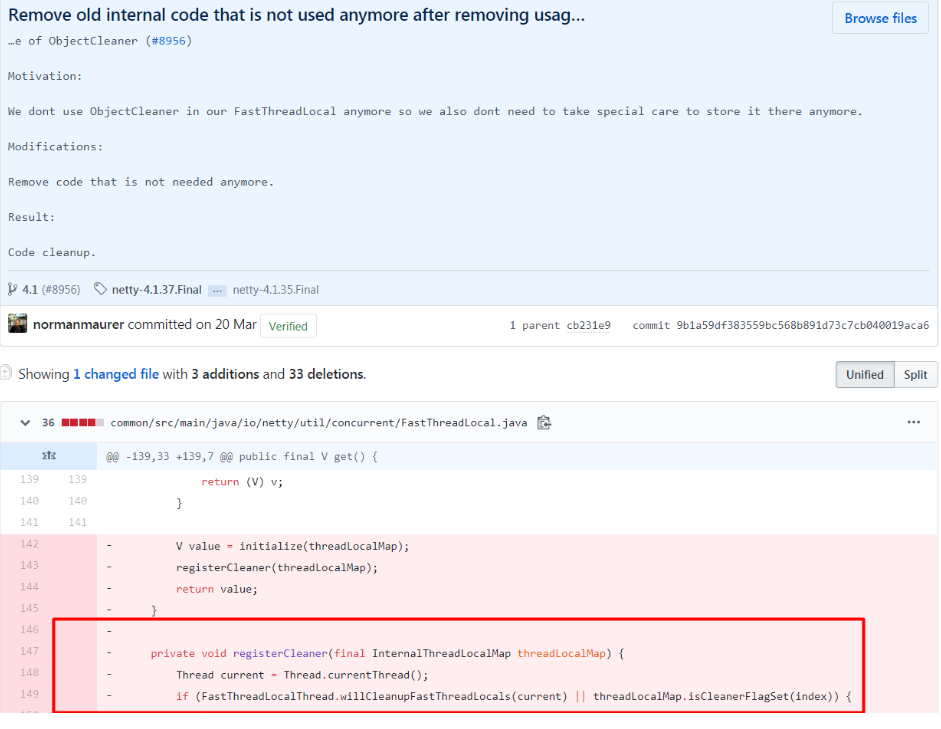
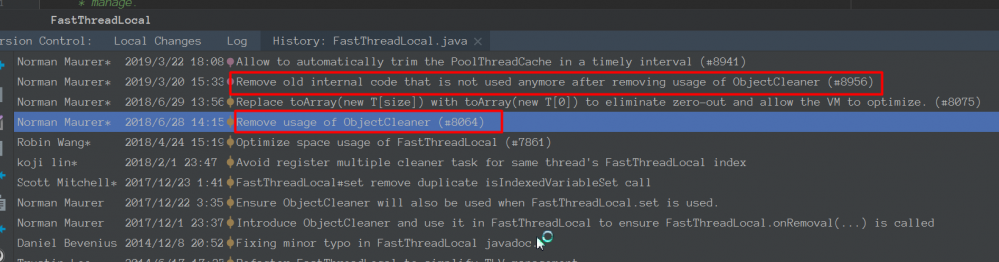
去掉原因:
https://github.com/netty/netty/issues/8017
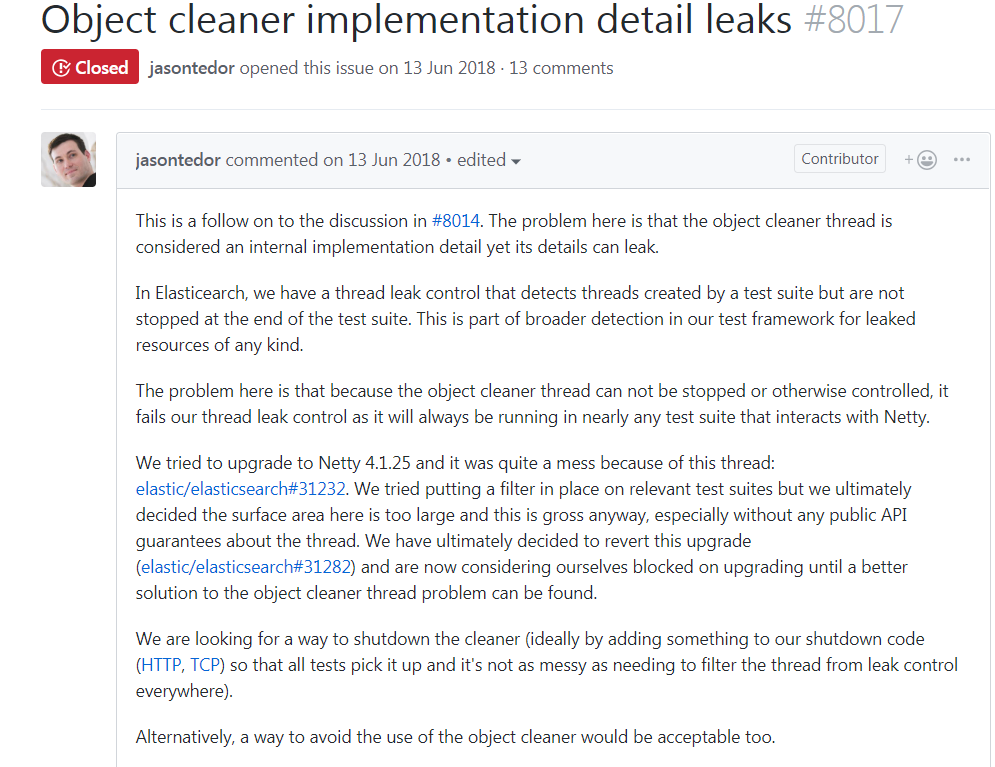
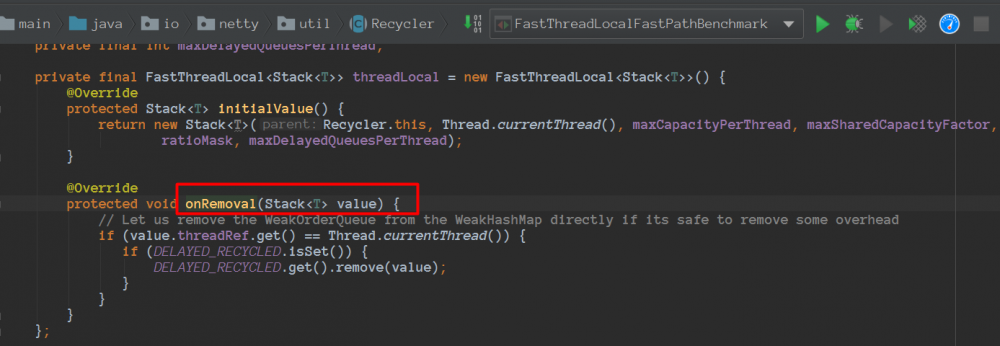
我们看看FastThreadLocal的onRemoval
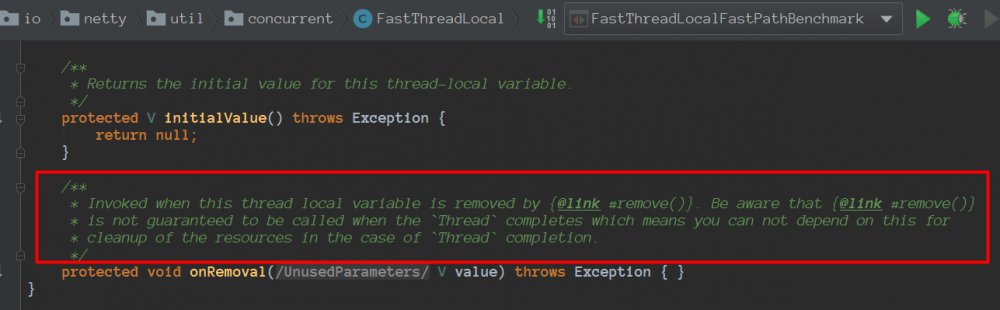
如果使用的是FastThreadLocalThread能保证调用的,重写onRemoval做一些收尾状态修改等等
FastThreadLocal为什么快?
FastThreadLocal操作元素的时候,使用常量下标在数组中进行定位元素来替代ThreadLocal通过哈希和哈希表,这个改动特别在频繁使用的时候,效果更加显著!计算该ThreadLocal需要存储的位置是通过hash算法确定位置: int i = key.threadLocalHashCode & (len-1);而FastThreadLocal就是一个常量下标index,这个如果执行次数很多也是有影响的。
并且FastThreadLocal利用缓存行的特性,FastThreadLocal是通过indexedVariables数组进行存储数据的,如果有多个FastThreadLocal的时候,也可以利用缓存行,比如一次indexedVariables数组第3个位置数据,由于缓存的最小单位是缓存行,顺便把后面的4、5、6等也缓存了,下次刚刚好改线程需要读取另外的FastThreadLocal,这个FastThreadLocal的下标就是5的时候,进行读取的时候就直接走缓存了,比走主存可能快2个数量级而ThreadLocal通过hash是分散的。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

