Java性能 -- ArrayList + LinkedList
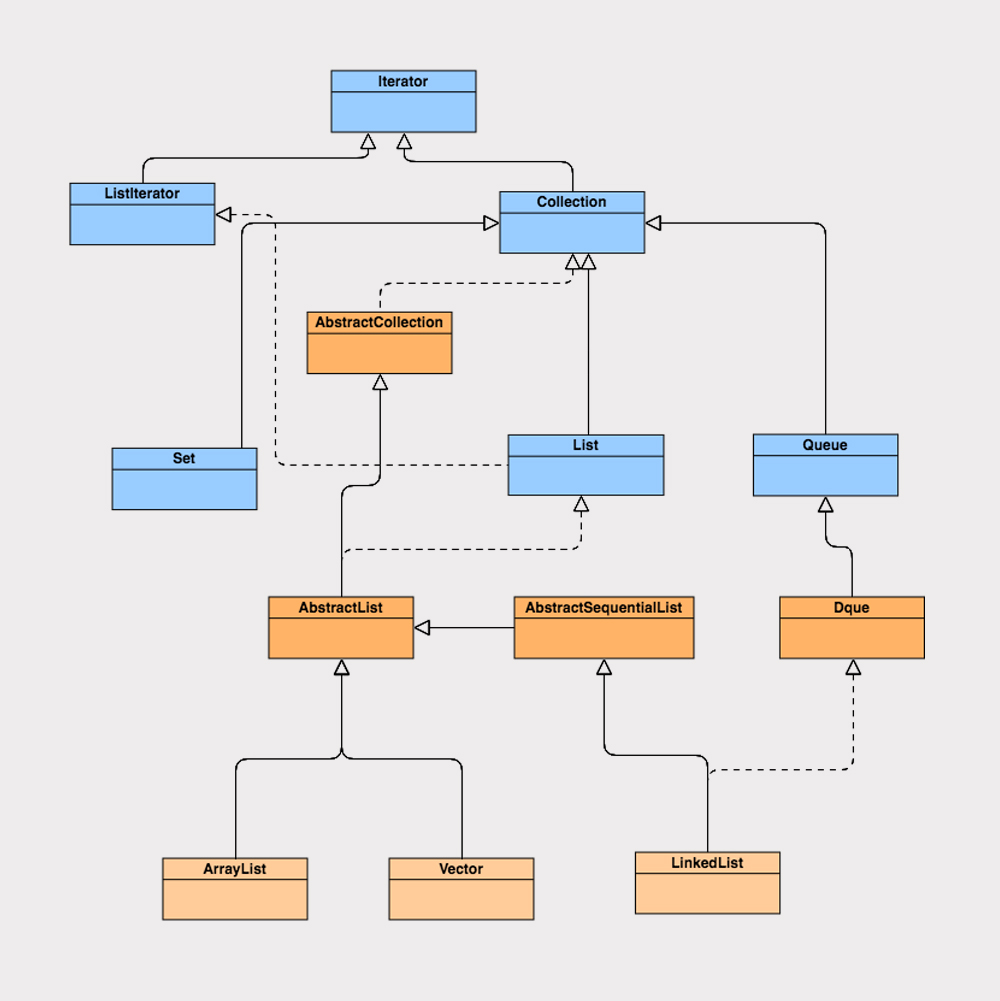
- ArrayList、Vector、LinkedList继承了AbstractList,AbstractList实现了List,同时继承了AbstractCollection
- ArrayList和Vector使用了 数组 实现,LinkedList使用了 双向链表 实现
ArrayList
常见问题
- ArrayList的对象数组elementData使用了 transient (表示不会被序列化)修饰,为什么?
- ArrayList在大量新增元素的场景下,效率一定会变慢?
- 如果要循环遍历ArrayList,采用 for循环 还是 迭代循环 ?
类签名
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
}
- ArrayList实现了List接口,继承了AbstractList抽象类,底层是 数组 实现,并且实现了 自增扩容
- ArrayList实现了Cloneable和Serializable接口,可以实现 克隆 和 序列化
- ArrayList实现了RandomAccess接口,RandomAccess接口是一个 标志 接口,可以实现 快速随机访问
属性
// 默认初始化容量 private static final int DEFAULT_CAPACITY = 10; // 对象数组 transient Object[] elementData; // 数组长度 private int size; private void writeObject(java.io.ObjectOutputStream s) private void readObject(java.io.ObjectInputStream s)
- transient关键字修饰elementData,表示elementData不会被序列化,而ArrayList又实现了Serializable接口,这是为什么?
- 由于ArrayList的数组是 动态扩容 的,所以并不是所有被分配的内存空间都存储了数据
- 如果采用 外部序列化 实现数组的序列化,会序列化 整个数组
- ArrayList为了避免这些没有存储数据的内存空间被序列化
- 内部提供了两个私有方法 writeObject 和 readObject ,来自我完成序列化和反序列化,节省了 空间 和 时间
- 因此使用transient关键字修饰对象数组,是防止对象数组被其他外部方法序列化
构造函数
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 指定合理的初始大小,有助于减少数组的扩容次数,提供系统性能
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
}
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
新增元素
// 直接将元素添加到数组的末尾
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
// 如果一开始就指定了合理的初始大小,不会发生动态扩容,添加元素,只需要在数组末尾添加元素,性能也会很好
// ArrayList在大量新增元素的场景下,效率一定会变慢? -- 不一定,看场景
elementData[size++] = e;
return true;
}
// 添加元素到任意位置
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
// 数组拷贝
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
// 如果容量不够大,会按原来数组的1.5倍大小进行扩容
// 在扩容之后需要将数组复制到新分配的内存地址
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
删除元素
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
// 数组重组,删除的元素位置越靠前,数组重组的开销就越大
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
// 遍历数组
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
// 同样也要数组重组
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
}
获取元素
// ArrayList是基于数组实现的,所以在获取元素的时候非常快
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
LinkedList
LinkedList是基于 双向链表 实现的,LinkedList种定义了一个Node结构
// 1. 清晰地表达了链表中链头和链尾概念
// 2. 在链头和链尾的插入删除操作更加快捷
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
类签名
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
}
- LinkedList实现了List接口和Deque接口,同时继承了AbstractSequentialList抽象类
- LinkedList实现了Cloneable和Serializable接口,可以实现 克隆 和 序列化
- LinkedList存储数据的内存地址是 非连续 的,只能通过 指针 来定位
- 因此LinkedList 不支持随机快速访问 ,也不能实现RandomAccess接口
属性
// LinkedList也实现了自定义的序列化和反序列化 transient int size = 0; transient Node<E> first; transient Node<E> last; private void writeObject(java.io.ObjectOutputStream s) private void readObject(java.io.ObjectInputStream s)
新增元素
// 添加到队尾
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
// 从链头或者链尾查找元素
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
删除元素
// 从链头或者链尾查找元素
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
获取元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
- for循环遍历时,每次循环都会遍历半个List,效率非常低
- 因此在循环遍历LinkedList时,采用iterator方式迭代循环,效率更高,直接拿到元素,而不需要通过循环查找List
性能测试
新增元素
| 头部 | 中间 | 尾部 | |
|---|---|---|---|
| ArrayList | 1660 | 769 | 17 |
| LinkedList | 15 | 9463 | 14 |
LinkedList新增元素的效率未必高于ArrayList
删除元素
| 头部 | 中间 | 尾部 | |
|---|---|---|---|
| ArrayList | 1235 | 559 | 5 |
| LinkedList | 14 | 6349 | 5 |
遍历元素
| For Loop | Iterator Loop | |
|---|---|---|
| ArrayList | 97 | 73 |
| LinkedList | 371 | 251 |
LinkedList切忌使用for循环遍历
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

