Spring Cloud Alibaba Nacos(源码篇)
在看这篇文章之前,最好对NACOS相关功能有所了解,推荐看完 Spring Cloud Alibaba Nacos(功能篇) 。
针对功能,有目的的去找相对应的源代码,进一步了解功能是如何被实现出来的。
本文针对有一定源代码阅读经验的人群,不会深入太多的细节,还需要读者打开源码跟踪,自行领会。
一、引子
进入GitHub对应的页面,将NACOS工程clone下来。目录和文件看起来很冗长,但是对于看源代码真正有帮助的部分并不多。
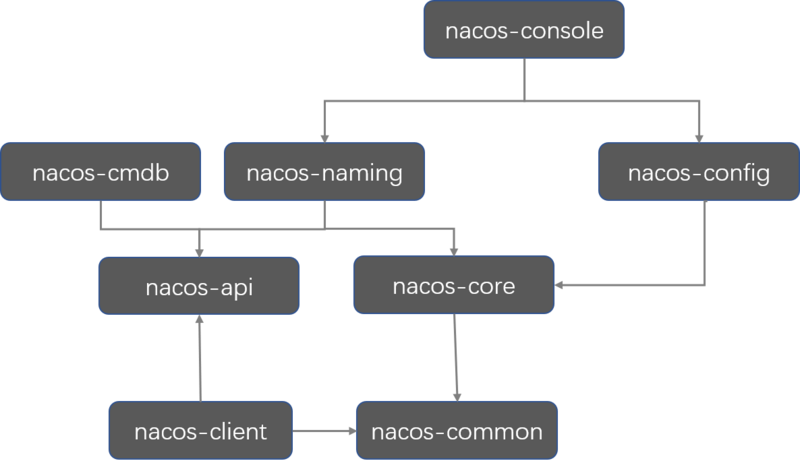
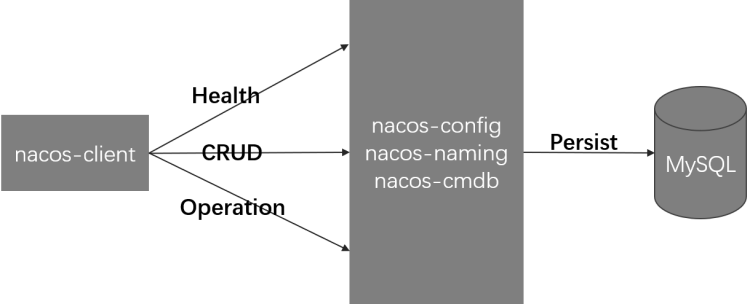
有了这三张图,就能顺利找到突破口了,核心内容就集中在nacos-console,nacos-naming,nacos-config,顺藤摸瓜,就能看到不少内容了。
如果还是感觉无从下手的话,那就移步nacos-example,里面有主要业务的调用入口,一看便知。
二、配置服务
首先从一个工厂类说起:com.alibaba.nacos.api.NacosFactory。
里面的静态方法用于创建ConfigService和NamingService,代码类似,以创建ConfigService为例:
public static ConfigService createConfigService(Properties properties) throws NacosException {
try {
Class<?> driverImplClass = Class.forName("com.alibaba.nacos.client.config.NacosConfigService");
Constructor constructor = driverImplClass.getConstructor(Properties.class);
ConfigService vendorImpl = (ConfigService) constructor.newInstance(properties);
return vendorImpl;
} catch (Throwable e) {
throw new NacosException(-400, e.getMessage());
}
}
没有什么复杂的逻辑,使用的是基本的反射原理。构造参数传入了properties,这些属性可以通过bootstrap.yml中指定,对应的是NacosConfigProperties。
需要细看的是构造函数中对于namespace初始化的那部分内容。
private void initNamespace(Properties properties) {
String namespaceTmp = null;
String isUseCloudNamespaceParsing =
properties.getProperty(PropertyKeyConst.IS_USE_CLOUD_NAMESPACE_PARSING,
System.getProperty(SystemPropertyKeyConst.IS_USE_CLOUD_NAMESPACE_PARSING,
String.valueOf(Constants.DEFAULT_USE_CLOUD_NAMESPACE_PARSING)));
if (Boolean.valueOf(isUseCloudNamespaceParsing)) {
namespaceTmp = TemplateUtils.stringBlankAndThenExecute(namespaceTmp, new Callable<String>() {
@Override
public String call() {
return TenantUtil.getUserTenantForAcm();
}
});
namespaceTmp = TemplateUtils.stringBlankAndThenExecute(namespaceTmp, new Callable<String>() {
@Override
public String call() {
String namespace = System.getenv(PropertyKeyConst.SystemEnv.ALIBABA_ALIWARE_NAMESPACE);
return StringUtils.isNotBlank(namespace) ? namespace : EMPTY;
}
});
}
if (StringUtils.isBlank(namespaceTmp)) {
namespaceTmp = properties.getProperty(PropertyKeyConst.NAMESPACE);
}
namespace = StringUtils.isNotBlank(namespaceTmp) ? namespaceTmp.trim() : EMPTY;
properties.put(PropertyKeyConst.NAMESPACE, namespace);
}
传入的properties会指定是否解析云环境中的namespace参数,如果是的,就是去读取阿里云环境的系统变量;如果不是,那么就读取properties中指定的namespace,没有指定的话,最终解析出来的是空字符串。从代码上看出来,获取云环境的namespace做成了异步化的形式,但是目前版本还是使用的同步调用。
继续跟踪ConfigService,里面定义了一系列接口方法,正是我们所要看的。
每个业务实现最终都归结为Http请求,就是配置的serverAddr,多个地址会依次轮转使用,当然是在一定超时时间内依次请求,都请求不成功了,那就会抛出异常。
请求方是nacos-client,接收方最终都是落到nacos-config服务上,最后使用JdbcTemplate进行数据持久化。
这一部分的代码一看就明白,发布配置,获取配置和删除配置都有所体现,就不展开阐述了。
重点解析一下配置监听部分的源代码。
先将注意力放在com.alibaba.nacos.client.config.impl.CacheData这个数据结构上,是个典型的充血模型,主要是充当listener管理者的角色,这样看来,类名取得并不是那么友好了。
实际上,可以看出CacheData将配置信息(namespace, content)和listener聚合在一起了,可以认为一项配置可以附加多种listener实施监听(因为listener接口可能有多种实现),每种listener只会有一个实例附加在配置上。
public void addListener(Listener listener) {
if (null == listener) {
throw new IllegalArgumentException("listener is null");
}
ManagerListenerWrap wrap = new ManagerListenerWrap(listener);
if (listeners.addIfAbsent(wrap)) {
LOGGER.info("[{}] [add-listener] ok, tenant={}, dataId={}, group={}, cnt={}", name, tenant, dataId, group,
listeners.size());
}
}
使用了CopyOnWriteArrayList.addIfAbsent方法,这个方法最重要就是equals方法,ManagerListenerWrap是对listener的另外一种形式的包裹,其实现了equals方法:
@Override
public boolean equals(Object obj) {
if (null == obj || obj.getClass() != getClass()) {
return false;
}
if (obj == this) {
return true;
}
ManagerListenerWrap other = (ManagerListenerWrap) obj;
return listener.equals(other.listener);
}
再往上层翻,可以找到对于listener更高层的管理API:com.alibaba.nacos.client.config.impl.ClientWorker。
同样是对listener的管理,但是增加了重复校验,其中cacheMap是关键,如下定义:
private final AtomicReference<Map<String, CacheData>> cacheMap = new AtomicReference<Map<String, CacheData>>()
使用了具有原子性操作特性的AtomicReference,可以避免并发带来的数据不一致的问题,里面包裹的是一个HashMap,value是CacheData对象,而key是有一定生成规则的,在GroupKey这个类中可以找到:
static public String getKeyTenant(String dataId, String group, String tenant) {
StringBuilder sb = new StringBuilder();
urlEncode(dataId, sb);
sb.append('+');
urlEncode(group, sb);
if (StringUtils.isNotEmpty(tenant)) {
sb.append('+');
urlEncode(tenant, sb);
}
return sb.toString();
}
实际上是将配置信息用“+”号进行拼接,如果配置信息中本身存在了“+”和“%”,会使用urlEncode方法进行编码转义。当然,也有配套的解析方法,这里就不再展开讲解了。
接下来的无非就是就cacheMap的一系列get和set操作,用以维护listener。特别注意的是,每次更新操作都是先生成一个copy对象,操作此对象之后,再整个set(覆盖)到cacheMap中。
最后说一下listener是如何运行起来的。
仍然是在ClientWorker当中可以找到,将注意力转移到构造函数中。其中,可以注意到,初始化了两个线程池:
executor = Executors.newScheduledThreadPool(1, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setName("com.alibaba.nacos.client.Worker." + agent.getName());
t.setDaemon(true);
return t;
}
});
executorService = Executors.newScheduledThreadPool(Runtime.getRuntime().availableProcessors(), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setName("com.alibaba.nacos.client.Worker.longPolling." + agent.getName());
t.setDaemon(true);
return t;
}
});
executor.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
try {
checkConfigInfo();
} catch (Throwable e) {
LOGGER.error("[" + agent.getName() + "] [sub-check] rotate check error", e);
}
}
}, 1L, 10L, TimeUnit.MILLISECONDS);
两个用于执行定时任务的scheduledThreadPool,而这两个线程池的分工也是嵌套的:executor用于发布配置检查的任务,而executorService则是任务的接收者,是真正执行任务的角色。
所以发布任务的线程池只分配了1个核心线程数,而执行任务的线程池的核心线程是CPU核数。
因为配置检查是一个长轮询的过程,一个任务执行者能监测的配置数量需要得到控制,所以NACOS目前使用了一个比较简单的分任务规则:
public void checkConfigInfo() {
// 分任务
int listenerSize = cacheMap.get().size();
// 向上取整为批数
int longingTaskCount = (int) Math.ceil(listenerSize / ParamUtil.getPerTaskConfigSize());
if (longingTaskCount > currentLongingTaskCount) {
for (int i = (int) currentLongingTaskCount; i < longingTaskCount; i++) {
// 要判断任务是否在执行 这块需要好好想想。 任务列表现在是无序的。变化过程可能有问题
executorService.execute(new LongPollingRunnable(i));
}
currentLongingTaskCount = longingTaskCount;
}
}
在ParamUtil.getPerTaskConfigSize()中返回的是每个任务能监测的配置数量上限,默认是3000条,可以通过系统变量PER_TASK_CONFIG_SIZE更改这个上限。
从代码上可以看出,如果当前listener的数量没有超过3000个,配置监测的线程池还运转不起来。如果细看这个部分的代码,还是会发现一些问题的,主要是围绕着任务管理衍生出来的一系列问题。
长轮询里面主要有两部分逻辑:
- 检查本地配置,与CacheData存储的信息保持一致;
- 检查server端配置,更新CacheData存储的信息。
三、服务注册与发现
有了上述的基础,这部分代码看起来会比较轻松了,结构上基本相似。
直接进入com.alibaba.nacos.api.naming.NamingService,里面有多个registerInstance重构方法,用于服务注册。
先看看Instance实体类包含的内容:id,ip,port,serviceName,clusterName(所在集群),weight(权重),healthy(是否正常),enabled(是否启用),ephemeral(是否是临时的),这9个属性全部都可以在Console中有所体现。
然后,直接看注册服务的方法:
@Override
public void registerInstance(String serviceName, String groupName, Instance instance) throws NacosException {
if (instance.isEphemeral()) {
BeatInfo beatInfo = new BeatInfo();
beatInfo.setServiceName(NamingUtils.getGroupedName(serviceName, groupName));
beatInfo.setIp(instance.getIp());
beatInfo.setPort(instance.getPort());
beatInfo.setCluster(instance.getClusterName());
beatInfo.setWeight(instance.getWeight());
beatInfo.setMetadata(instance.getMetadata());
beatInfo.setScheduled(false);
beatReactor.addBeatInfo(NamingUtils.getGroupedName(serviceName, groupName), beatInfo);
}
serverProxy.registerService(NamingUtils.getGroupedName(serviceName, groupName), groupName, instance);
}
前面一大段代码是对临时服务实例的处理,就是在构造一个心跳包发送给NACOS服务。
registerService方法就是封装了HTTP请求,最终在InstanceController中处理请求。
如果项目集成了spring-cloud-starter-alibaba-nacos-discovery,服务启动后默认是自动注册的。如果想看自动注册的过程,可以从AbstractAutoServiceRegistration开始着手,当中有一段代码:
@EventListener(WebServerInitializedEvent.class)
public void bind(WebServerInitializedEvent event) {
ApplicationContext context = event.getApplicationContext();
if (context instanceof ConfigurableWebServerApplicationContext) {
if ("management".equals(
((ConfigurableWebServerApplicationContext) context).getServerNamespace())) {
return;
}
}
this.port.compareAndSet(0, event.getWebServer().getPort());
this.start();
}
监听了Web服务初始化完成的事件,最终会执行start方法:
public void start() {
if (!isEnabled()) {
if (logger.isDebugEnabled()) {
logger.debug("Discovery Lifecycle disabled. Not starting");
}
return;
}
// only initialize if nonSecurePort is greater than 0 and it isn't already running
// because of containerPortInitializer below
if (!this.running.get()) {
register();
if (shouldRegisterManagement()) {
registerManagement();
}
this.context.publishEvent(new InstanceRegisteredEvent<>(this, getConfiguration()));
this.running.compareAndSet(false, true);
}
}
其中,register方法就是最核心的部分了,来源于NacosServiceRegistry的实现:
@Override
public void register(NacosRegistration registration) {
if (!registration.isRegisterEnabled()) {
logger.info("Nacos Registration is disabled...");
return;
}
if (StringUtils.isEmpty(registration.getServiceId())) {
logger.info("No service to register for nacos client...");
return;
}
NamingService namingService = registration.getNacosNamingService();
String serviceId = registration.getServiceId();
Instance instance = new Instance();
instance.setIp(registration.getHost());
instance.setPort(registration.getPort());
instance.setWeight(registration.getRegisterWeight());
instance.setClusterName(registration.getCluster());
instance.setMetadata(registration.getMetadata());
try {
namingService.registerInstance(serviceId, instance);
logger.info("nacos registry, {} {}:{} register finished", serviceId, instance.getIp(), instance.getPort());
}catch (Exception e) {
logger.error("nacos registry, {} register failed...{},", serviceId, registration.toString(), e);
}
}
这段代码就非常熟悉了,最终就回到了上述的namingService.registerInstance方法。
/**
* Map<namespace, Map<group::serviceName, Service>>
*/
private Map<String, Map<String, Service>> serviceMap = new ConcurrentHashMap<>();
以上出现了另外一个实体类:com.alibaba.nacos.naming.core.Service,Service是包含了Instance,一个Service下有多个Instance,即可组成一个Cluster。
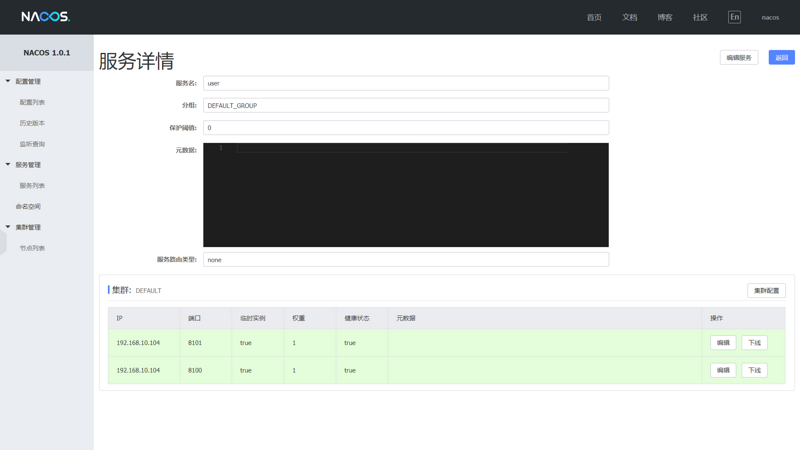
在调用registerInstance注册实例的时候,如果发现对应的Service没有被注册,那么会registerService,并且会初始化对应的Cluster,启动健康检查的定时器。
和registerInstance相反的是deregisterInstance,即为取消注册,也可以认为是服务实例下线。
最后来看看NACOS如何实现服务发现功能。
从消费者(调用方)的角度来看,集成的starter项目中有个类:NacosServerList,最重要的是继承了AbstractServerList,实现了两个关键的接口方法,相当于是NACOS与Ribbon的对接点。
public interface ServerList<T extends Server> {
public List<T> getInitialListOfServers();
/**
* Return updated list of servers. This is called say every 30 secs
* (configurable) by the Loadbalancer's Ping cycle
*
*/
public List<T> getUpdatedListOfServers();
}
NACOS对于这个两个接口的实现,都使用了getServers方法,而进入到getServers方法体里面,其实就是利用了上述所说的NacosNamingService.selectInstances方法,通过serviceId获取到ServiceInfo对象,然后获取到Service下面的所有有效的Instance。
从提供者(被调用方)的角度看,NACOS是通过定时器来实时更新ServiceInfo,主要业务逻辑是在HostReactor中实现的。与前述的serviceMap不一样,HostReactor中维护的是serviceInfoMap。
private Map<String, ServiceInfo> serviceInfoMap;
HostReactor借助了FailoverReactor对ServiceInfo做了磁盘缓存,仍然是启动了定时任务,在指定的目录下序列化ServiceInfo,以此实现了Failover机制。而启动failover-mode也是有开关的,其实就是一个特定文件的一部分内容,这些配置的监测也是通过定时任务来实现的。
File switchFile = new File(failoverDir + UtilAndComs.FAILOVER_SWITCH);
整个过程如下图所示:

四、管理控制台(Console)
这一部分是管理控制台的实现,其实是一个非常典型的WEB项目。
使用了Spring Security + JWT进行安全控制,前端技术是ReactJs,利用JdbcTemplate进行数据库持久化。
需要注意的是,控制台提供的功能并不都是从nacos-console这个服务中获取的数据,而是分散在了各个服务中。
nacos-console提供了控制台登录,namespace管理,控制台服务状态这三部分能力,而配置管理和服务管理分别请求的是nacos-config和nacos-naming所提供的API,而这些API就是官网所提到的Open-API。
五、总结
NACOS相关源码通俗易懂,没有什么高深的理念,也没有进行层层封装和包裹,有一定编程经验的程序员能在半小时之内把握整个项目的脉络。
当然,也会存在一些不可忽视的缺点,比如,注释过少,代码还有很大的重构空间,tenant和namespace两个概念混淆使用。
关于Spring Cloud Alibaba Nacos的介绍到此就结束了,希望对你有所帮助。
扫描下方二维码,进入原创干货,搞“技”圣地。

正文到此结束
- 本文标签: equals tk 源码 突破 配置 代码 解析 参数 lib ACE Service 模型 ArrayList 并发 web js map GitHub 程序员 阿里云 client 删除 Property Spring Security ConcurrentHashMap Agent update https 安全 API App 二维码 build http Atom id HashMap Reactor spring git 集群 管理 CTO list example ECS Security 希望 服务注册 缓存 目录 struct cat Bootstrap CEO value 同步 ask message IO ribbon Proxy 云 ip 线程 IDE 空间 key 开源 DDL 线程池 executor Spring cloud JDBC 数据库 数据 注释 实例 总结 core Listeners cache 静态方法 db tar UI 时间 Select final src 文章 constant bug
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

