Square 现代高效的 HTTP 客户端 okhttp(二):HTTP 请求
作者简介:ASCE1885, 《Android 高级进阶》 [1] 和 《Android 高级进阶(源码剖析篇)》 [2] 作者。
本文由于潜在的商业目的,未经授权不开放全文转载许可,谢谢!
本文分析的源码版本已经 fork 到我的 Github [3] 。

HTTP 客户端的职责简单来说,就是接收使用者发起的 HTTP 请求,接着从服务器拿到数据,最后将响应封装好返回给使用者。理论上很简单,但实现起来可就比较棘手了。
HTTP 协议是以 ASCII 码传输,规范中把 HTTP 请求分为三个部分:状态行、请求消息头、请求消息体。类似于下面这样:
<method> <request-URL> <version>
<headers>
<entity-body>
在 okhttp 中,我们把 HTTP 请求封装为 Request 类,每个请求主要包含四部分内容:
• 请求 URL • 请求方法,例如 GET,POST,PUT 等 • 请求消息头,例如 Content-Length,Content-Type 等 • 请求消息体,指定 Content-Type 的数据流, 不是每个请求都有,要看请求方法和具体接口的需求
比如在 chrome 中使用开发者工具可以看到本专栏的 HTTPS 请求头信息如下所示:
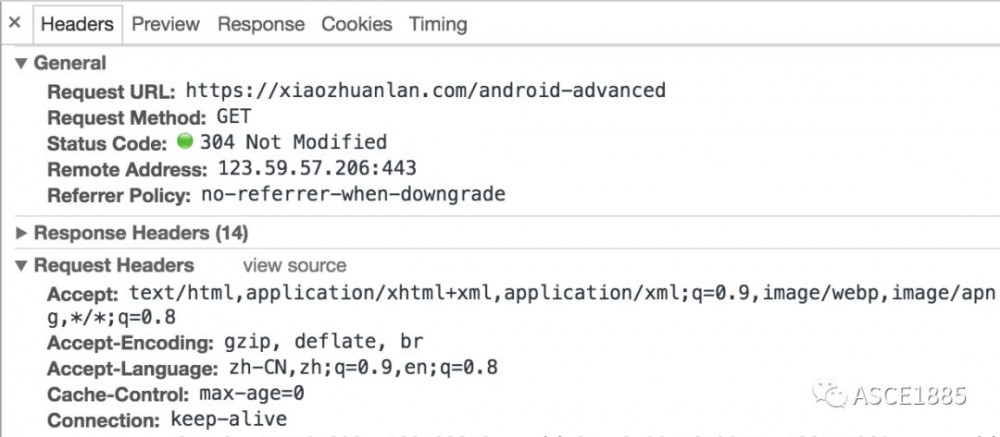
具体到 Request 类,从代码我们可以看到它使用了 Builder 模式 进行实例的构建,本身也是一个 不可变类 ,关于 Builder 模式,可以参考 《Android 高级进阶》 [4] 一书中的具体介绍。
public final class Request {
final HttpUrl url; // 请求 url 地址
final String method; // 请求方法
final Headers headers; // 请求消息头
final @Nullable RequestBody body; // 请求消息体
final Object tag; // 请求标签,非 HTTP 标准中的概念,是 okhttp 中引入的可以用来唯一标识一个 Request 的字段,或者用来存放每个请求特有的数据
Request(Builder builder) {
this.url = builder.url;
this.method = builder.method;
this.headers = builder.headers.build();
this.body = builder.body;
this.tag = builder.tag != null ? builder.tag : this;
}
public Builder newBuilder() {
return new Builder(this);
}
// Builder 通常作为静态内部类存在
public static class Builder {
HttpUrl url;
String method;
Headers.Builder headers;
RequestBody body;
Object tag;
public Builder() {
this.method = "GET"; // 默认请求方法是 GET
this.headers = new Headers.Builder();
}
...
}
}
接下来,我们就按照顺序来介绍 Request 的各部分组成。
请求 URL
请求 URL 是用来定位互联网上任意资源的手段,一个通用的 URL 语法由九部分组成,格式如下所示:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
当然实际应用中,应该很少有 URL 同时拥有这九部分的,大部分都是可选的,最核心的是 scheme,host 和 path,通过下表我们来了解下每部分的含义。
| 名字 | 功能 |
| scheme | 访问服务器时使用何种协议,例如 http,https,ftp 等 |
| user | 访问服务器资源时所需的用户名,常见于 ftp scheme |
| password | 访问服务器资源时所需的密码,和 user 成对出现 |
| host | 服务器的主机名或者点分 IP 地址 |
| port | 当前服务的监听端口号,多数 scheme 都有默认的端口号,例如 HTTP 默认端口号是 80 |
| path | 服务器上资源的本地名,通过斜杆 / 和前面的 URL 组件分隔开 |
| params | 某些 scheme 会使用 params 来指定输入参数,参数为键值对,URL 中如果包含多个参数,那么可以通过分号进行分隔 |
| query | 某些 scheme 会使用 query 来传递参数,query 没有通用的格式,通过字符 ? 和 URL 中其余部分分隔开 |
| frag | 一部分资源的名字,这个字段不会发送给服务器,只是客户端内部自己使用,通过字符 # 与 URL 中其余部分分隔开 |
okhttp 中通过 HttpUrl 类实现 URL 的相关功能, HttpUrl 类也是通过 Builder 模式来构建的,如下所示:
public static final class Builder {
@Nullable String scheme;
String encodedUsername = "";
String encodedPassword = "";
@Nullable String host;
int port = -1;
final List<String> encodedPathSegments = new ArrayList<>();
@Nullable List<String> encodedQueryNamesAndValues;
@Nullable String encodedFragment;
}
可以看到,Buidler 类中的变量和 URL 的组成部分是一一对应的,很好理解。接下来我们就一一介绍这九个部分的构建。
scheme
scheme 的构建很简单,对于 HTTP 客户端来说,它肯定只支持 HTTP 或者 HTTPS 这两种 scheme,因此,在构建时只需要处理这两种 scheme,此外,对于工程代码来说,会有一些防御性代码存在,例如判空操作等,代码如下所示:
public Builder scheme(String scheme) {
if (scheme == null) {
throw new NullPointerException("scheme == null");
} else if (scheme.equalsIgnoreCase("http")) {
this.scheme = "http";
} else if (scheme.equalsIgnoreCase("https")) {
this.scheme = "https";
} else {
throw new IllegalArgumentException("unexpected scheme: " + scheme);
}
return this;
}
username
username 的构建过程主要对其中的特殊字符进行标准化处理,代码如下所示:
public Builder username(String username) {
if (username == null) throw new NullPointerException("username == null");
this.encodedUsername = canonicalize(username, USERNAME_ENCODE_SET, false, false, false, true);
return this;
}
标准化处理在 canonicalize 方法中,该方法的主要功能是对输入的字符串中指定位置的特殊字符进行编码转换,当然不止 username 会用到,很多其他 URL 组件都会用到,它的主要功能有:
• 不对制表符,换行符,换页符,回车符做编码转换 • 在 URL 的 query 组件中,将 ' ' 字符转换为 '+',把 '+' 字符转换为 "%2B" • 对入参 encodeSet 中的字符调用 percentEncoded 方法进行编码 • 控制字符和非 ASCII 字符调用 percentEncoded 方法进行编码 • 所有其他的字符保持不变,不作转换
/**
* 对输入字符串 input 中指定范围 [pos...limit) 中的字符进行标准化编码
*
* @input 需要进行标准化的字符串
* @pos input 的开始位置
* @limit input 的结束位置
* @param alreadyEncoded 为 true 表示不对 '%' 字符作转换,false 表示将 '%' 字符转换为 "%25"
* @param strict 为 true 表示如果 '%' 字符不是一个有效的百分号编码的前缀的话,就将它转换为 "%25"
* @param plusIsSpace 为 true 表示把 '+' 字符转换为 "%2B"
* @param asciiOnly 为 true 表示把所有非 ASCII 码位进行编码
* @param charset 表示使用的字符集,为 null 时表示使用 UTF-8
*/
static String canonicalize(String input, int pos, int limit, String encodeSet,
boolean alreadyEncoded, boolean strict, boolean plusIsSpace, boolean asciiOnly,
Charset charset) {
}
其中,码位(Code Point)是字符的数字表现形式,读者应该还记得我们在 《07 | Twitter 的高性能序列化框架 Serial(三)输入流和输出流》 [5] 一文中有详细介绍过吧?忘了的可以再去回顾一下。
我们知道,ASCII 码中的字符可以分为两类:控制字符和可打印字符。控制字符包含前 32 个字符(0x00~0x1F)和最后一个字符(0x7F),其余的都是可打印字符。因此,我们要作标准化处理的就是控制字符了,对应到代码中就是这句判断:
if (codePoint < 0x20
|| codePoint == 0x7f)
码位大于等于 0x80 的字符,就不再是 ASCII 字符了,而且如果参数 asciiOnly 为 true 时,表示需要对所有非 ASCII 的码位进行编码,对应到代码中就是这句判断:
if (codePoint >= 0x80 && asciiOnly)
参数 encodeSet 表示需要对这个字符串中的所有字符进行编码转换,对应到代码就是这句判断:
if (encodeSet.indexOf(codePoint) != -1)
当码位等于 '%' 字符时,则需要根据两个参数 alreadyEncoded 和 strict 来共同判断,alreadyEncoded 为 true 表示不对 '%' 字符作转换,为 false 表示需要将 '%' 字符转换为 "%25",而参数 strict 为 true 表示如果 '%' 字符不是一个有效的百分号编码的前缀的话,就将它转换为 "%25",而判断字符是否有效的百分号编码的前缀,需要调用方法 percentEncoded 作判断,这一系列判断对应到代码就是这一句:
if (codePoint == '%' && (!alreadyEncoded || strict && !percentEncoded(input, i, limit)))
当码位等于 '+' 时,而且如果参数 plusIsSpace 为 true 时,表示需要把 '+' 字符转换为 "%2B",对应到代码就是这句判断:
if (codePoint == '+' && plusIsSpace)
当码位满足以上任意一个条件时,我们将调用另一个重载的 canonicalize 方法继续对其进行处理,而且会把编码转换后的结果保存到创建的一个 Buffer 实例中,这个 Buffer 类就是我们之前介绍过的 okio 中的 Buffer 。在继续分析具体代码前,我们先来聊聊前面经常出现的 percentEncoded,也就是 百分号编码 ,或者叫 URL 编码 。
首先,我们要弄清楚为什么需要对 URL 中的某些字符进行编码,根本原因是这些字符会引起歧义,例如 URL 组成部分中的 params 是键值对形式,键值对之间以 '&' 分隔,例如 q=0x7f+ASCII&qs=n 。如果值字符串中包含了 '=' 或者 '&' 字符,而且不对其进行转义编码的话,那么肯定会造成服务器解析出错或者导致非预期的结果。
而且,URL 编码格式都是采用 ASCII 码的,而不是 Unicode,因此,我们不能在 URL 中包含任何非 ASCII 字符,包括中文,所以你在访问网站时,如果 URL 中有中文,经常会看到它实际被编码了。例如我们在浏览器中用 Bing 搜索 Android高级进阶 时,原始的 URL 链接中将包含 https://cn.bing.com/search?q=Android高级进阶 ,你把浏览器地址栏中 URL 地址复制出来粘贴文本编辑器中,你会看到,实际上它已经是被 URL 编码转换过的内容: https://cn.bing.com/search?q=Android%E9%AB%98%E7%BA%A7%E8%BF%9B%E9%98%B6 。
因此,URL 编码的原理就是使用安全的字符(例如,没有特殊用途或者特殊含义的可打印字符)来表示不安全的字符。 RFC3986 [6] 文档规定,URL 中只允许包含保留字符和非保留字符两种。
其中 保留字符 是指 URL 中用来表示特殊含义的字符,例如 ':' 字符用于分隔协议和主机,'/' 字符用于分隔主机和路径,'?' 字符用于分隔路径和查询参数等等。RFC 3986 中定义的保留字符有:

其中 非保留字符 则没有特殊含义,RFC 3968 中定义的非保留字符有:

好,我们继续分析前面介绍到的重载的 canonicalize 方法,代码如下所示:
static void canonicalize(Buffer out, String input, int pos, int limit, String encodeSet,
boolean alreadyEncoded, boolean strict, boolean plusIsSpace, boolean asciiOnly,
Charset charset) {
Buffer encodedCharBuffer = null; // Lazily allocated.
int codePoint;
for (int i = pos; i < limit; i += Character.charCount(codePoint)) {
// 遍历每个字符对应的码位
...
}
}
可以看到,还是对输入字符串 input 中的每个字符进行判断并处理。如果参数 alreadyEncoded 为 true(表示不对 '%' 字符作转换),而且字符是制表符('/t'),换行符('/n'),换页符('/f'),回车符('/r')之一时,不对其作编码转换,直接跳过。
if (alreadyEncoded
&& (codePoint == '/t' || codePoint == '/n' || codePoint == '/f' || codePoint == '/r')) {
// 跳过
}
如果字符对应的码位是 '+',且参数 plusIsSpace 为 true 时,表示需要把 '+' 字符转换为 "%2B",代码如下所示:
if (codePoint == '+' && plusIsSpace) {
// Encode '+' as '%2B' since we permit ' ' to be encoded as either '+' or '%20'.
out.writeUtf8(alreadyEncoded ? "+" : "%2B");
}
除此之外,对于符合百分号编码的字符进行转换,代码如下所示:
if (codePoint < 0x20
|| codePoint == 0x7f
|| codePoint >= 0x80 && asciiOnly
|| encodeSet.indexOf(codePoint) != -1
|| codePoint == '%' && (!alreadyEncoded || strict && !percentEncoded(input, i, limit))) {
// Percent encode this character.
if (encodedCharBuffer == null) {
encodedCharBuffer = new Buffer();
}
if (charset == null || charset.equals(Util.UTF_8)) {
encodedCharBuffer.writeUtf8CodePoint(codePoint);
} else {
encodedCharBuffer.writeString(input, i, i + Character.charCount(codePoint), charset);
}
while (!encodedCharBuffer.exhausted()) {
int b = encodedCharBuffer.readByte() & 0xff;
out.writeByte('%');
out.writeByte(HEX_DIGITS[(b >> 4) & 0xf]);
out.writeByte(HEX_DIGITS[b & 0xf]);
}
}
... 更多内容请点击 阅读原文 继续阅读。
References
[1] 《Android 高级进阶》: https://item.jd.com/11999029.html
[2] 《Android 高级进阶(源码剖析篇)》: https://xiaozhuanlan.com/android-advanced
[3] Github: https://github.com/ASCE1885/okhttp/tree/parent-3.10.0
[4] 《Android 高级进阶》: https://item.jd.com/11999029.html
[5] 《07 | Twitter 的高性能序列化框架 Serial(三)输入流和输出流》: https://xiaozhuanlan.com/topic/2896354071
[6] RFC3986: https://tools.ietf.org/html/rfc3986
正文到此结束
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

