javac 源码调试教程
一直有读者问我 javac 源码怎么调试,自己也在写 JVM 掘金小册的过程中阅读了大量的 javac 的源码,网上这方面的文章也比较少,那就来写一篇 javac 源码调试的文章吧,作为 javac 系列文章的开篇。
javac 源码调试的过程是比较简单的,它本身就是一个用 Java 语言写的,对我们理解内部逻辑比较友好。
环境搭建过程
环境备注:Intellij、JDK8
1、第一步下载导入 javac 的源码
如果不想从 openjdk 下载折腾,可以跳过第 1 步直接从我的 github 下载: github.com/arthur-zhan…
OpenJDK 的下载方式为: 打开 hg.openjdk.java.net/jdk8/jdk8/l… ,点击左侧的 zip 或者 gz 进行下载。
在 Intellij 中新建一个 javac-source-code-reading 项目,把源码目录的 src/share/classes/com 目录整个拷贝到项目 src 目录下,删掉没用的 javadoc 目录。
2、找到 javac 主函数入口
代码在 src/com/sun/tools/javac/Main.java
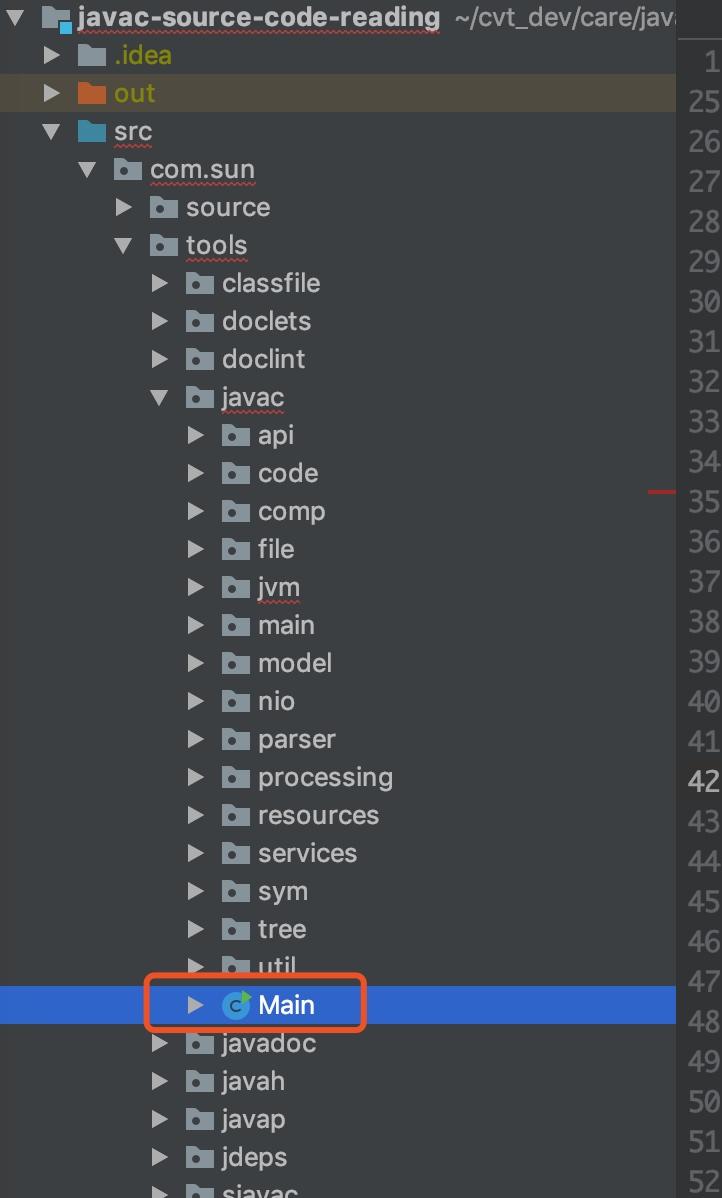
运行这个 main 函数,因为没有加需要编译的源代码路径,不出意外应该会在控制台会输出下面的内容
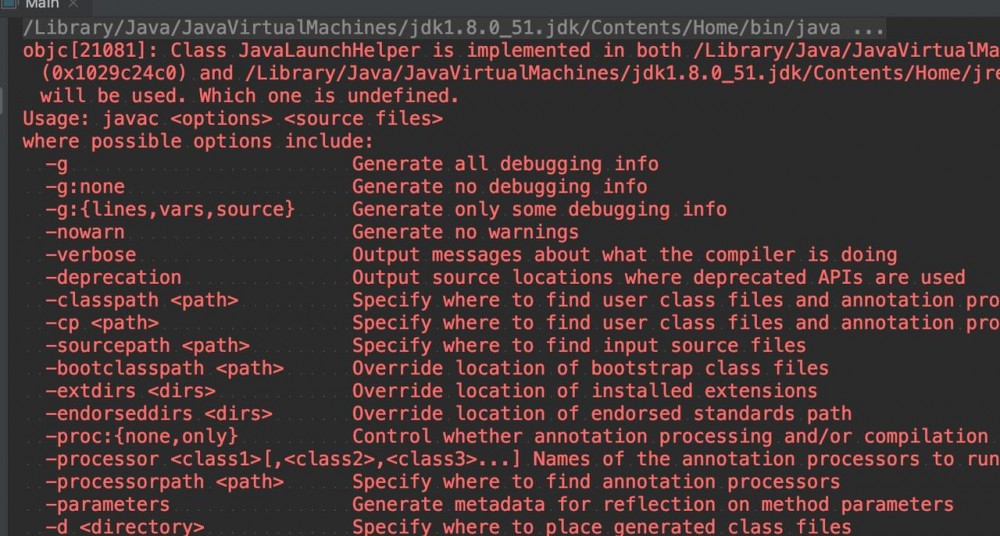
新建一个 HelloWorld.java 文件,内容随缘,在启动配置的 Program arguments 里加入 HelloWorld.java 的绝对路径。
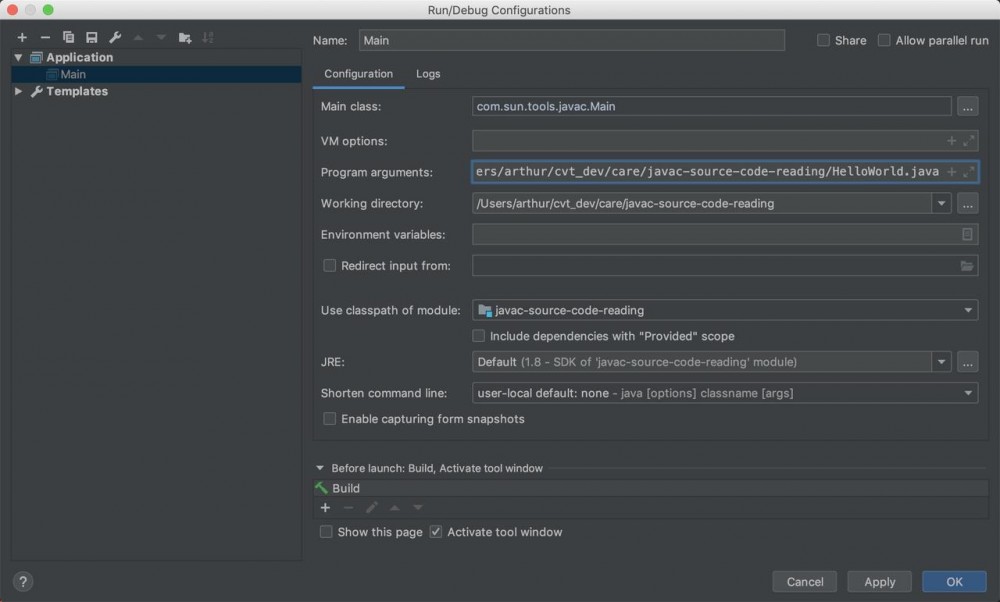
再次运行 Main.java,会在 HelloWorld.java 的同级目录生成 HelloWorld.class 文件。
3、加断点
在 Main.java 中打上断点,开始调试以后会发现不管怎么设置,调试都会进入 tool.jar ,没有走刚刚导入的源码。
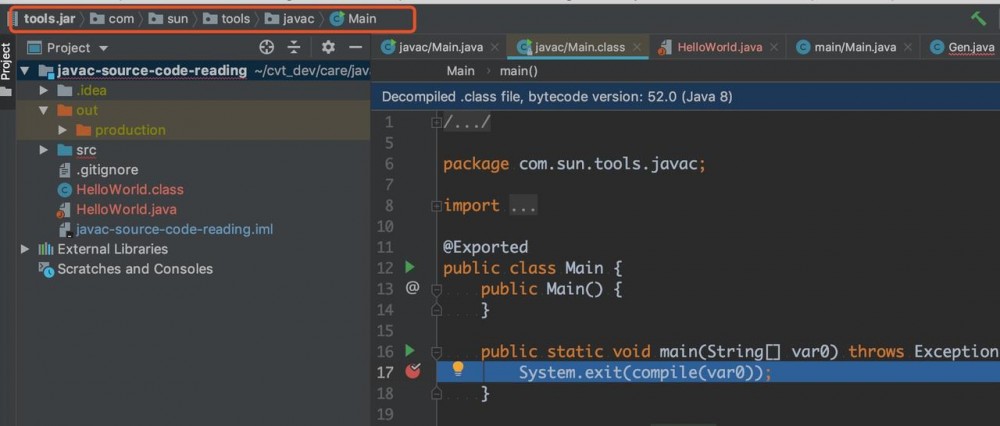
Intellij 中显示的是反编译 tools.jar 得到的源码,可读性没有源码那么好。
打开 Project Structure 页面(File->Project Structure), 选中图中 Dependencies 选项卡,把 <Moudle source> 顺序调整到项目 JDK 的上面:
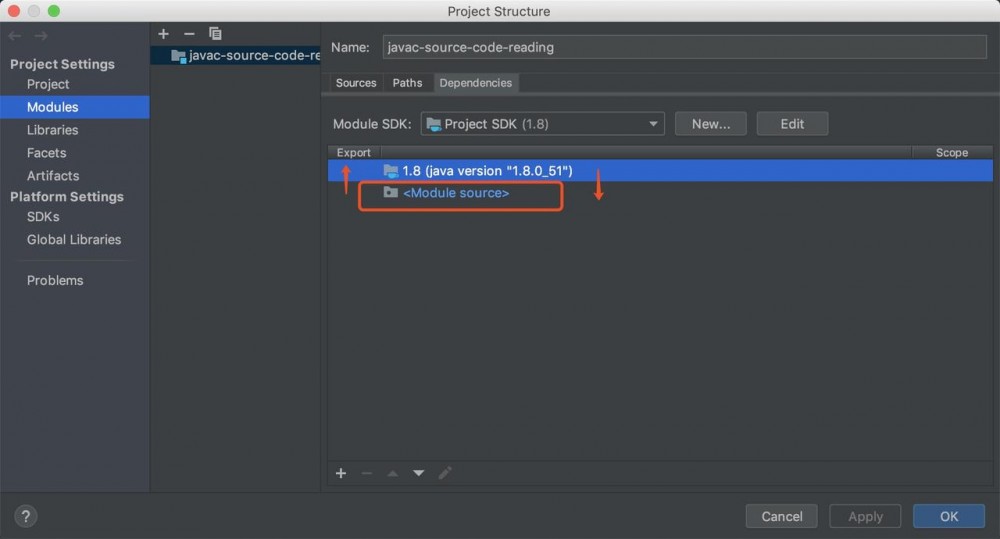
再次调试就已经可以进入到项目源码中的断点处了。
javac 看字节码案例一:tableswitch 和 lookupswitch 选择的策略
读者提问,下面的代码编译出的 switch-case 语句为什么采用了 lookupswitch,而不是 tableswitch,不是说「如果 case 的值比较紧凑,中间有少量断层或者没有断层,会采用 tableswitch 来实现 switch-case」吗?
public static void foo() {
int a = 0;
switch (a) {
case 0:
System.out.println("#0");
break;
case 1:
System.out.println("#1");
break;
default:
System.out.println("default");
break;
}
}
复制代码
对应字节码
public static void foo();
0: iconst_0
1: istore_0
2: iload_0
3: lookupswitch { // 2
0: 28
1: 39
default: 50
}
复制代码
这个问题比较有意思,主要是 tableswitch 和 lookupswitch 代价的估算,代码在 src/com/sun/tools/javac/jvm/Gen.java 中
在 case 值只有 0 和 1 两个值的情况下
hi=1 lo=0 nlabels = 2 // table_space_cost = 4 + (1 - 0 + 1) = 6 long table_space_cost = 4 + ((long) hi - lo + 1); // words // table_time_cost = 3 long table_time_cost = 3; // comparisons // lookup_space_cost = 3 + 2 * 2 = 7 long lookup_space_cost = 3 + 2 * (long) nlabels; // lookup_time_cost = 2 long lookup_time_cost = nlabels; // table_space_cost + 3 * table_time_cost = 6 + 3 * 3 = 15 // lookup_space_cost + 3 * lookup_time_cost = 7 + 3 * 2 = 13 // opcode = 15 <= 13 ? tableswitch : lookupswich int opcode = nlabels > 0 && table_space_cost + 3 * table_time_cost <= lookup_space_cost + 3 * lookup_time_cost ? tableswitch : lookupswitch; 复制代码
所以在 case 值只有 0, 1 两个的情况下,代价的计算是 table_space_cost + 3 * table_time_cost > lookup_space_cost + 3 * lookup_time_cost,lookupswich代价更小选 lookupswich
如果有 0, 1,2 三个呢?
hi=2 lo=0 nlabels = 3 // table_space_cost = 4 + (2 - 0 + 1) = 7 long table_space_cost = 4 + ((long) hi - lo + 1); // words // table_time_cost = 3 long table_time_cost = 3; // comparisons // lookup_space_cost = 3 + 2 * 3 = 9 long lookup_space_cost = 3 + 2 * (long) nlabels; // lookup_time_cost = 3 long lookup_time_cost = nlabels; // table_space_cost + 3 * table_time_cost = 7 + 3 * 3 = 16 // lookup_space_cost + 3 * lookup_time_cost = 9 + 3 * 3 = 18 // opcode = 16 <= 18 ? tableswitch : lookupswich int opcode = nlabels > 0 && table_space_cost + 3 * table_time_cost <= lookup_space_cost + 3 * lookup_time_cost ? tableswitch : lookupswitch; 复制代码
所以在 case 值只有 0, 1,2 三个的情况下,代价的计算是 table_space_cost + 3 * table_time_cost < lookup_space_cost + 3 * lookup_time_cost,tableswitch 代价更小选 tableswitch
其实在数量极少的情况下,两个的差别不大,只是 javac 这里的算法导致选择了 lookupswitch
javac 看字节码案例二:加载整数到栈上的字节码指令选择
我们知道有很多指令可以把整数加载到栈上,比如 iconst_0 、 bipush 、 sipush 、 ldc ,那它们是如何选择的呢?
public static void foo() {
int a = 0;
int b = 6;
int c = 130;
int d = 33000;
}
对应部分字节码
0: iconst_0
1: istore_0
2: bipush 6
4: istore_1
5: sipush 130
8: istore_2
9: ldc #2 // int 33000
11: istore_3
复制代码
在 com/sun/tools/javac/jvm/Items.java 的 load() 函数加上断点
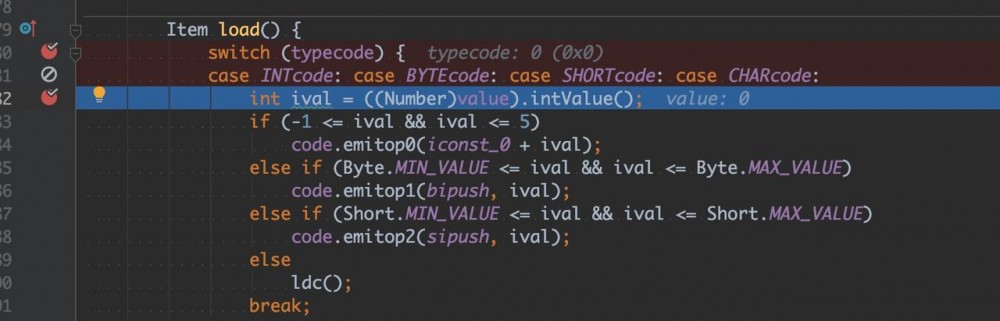
可以看到选择的策略依次往下:
- -1~5 之间选择 iconst_n 的方式
- -128~127 之间选择 bipush
- -32768~32767 之间的选择 sipush
- 其它大整数选择 ldc
这与 java 虚拟机规范中字节码指令文档一致。
后记
用 javac 发掘很多有意思的东西,希望你能留言发现更好好玩的东东。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

