经典面试题:为什么 ConcurrentHashMap 的读操作不需要加锁?

扫描下方二维码 试读

专栏详细目录 请移步至文末
-
ConcurrentHashMap的简介
-
get操作源码
-
volatile登场
-
是加在数组上的volatile吗?
-
用volatile修饰的Node
-
总结
我们知道,ConcurrentHashmap(1.8)这个并发集合框架是线程安全的,当你看到源码的get操作时,会发现get操作全程是没有加任何锁的,这也是这篇博文讨论的问题—— 为什么它不需要加锁呢?
ConcurrentHashMap的简介
我想有基础的同学知道在jdk1.7中是采用Segment + HashEntry + ReentrantLock的方式进行实现的
而1.8中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现。
-
JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
-
JDK1.8版本的数据结构更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
-
JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
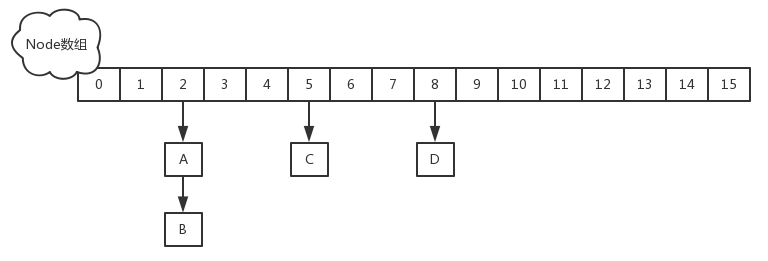
get操作源码
-
首先计算hash值,定位到该table索引位置,如果是首节点符合就返回
-
如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
-
以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
//会发现源码中没有一处加了锁
public V get(Object key) {
Node[] tab; Node e, p; int n, eh; K ek;
int h = spread(key.hashCode()); //计算hash
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) { //读取首节点的Node元素
if ((eh = e.hash) == h) { //如果该节点就是首节点就返回
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//hash值为负值表示正在扩容,这个时候查的是ForwardingNode的find方法来定位到nextTable来
//eh=-1,说明该节点是一个ForwardingNode,正在迁移,此时调用ForwardingNode的find方法去nextTable里找。
//eh=-2,说明该节点是一个TreeBin,此时调用TreeBin的find方法遍历红黑树,由于红黑树有可能正在旋转变色,所以find里会有读写锁。
//eh>=0,说明该节点下挂的是一个链表,直接遍历该链表即可。
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) { //既不是首节点也不是ForwardingNode,那就往下遍历
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
get没有加锁的话,ConcurrentHashMap是如何保证读到的数据不是脏数据的呢?
volatile登场
对于可见性,Java提供了volatile关键字来保证可见性、有序性。但不保证原子性。
普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
-
volatile关键字对于基本类型的修改可以在随后对多个线程的读保持一致,但是对于引用类型如数组,实体bean,仅仅保证引用的可见性,但并不保证引用内容的可见性。
-
禁止进行指令重排序。
背景:为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完不知道何时会写到内存。
-
如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条指令,将这个变量所在缓存行的数据写回到系统内存。
但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。
-
在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议
当某个CPU在写数据时,如果发现操作的变量是共享变量,则会通知其他CPU告知该变量的缓存行是无效的,因此其他CPU在读取该变量时,发现其无效会重新从主存中加载数据
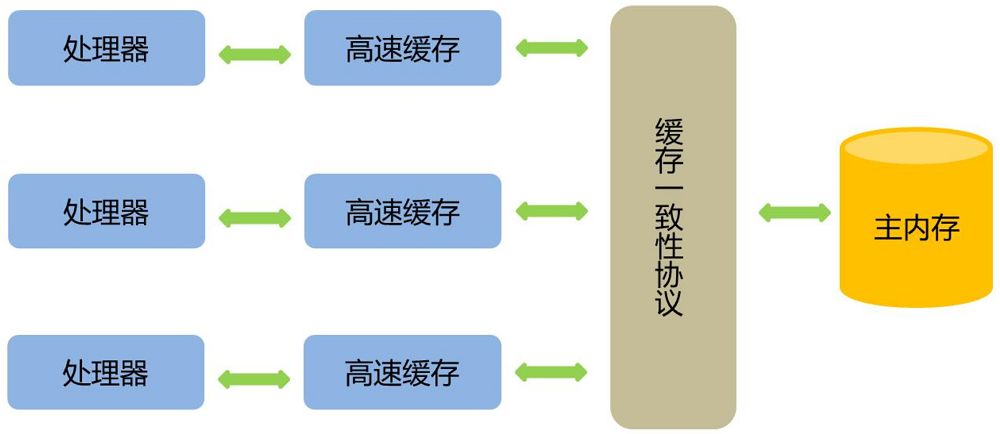
总结下来:
-
使用volatile关键字会强制将修改的值立即写入主存;
-
使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
-
由于线程1的工作内存中缓存变量的缓存行无效,所以线程1再次读取变量的值时会去主存读取
是加在数组上的volatile吗?
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node[] table;
我们知道volatile可以修饰数组的,只是意思和它表面上看起来的样子不同。
举个栗子,volatile int array[10]是指array的地址是volatile的而不是数组元素的值是volatile的.
用volatile修饰的Node
get操作可以无锁是由于Node的元素val和指针next是用volatile修饰的,在多线程环境下线程A修改结点的val或者新增节点的时候是对线程B可见的。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
//可以看到这些都用了volatile修饰
volatile V val;
volatile Nodenext;
Node( int hash, K key, V val, Nodenext) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Nodefind(int h, Object k) {
Nodee = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
既然volatile修饰数组对get操作没有效果那加在数组上的volatile的目的是什么呢?
其实就是为了使得Node数组在扩容的时候对其他线程具有可见性而加的volatile
总结
-
在1.8中 ConcurrentHashMap 的get操作全程不需要加锁,这也是它比其他并发集合比如hashtable、用Collections.synchronizedMap()包装的hashmap;安全效率高的原因之一
-
get操作全程不需要加锁是因为Node的成员val是用volatile修饰的和数组用volatile修饰没有关系。
-
数组用volatile修饰主要是保证在数组扩容的时候保证可见性。
End
作者:上帝爱吃苹果
来源:
https://www.cnblogs.com/keeya/p/9632958.html
本文版权归作者所有
《从 零 开始带你成为 JVM 实战 高手》 详细目录:




为您推荐 :
-
如何设计一个百万级用户的抽奖系统?
-
阿里二面:设计一个电商平台积分兑换系统!
-
扎心一问!你凭什么成为top1%的Java工程师?
-
【干货走一波】千万级用户的大型网站,应该如何设计其高并发架构?
-
PK光明顶?江湖上流传的几大消息队列门派,到底有什么本质区别?
-
扒一扒 JVM 的垃圾回收机制,拿大厂offer少不了它!
-
面试阿里?如果对别人开源的Rocket MQ了如指掌,岂不是很加分?
-
百度、腾讯热门面试题:聊聊Unix与Java的IO模型?(含详细解析)
-
35岁的大龄码农们,如何才能不被社会淘汰掉?
-
一步一图,带你走进Netty的世界!
-
想要去阿里面试?你必须得跨过JVM这道坎!
-
你连Nginx怎么转发给你请求都说不清楚,还好意思说自己不是CRUD工程师?
长按下图二维码,即刻关注【 狸猫技术窝 】
阿里、京东、美团、字节跳动
顶尖技术专家 坐镇
为IT人打造一个 “有温度” 的技术窝!

正文到此结束
- 本文标签: java UI 遍历 重排序 同步 垃圾回收 HashMap 并发 目录 https map 解析 快的 开源 Collection 本质 缓存 node 安全 HTML 美团 苹果 IO 工程师 synchronized tab 京东 CEO 二维码 百度 bean 一致性 JVM unix 网站 IT人 value 总结 处理器 模型 equals 源码 上帝 多线程 key final Word 高并发 索引 协议 线程 Netty Collections 锁 http id ConcurrentHashMap Nginx find 数据 消息队列 volatile src MQ HashTable tk
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

