工具类算法--快排的优化(Java)
快速排序(quick sort)是算法题中经常遇到的工具类算法,所谓工具类算法就是存在很多的算法或者思考题是基于相同思想进行解答的,那么这类算法被考察的概率很高,对于这类算法的思考和探究也就十分有意义!
快排也是在实践中应用非常广泛的一种排序算法, 特别是在C++或对Java基本类型的排序中特别有效 。
为什么说是基本类型?这是在对比归并排序(merge sort)和快排时经常提的问题,原因在于两种排序方式各自的特点:
快速排序(quick sort)元素移动次数少,元素比较次数多;
归并排序(merge sort)元素移到次数多,元素比较次数最少。
而算法的运行时间耗费在:
1)比较元素;
2)移动元素。
所以快排更加适用于比较成本较低的基本类型,而对于耗时较长的泛型比较,例如实现comparator接口,就该考虑使用比较次数较少的归并排序了。
它的平均运行时间是 ,但是不稳定,它的最坏情形时间复杂度为 ,但是这种不稳地是可以通过对算法的优化避免的,接下来就讨论对算法的优化问题。
常见写法
public static void QSort(int[] a, int left, int right) {
if(left >= right) {
return;
}
//选择最左边元素为基线值
int base = a[left];
int i = left;
int j = right;
//移动元素使得基线值
while(i < j) {
//左移放前面
while(i < j && base <= a[j]) {
j--;
}
//右移
while(i < j && base >= a[i]) {
i++;
}
if(i < j) {
swap(a, i, j);
}
}
//交换base和比base小的最后一个元素的值
swap(a, left, i);
QSort(a, left, i-1);//左边递归
QSort(a, i+1, right);
}
复制代码
快排是一种分治的递归算法,描述这种最常见的快排实现方式, 对数组 进行排序的基本算法由下面4步组成:
- 如果 中的元素个数为0或者1,则返回;
- 取 中的任意元素 ,称为 枢纽元 (pivot),上面实现采用的是数组的第一个元素作为枢纽元;
- 将数组除 的剩余部分划分为两个不相交的集合 ,一个由大于等于 的元素组成,一个由小于等于 的元素组成;
- 对集合 重复前面步骤,递归进行快排。
快排的过程参考下面GIF:
不平衡的问题的出现
前面提到快排存在不平衡的情况,但是这种不平衡可以通过对算法的优化来解决。那什么时候会引起不平衡的情况?
1)枢纽元选取引起
快速排序的性能高度依赖于枢纽元的选择,对于常见写法中 选择第一个元素 作为枢纽元的策略是极其危险的,如果输入的是预排序或者是反排序的,那么枢纽元会产生极其不平衡的分割---元素全在 集合或者元素全划分到 集合。
并且这种糟糕的情况会发生在所有的递归中,这种不平衡情况时间耗费是 ,更为尴尬的是如果选取第一个元素作为枢纽元且输入是预先排序,时间消耗是二次的,但是结果却是什么也没做。
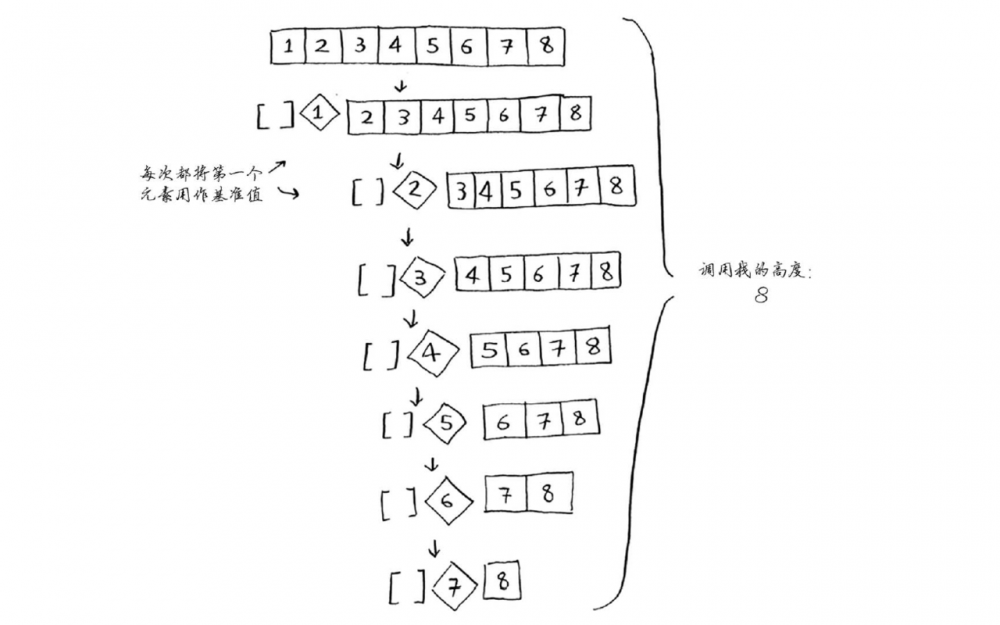
测试用例: Leetcode 217.存在重复元素

这道题解题思路十分简单,先对整数数组进行快排,然后再判断排序后的数组的相邻元素是否相等,就可以得到解答,可以看出这也是一道可以使用快排算法的题。
public boolean containsDuplicate(int[] nums) {
if (nums == null) {
return false;
}
QSort(nums, 0, nums.length - 1);
for (int i = 0; i < nums.length; i++) {
if (i + 1 < nums.length && nums[i] == nums[i + 1]) {
return true;
}
}
return false;
}
复制代码
当按照常见写法完成快排时,会发现这道题的最后一个测试用例是一个庞大的预先排序的整数数组,会导致超时,这就是由于不平衡导致的二次时间引起的超时。
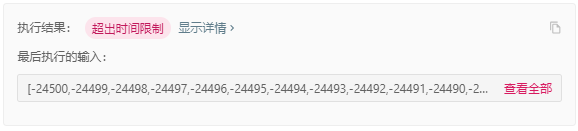
这种不平衡的情况会在后面枢纽元的选择的优化中进行处理。
2)分割策略引起
我们再考虑由分割策略引起的不平衡,将快排步骤中的第三步元素的比较和交换的策略称为 分割策略 ,可以理解为将数组按照与枢纽元大小关系分割成两个不相交子数组的策略,如下图:
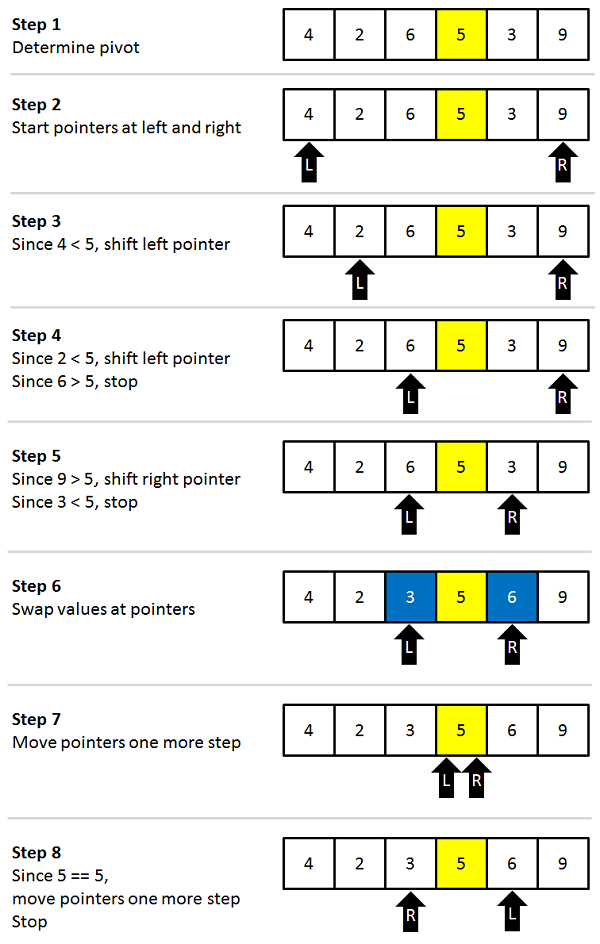
图中的枢纽元为5,分割结果为5的左边为小于5的数右边为大于5的数。需要注意到数组中所有的 元素互异 ,而 分割策略的优化着重考虑的是数组中出现重复元素该怎么办 。
最优的分割策略,我们期待是将数组分割为元素个数相近的两个子数组,而坏的分割策略则会产生不均衡的两个子数组,即出现不平衡问题,极端情况结果就和预先排序且选取第一个元素作为枢纽元时的相同,时间复杂度 。
我们考虑一种极端情况,当数组所有元素的值都相等的情况,以常见写法为例,查看算法的分割策略:
//左移
while(i < j && base <= a[j]) {
j--;
}
//右移
while(i < j && base >= a[i]) {
i++;
}
复制代码
首先R指针左移寻找到第一个小于枢纽值的元素,注意:对于和枢纽元相同的元素采用的策略是不停(遇到相等元素时继续移动),所以右移会一直左移直到 L == R 结束,如下图所示:
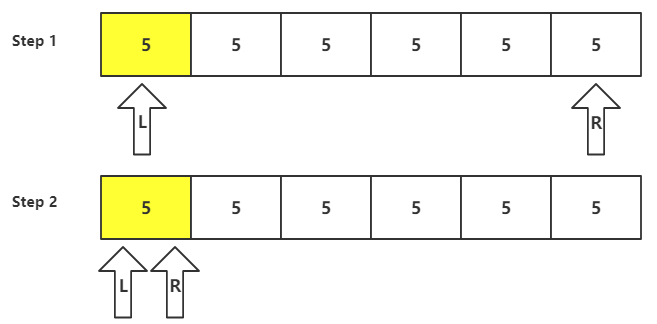
结果很明显,子数组 为空, 包含除了枢纽元外的其余5个元素,是极不均衡的分割策略。
枢纽元的选择的优化
从上面描述的算法来看,枢纽元存在多种选择,无论选择数组内的哪个元素都能完成排序工作,但是前面也提到一些坏的选择会导致不平衡的问题,接下来讨论如下几种选择:
- 一种错误的方法
这种错误的选取方式就是把第一个元素或者最后一个元素用作枢纽元,如果输入的数组是随机的,那么这是可以接受的,但是如果输入是预排序或者是反序的,则会产生不平衡的问题,时间复杂度上升到 。
这种方法产生的糟糕结果在前面给出的 Leetcode 算法题中已经体现,会产生算法超时,所以我们应该避免这种方法。
- 一种安全的方法
一种安全的方针是随机选取枢纽元,一般来说这种策略非常安全,除非随机数发生器有问题,因为随机的枢纽元不可能总在连续不断的产生劣质的分割。但是随机数的生成一般开销很大有点得不偿失。
- 三数中值分割法 稍作思考,最优的枢纽元应该是将数组分成两个元素个数相近的子数组,其实也就是数组元素的中位数,即 最优枢纽元是中位数 ,但是如果每一次选取的时候都计算出数组的中位数,又需要耗费大量时间,显然也不可取。
在综合考虑后,提出一种中值估计的方法---- 三数中值分割法 ,基本思路是: 使用左端,右端和中心位置上的三个元素的中值作为枢纽元 ,其实是对中值的估计,选取过程:
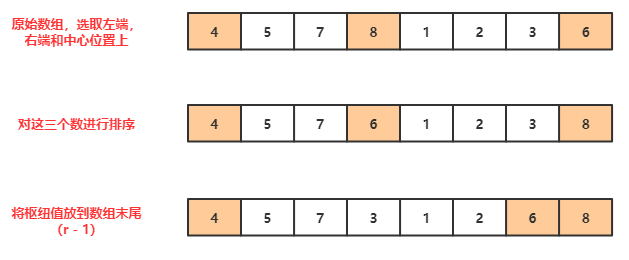
代码实现如下,参数为需要选取枢纽元的数组,返回枢纽元的值。
private int median3(int[] a,int i,int j) {
//对三个数组进行排序
int m = (i + j) >> 1;
if (a[m] < a[i]) {
swap(a, i, m);
}
if (a[j] < a[i]) {
swap(a, i, j);
}
if (a[j] < a[m]) {
swap(a, j, m);
}
//将枢纽值放在j - 1;
swap(a, m, j - 1);
return a[j - 1];
}
复制代码
实现细节:
对左端 a[left] 右端 a[right] 和中心位置 a[center] 的元素进行排序,然后将枢纽元放在 a[right-1] 的位置。
好处一: a[left] 和 a[right] 的位置是分割的正确的位置,所以在后序的需要分割的区间可以缩小到 [left+1,right-2] 。
好处二:枢纽元存储在 a[right-1] 可以充当警戒标记,防止越界。
分割策略的优化
回顾前面由分割策略引起的不平衡, 分割策略的细节在于如何处理那些等于枢纽元的元素 ,问题在于 L 指针和 R 指针在遇到等于枢纽元的元素是否停止,则存在如下三种策略:
-
L指针和R指针都不停; -
L指针和R指针都停; -
L指针和R指针其中一个停,一个不停。
考虑元素全相等的极端情况,显然不停和其中一个停的策略其实结果都是产生不平衡情况,分割结果为极不平衡的两个数组。(参考前面不平衡的分割策略的图)
所以考虑到我们追求的是平衡的一种策略,所以进行不必要的交换建立两个平衡的子数组要比冒险得到两个极不均衡的子数组要好。因此在 LR 遇到等于枢纽元的元素时,让两个指针都停下来,进而避免二次时间的出现。
优化后的快排
public void QSort(int[] a, int left, int right) {
if(left >= right) {
return;
}
//三数中值分割法选取枢纽元
int base = median3(a, left, right);
int i = left;
int j = right - 1;
while(i < j) {
while(i < j && base > a[++i]) {}
while(i < j && base < a[--j]) {}
if(i < j) {
swap(a, i, j);
}
}
swap(a, i, right - 1);
QSort(a, left, i - 1);
QSort(a, i + 1, right);
}
private void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
//三数中值分割法
private int median3(int[] a,int i,int j) {
//对三个数进行排序
int m = (i + j) >> 1;
if (a[m] < a[i]) {
swap(a, i, m);
}
if (a[j] < a[i]) {
swap(a, i, j);
}
if (a[j] < a[m]) {
swap(a, j, m);
}
//将枢纽元放在j - 1;
swap(a, m, j - 1);
return a[j - 1];
}
复制代码
小细节
对比 常见写法 和 优后的快排 ,发现除了前面提到的优化策略外还有一些更改:
例如常见写法中是先 R 指针左移,后 L 指针右移,而优化后的是先 L 指针右移,为什么?
原因:
在常见写法中枢纽元在最左边,右指针左移肯定停在一个小于或等于枢纽元的元素对应的位置(假设为index),紧接着是左指针右移假设一直小于枢纽值,则会停在和右指针相同位置(index),分割的最后一步是将枢纽元和左指针交换,而左指针指向的是一个小于或等于枢纽元的值(即右指针左移停的index),则因为最终分割结果是小于枢纽元的值在左边,所以完全没问题。
再考虑如果在常见写法中,使用左指针先移的策略,那么左指针停的位置是一个大于或等于枢纽元的位置,如果进行最后的左指针和枢纽元的交换,就将一个大于枢纽元的值移到了左边,显然是不可行的。
结论:
所以得出结论: 左右指针的移动顺序是由要交换的枢纽元位置决定的 ,如果枢纽元在左边(常见写法的枢纽元)那么应该将一个小于或等于枢纽元的值和它交换,而右指针先左移肯定得到的是小于或等于枢纽元的值;
而枢纽元在右边的(优化后的枢纽元)那么应该将一个大于或等于枢纽元的值和它交换,所以采用先左移的方案!
可以将优化后的算法再次尝试解决存在不平衡的测试用例的例题: Leetcode 217.存在重复元素 ,执行结果。

References:
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

