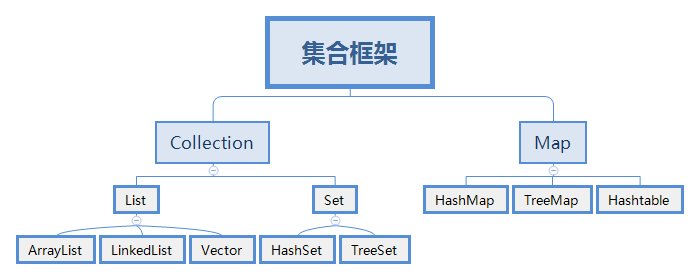
Java集合框架——Set接口
第三阶段 JAVA常见对象的学习
集合框架——Set接口
Set可以理解为行为不同的Collection
(一) 概述及功能
(1) 概述
Collection
- List —— 有序(存储顺序和取出顺序一致),可重复
- Set
—— 无序(存储顺序和取出顺序不一致),唯一
我们首先要清楚有序无序,到底是什么意思?
集合所说的序,是指元素存入集合的顺序,当元素存储顺序和取出顺序一致时就是有序,否则就是无序。
我们一般说的无序是指HashSet,它既不能保证存储和取出顺序一致,更不能保证自然顺序(a-z),而TreeSet 是可以实现自然顺序的。(HashSet的有无序问题可是个大问题,下一篇专篇讲解)
(2) 功能
A:基本功能:(继承而来)
//添加功能 boolean add(E e):如果指定的元素不存在,则将其指定的元素添加(可选操作) boolean addAll(Collection<? extends E> c):将指定集合中的所有元素添加到此集合 //删除功能 void clear():移除集合中的所有元素 boolean remove(Object o):从集合中移除指定的元素 boolean removeAll(Collection<?> c):从集合中移除一个指定的集合元素(有一个就返回true) //长度功能 int size(); //判断功能 boolean isEmpty():判断集合是否为空 boolean contains(Object o):判断集合中是否包含指定元素 boolean containsAll(Collection<?> c):判断集合中是否包含指定的一个集合中的元素 boolean retainAll(Collection<?> c):仅保留该集合中包含在指定集合中的元素 //获取Set集合的迭代器: Iterator<E> iterator(); //把集合转换成数组 Object[] toArray():返回一个包含此集合中所有元素的数组 <T> T[] toArray(T[] a):同上,返回的数组的运行时类型是指定数组的运行时类型
B:特有功能:
//判断元素是否重复,为子类提高重写方法 boolean equals(Object o):将指定的对象与此集合进行比较以实现相等 int hashCode();:返回此集合的哈希码值
Set集合中的方法用法并不难,可以参照前面Collection、List集合的讲解,对照学习,我们重点讲解Set中一些重要的特点。
(二) HashSet
一句话记住它:一种没有重复元素的无序集合
我们先说说无序是怎么回事,HashSet 它不保证 set 的迭代顺序,特别是它不保证该顺序恒久不变,也就是说它的存储顺序和取出顺序不一致,虽然说它无序,但是,作为集合来说,它肯定有它自己的存储顺序,而你的顺序恰好和它的存储顺序一致,这代表不了有序。下一篇专篇讲解这一问题!
无序问题由于篇幅较长,我们先放到另一边
我们先来思考一下,HashSet是如何保证不重复的呢?
通过查看HashSet中add方法的源码
// HashSet 源码节选-JKD8
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
我们可以看到HashSet中add方法所调用的是HashMap中的put方法,我们定位过去
由于解释篇幅较长,直接给出结论,具体源码解释在HashMap源码分析中具体讲解
这个方法底层主要依赖 两个方法:hashCode()和equals()。
- 步骤:
- HashSet方法调用add方法时,调用hashCode(),得到一个哈希值,判断哈希值是否相同。
-
相同:执行equals()方法
返回true:说明元素重复,就不添加
返回false:说明元素不重复,就添加到集合
- 不同:就直接把元素添加到集合
现在大家可能想问一句,只使用hashCode()来判断是否重复可以吗?答案是否定的
我们给出这样一句话:
对象相等则hashCode一定相等,hashCode相等对象未必相等,只有equals返回true,hashCode才相等
- 如果类没有重写这两个方法,默认使用的Object()。一般来说不会相同。
- 而String类重写了hashCode()和equals()方法,所以,它就可以把内容相同的字符串去掉。只留下一个。
- 对于String 类型来说,不用重写 hashCode()方法和equals()方法都可以保证元素的唯一性,但是如果不是Stirng,而是其它自定义的对象就要重写这两个方法才能保证元素的唯一性。
(三) TreeSet
概述:
TreeSet:底层是二叉树结构(红黑树是一种自平衡的二叉树)
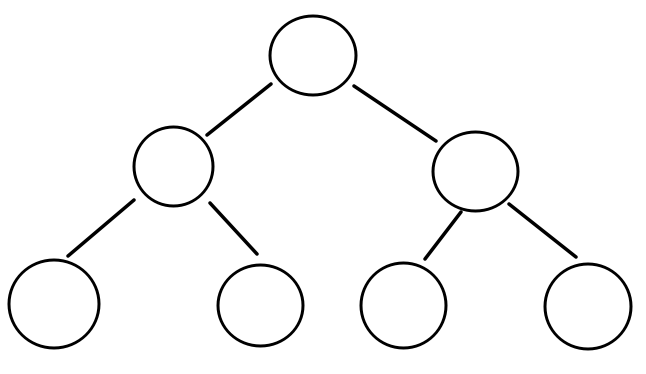
如何存储
那么这一种结构又是如何存储元素的呢?(我们将上图中圆圈称为节点)
- 第一个元素存储的时候,直接作为根节点存储
-
第二个元素开始,每个元素从根节点开始比较
- 若大 则作为右孩子
- 若小 则作为左孩子
- 相等 则不作处理
我们来举一个例子看看:
import java.util.Set;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
Set<Integer> ts = new TreeSet<Integer>();
ts.add(20);
ts.add(18);
ts.add(23);
ts.add(22);
ts.add(17);
ts.add(24);
ts.add(19);
ts.add(18);
ts.add(24);
for (Integer i : ts) {
System.out.print(i + " ");
}
}
}
//运行结果
17 18 19 20 22 23 24
我们使用图片来解释一下上面的代码
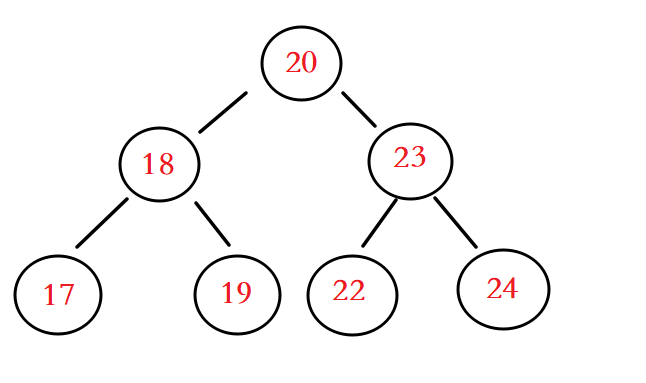
我们将第一个数字20 作为根节点存放,第二个数字18比20小所以放在左边 23大放在右边
例如22这个数字是如何放到如图的位置呢?
首先22先和20比较是大的所以放到右边,接着继续和23进行比较是小的,所以放到23的左边,接下来同理
我们看到运行结果,很神奇的是按照顺序输出的,这也正符合了我们一开始给出的结论:TreeSet 是可以实现自然顺序的
如何取出
那么TreeSet中元素是如何取出来的呢?
从根节点开始,按照左,中,右的原则依次取出元素即可
分析:我们的根节点是20,所以先看左边也就是18,但是下面还有子节点,我们继续看左边所以第一个数字就是17,然后再看中和右也就是18和19,这时候根节点的左边也就全部看完了,所以接着就是中间的根节点20,右边同理。
如何存储自定义对象
我们设定一种场景,存储学生类中的学生对象,并且按照年龄从小到大排序(自然排序)
当满足所有成员变量的值都相同的时候即为同一个元素
注意:如果一个类的元素要想能够进行自然排序,就必须实现自然排序接口(关键)
public class Student implements Comparable<Student> {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '/'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Student s) {
//按照年龄排序
//年龄相同的时候,去看姓名是否也相同
//String 默认实现了Comparavle接口,所以可以直接使用字符串的compareTo方法
int num = this.age - s.age;
int num2 = num == 0 ? this.name.compareTo(s.name) : num;
return num2;
}
}
import java.util.Set;
import java.util.TreeSet;
public class StudentDemo {
public static void main(String[] args) {
Set<Student> ts = new TreeSet<Student>();
Student s1 = new Student("张三",27);
Student s2 = new Student("李四",16);
Student s3 = new Student("王五",40);
Student s4 = new Student("马六",40);
Student s5 = new Student("马六",40);
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
for (Student s : ts){
System.out.println(s);
}
}
}
//运行结果
Student{name='李四', age=16}
Student{name='张三', age=27}
Student{name='王五', age=40}
Student{name='马六', age=40}
我们可以专门定义了一个类MyComparator,其实也可以省略这一个类,直接在TreeSetDemo测试类中定义一个匿名内部类
package cn.bwh_04_TreeSet;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
public class StudentDemo2 {
public static void main(String[] args) {
Set<Student2> ts = new TreeSet<Student2>(new Comparator<Student2>() {
@Override
public int compare(Student2 s1, Student2 s2) {
//姓名长度
int num = s1.getName().length() - s2.getName().length();
//姓名内容
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
//年龄
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2;
return num3;
}
});
Student2 s1 = new Student2("张三", 27);
Student2 s2 = new Student2("李四", 16);
Student2 s3 = new Student2("王五", 40);
Student2 s4 = new Student2("马六", 40);
Student2 s5 = new Student2("马六", 40);
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
for (Student2 s : ts) {
System.out.println(s);
}
}
}
Collection 集合总结
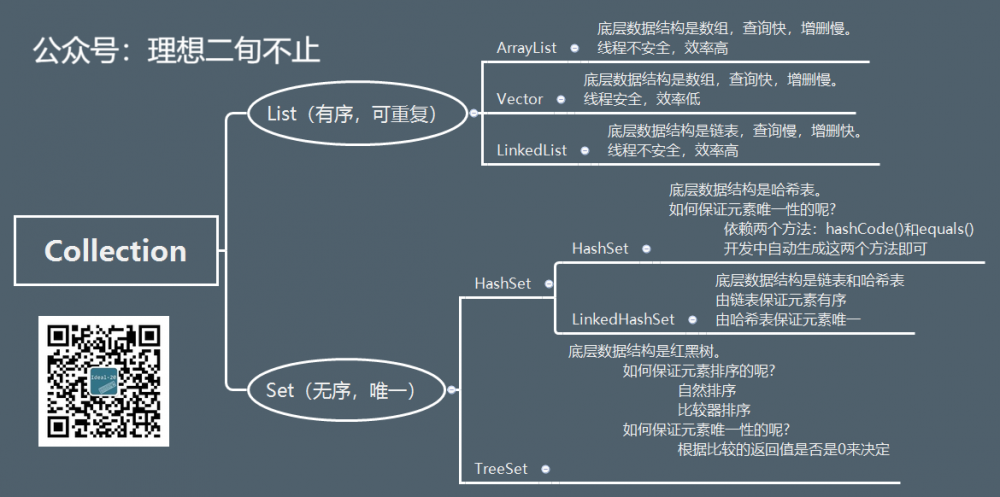
Collection集合应用时的选择
是否唯一
-
唯一:Set
- 需要排序:TreeSet
- 不需要排序:HashSet
- 如果你知道是Set,但是不知道是哪个Set,就用HashSet。
-
不唯一:List
- 需要安全:Vector
- 不需要安全:ArrayList或者LinkedList
- 查询多:ArrayList
- 增删多:LinkedList
如果三原则
如果你知道是List,但是不知道是哪个List,就用ArrayList。
如果你知道是Collection集合,但是不知道使用谁,就用ArrayList。
如果你知道用集合,就用ArrayList。
在集合中常见的数据结构
ArrayXxx:底层数据结构是数组,查询快,增删慢
LinkedXxx:底层数据结构是链表,查询慢,增删快
HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals()
TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序
结尾:
如果内容中有什么不足,或者错误的地方,欢迎大家给我留言提出意见, 蟹蟹大家 !^_^
如果能帮到你的话,那就来关注我吧!(系列文章均会在公众号第一时间更新)
一个坚持推送原创Java技术的公众号:理想二旬不止

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

