Spring 注解编程之 AnnotationMetadata
在上篇文章 Spring 注解编程之模式注解 中我们讲到 Spring 模式注解底层原理,依靠 AnnotationMetadata 接口判断是否存在指定元注解。
这篇文章我们主要深入 AnnotationMetadata ,了解其底层原理。
Spring 版本为 5.1.8-RELEASE
Table of Contents generated with DocToc
- AnnotationMetadata 结构
- AnnotationMetadataReadingVisitor
- AnnotationMetadataReadingVisitor#getMetaAnnotationTypes 源码解析
- StandardAnnotationMetadata
AnnotationMetadata 结构
使用 IDEA 生成 AnnotationMetadata 类图,如下:
__ 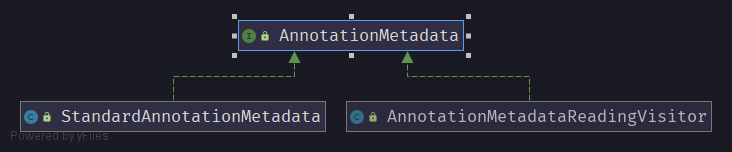
AnnotationMetadata 存在两个实现类分别为 StandardAnnotationMetadata 与 AnnotationMetadataReadingVisitor 。 StandardAnnotationMetadata 主要使用 Java 反射原理获取元数据,而 AnnotationMetadataReadingVisitor 使用 ASM 框架获取元数据。
Java 反射原理大家一般比较熟悉,而 ASM 技术可能会比较陌生,下面主要篇幅介绍 AnnotationMetadataReadingVisitor 实现原理。
基于 AnnotationMetadata#getMetaAnnotationTypes 方法,查看两者实现区别。
AnnotationMetadataReadingVisitor
ASM 是一个通用的 Java 字节码操作和分析框架。它可以用于修改现有类或直接以二进制形式动态生成类。 ASM 虽然提供与其他 Java 字节码框架如 Javassist , CGLIB 类似的功能,但是其设计与实现小而快,且性能足够高。
Spring 直接将 ASM 框架核心源码内嵌于 Spring-core 中,目前 Spring 5.1 使用 ASM 7 版本。
ASM 框架简单应用
Java 源代码经过编译器编译之后生成了 .class 文件。
Class文件是有8个字节为基础的字节流构成的,这些字节流之间都严格按照规定的顺序排列,并且字节之间不存在任何空隙,对于超过8个字节的数据,将按 照Big-Endian的顺序存储的,也就是说高位字节存储在低的地址上面,而低位字节存储到高地址上面,其实这也是class文件要跨平台的关键,因为 PowerPC架构的处理采用Big-Endian的存储顺序,而x86系列的处理器则采用Little-Endian的存储顺序,因此为了Class文 件在各中处理器架构下保持统一的存储顺序,虚拟机规范必须对起进行统一。
Class 文件中包含类的所有信息,如接口,字段属性,方法,在内部这些信息按照一定规则紧凑排序。ASM 框会以文件流的形式读取 class 文件,然后解析过程中使用观察者模式(Visitor),当解析器碰到相应的信息委托给观察者(Visitor)。
使用 ASM 框架首先需要继承 ClassVisitor ,完成解析相应信息,如解析方法,字段等。
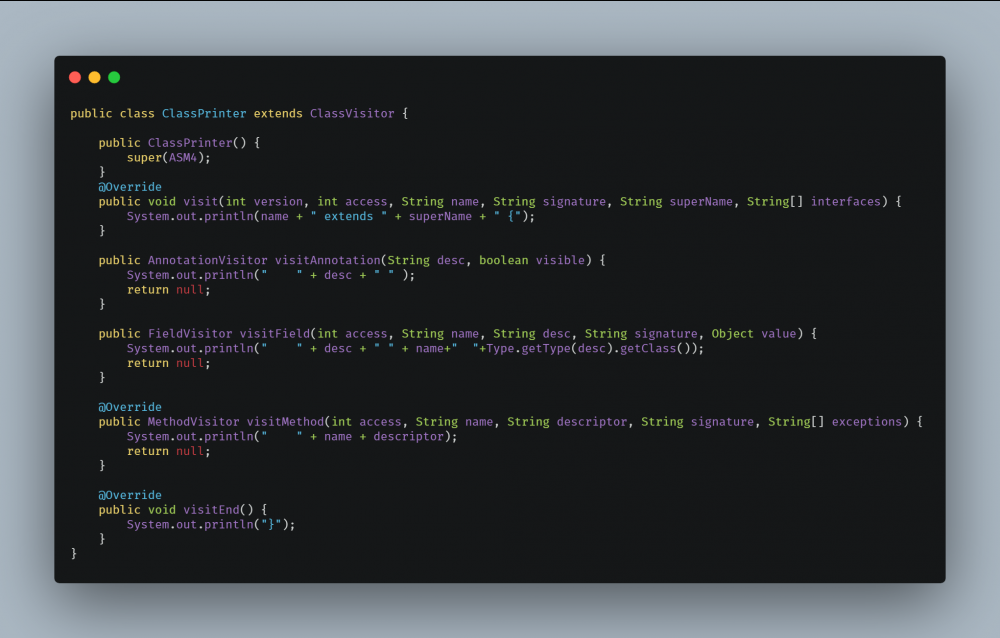
然后使用 ClassReader 读取类文件,然后再使用 ClassReader#accpet 接受 ClassVisitor 。
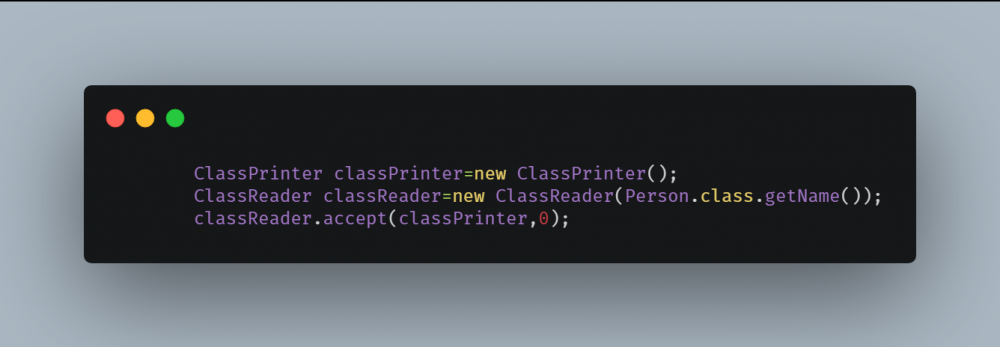
输出结果为:
com/spring/learning/customizescanning/asm/Person extends java/lang/Object {
Lcom/spring/learning/customizescanning/asm/ASMAnnotation;
Ljava/lang/String; name class org.objectweb.asm.Type
I age class org.objectweb.asm.Type
<init>()V
add(II)I
getName()Ljava/lang/String;
setName(Ljava/lang/String;)V
getAge()I
setAge(I)V
}
可以看到 ClassVisitor 相应方法可以用来解析类的相关信息,这里我们主要关注解析类上注解信息。解析注解将会在 ClassVisitor#visitAnnotation 完成解析。 该方法返回了一个 AnnotationVisitor 对象,其也是一个 Visitor 对象。后续解析器会继续调用 AnnotationVisitor 内部方法进行再次解析。
以上实现采用 ASM Core API ,而 ASM 框架还提供 Tree API 用法。具体用法参考: https://asm.ow2.io/
AnnotationMetadataReadingVisitor#getMetaAnnotationTypes 源码解析
AnnotationMetadataReadingVisitor#getMetaAnnotationTypes 方法实现非常简单,直接从 metaAnnotationMap 根据注解类名称获取其上面所有元注解。注解相关信息解析由 AnnotationMetadataReadingVisitor#visitAnnotation 完成。
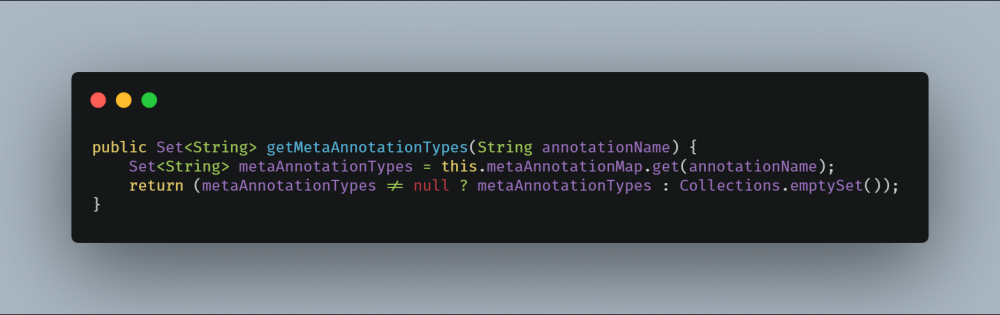
在 visitAnnotation 方法中, metaAnnotationMap 当做构造参数传入了 AnnotationAttributesReadingVisitor 对象中, metaAnnotationMap 会在这里面完成赋值。
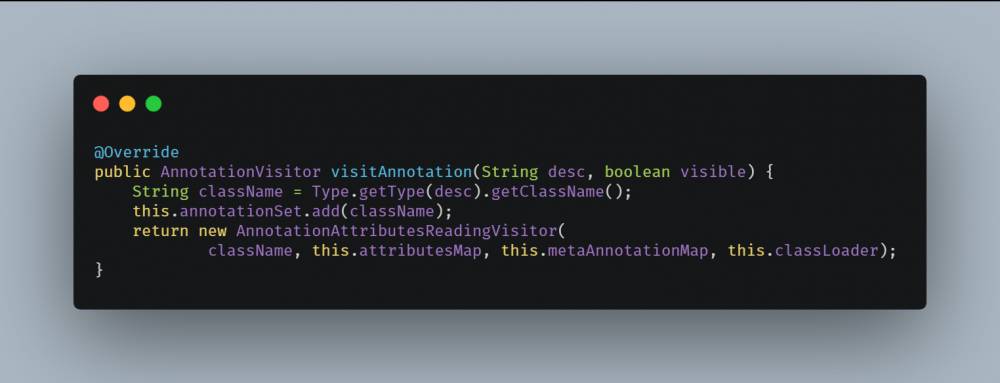
AnnotationAttributesReadingVisitor#visitEnd 将会排除 java.lang.annotation 下的注解,然后通过递归调用 recursivelyCollectMetaAnnotations 获取元注解,不断将元注解置入 metaAnnotationMap 中。
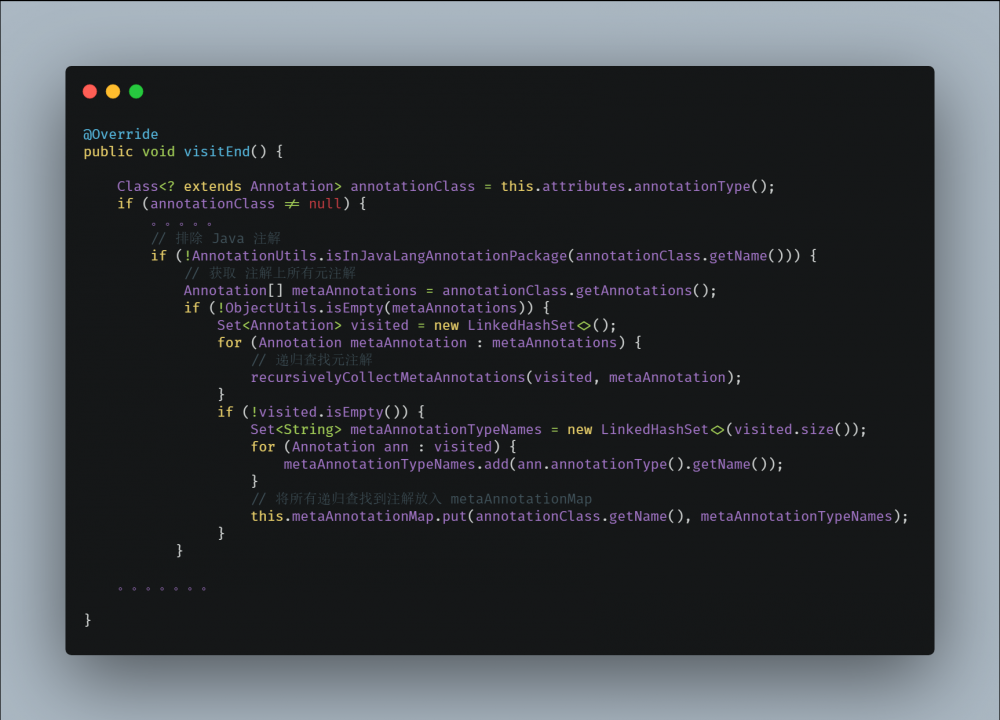
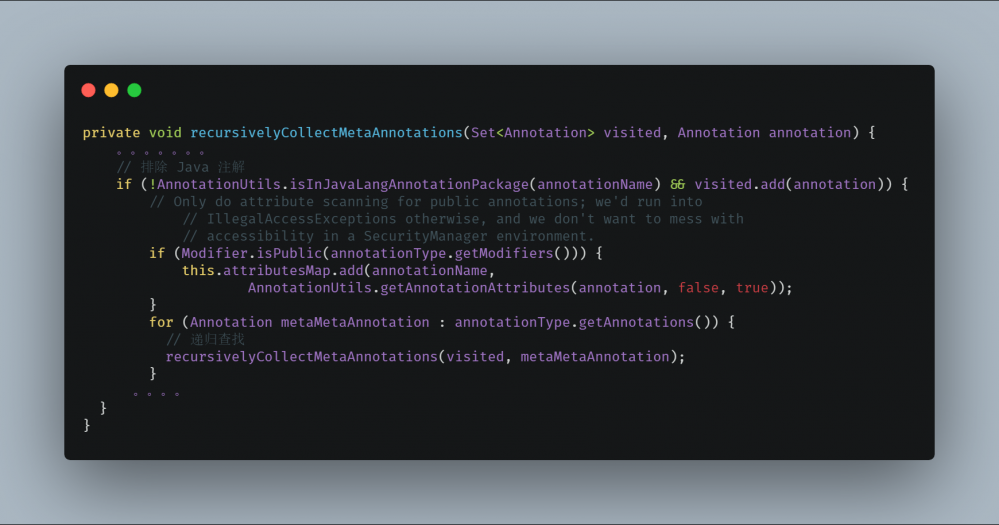
最后使用 UML 时序图中,概括以上调用流程。

Spring 4 之后版本才有递归查找元注解的方法。各位同学可以翻阅 Spring3 的版本作为比较,可以看出 Spring 的代码功能也是逐渐迭代升级的。
StandardAnnotationMetadata
StandardAnnotationMetadata 主要使用 Java 反射原理获取相关信息。在 Spring 中封装很多了反射工具类用于操作。
StandardAnnotationMetadata#getMetaAnnotationTypes 通过使用 Spring 工具类 AnnotatedElementUtils.getMetaAnnotationTypes 方法获取。源码调用比较清晰,各位同学可以自行翻阅理解,可以参考下面时序图理解,这里不再叙述。
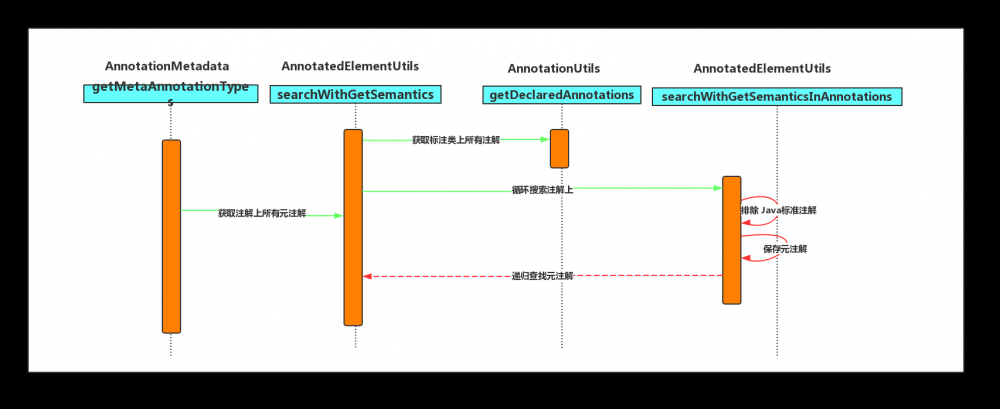
总结
本文介绍了 AnnotationMetadata 两种实现方案,一种基于 Java 反射,另一种基于 ASM 框架。
两种实现方案适用于不同场景。 StandardAnnotationMetadata 基于 Java 反射,需要加载类文件。而 AnnotationMetadataReadingVisitor 基于 ASM 框架无需提前加载类,所以适用于 Spring 应用扫描指定范围内模式注解时使用。
扩展阅读
- 实例分析JAVA CLASS的文件结构
- asm 官方文档
- 『Spring Boot 编程思想』-小马哥
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

