Spring Cloud Alibaba Nacos(心跳与选举)
通过阅读NACOS的源码,了解其心跳与选举机制。开始阅读此篇文章之前,建议先阅读如下两篇文章:
Spring Cloud Alibaba Nacos(功能篇)
Spring Cloud Alibaba Nacos(源码篇)
一、心跳机制
只有NACOS服务与所注册的Instance之间才会有直接的心跳维持机制,换言之,这是一种典型的集中式管理机制。

在client这一侧是心跳的发起源,进入NacosNamingService,可以发现,只有注册服务实例的时候才会构造心跳包:
@Override
public void registerInstance(String serviceName, String groupName, Instance instance) throws NacosException {
if (instance.isEphemeral()) {
BeatInfo beatInfo = new BeatInfo();
beatInfo.setServiceName(NamingUtils.getGroupedName(serviceName, groupName));
beatInfo.setIp(instance.getIp());
beatInfo.setPort(instance.getPort());
beatInfo.setCluster(instance.getClusterName());
beatInfo.setWeight(instance.getWeight());
beatInfo.setMetadata(instance.getMetadata());
beatInfo.setScheduled(false);
beatReactor.addBeatInfo(NamingUtils.getGroupedName(serviceName, groupName), beatInfo);
}
serverProxy.registerService(NamingUtils.getGroupedName(serviceName, groupName), groupName, instance);
}
没有特殊情况,目前ephemeral都是true。BeatReactor维护了一个Map对象,记录了需要发送心跳的BeatInfo,构造了一个心跳包后,BeatReactor.addBeatInfo方法将BeatInfo放入Map中。然后,内部有一个定时器,每隔5秒发送一次心跳。
class BeatProcessor implements Runnable {
@Override
public void run() {
try {
for (Map.Entry<String, BeatInfo> entry : dom2Beat.entrySet()) {
BeatInfo beatInfo = entry.getValue();
if (beatInfo.isScheduled()) {
continue;
}
beatInfo.setScheduled(true);
executorService.schedule(new BeatTask(beatInfo), 0, TimeUnit.MILLISECONDS);
}
} catch (Exception e) {
NAMING_LOGGER.error("[CLIENT-BEAT] Exception while scheduling beat.", e);
} finally {
executorService.schedule(this, clientBeatInterval, TimeUnit.MILLISECONDS);
}
}
}
通过设置scheduled的值来控制是否已经下发了心跳任务,具体的心跳任务逻辑放在了BeatTask。
class BeatTask implements Runnable {
BeatInfo beatInfo;
public BeatTask(BeatInfo beatInfo) {
this.beatInfo = beatInfo;
}
@Override
public void run() {
long result = serverProxy.sendBeat(beatInfo);
beatInfo.setScheduled(false);
if (result > 0) {
clientBeatInterval = result;
}
}
}
sendBeat就是请求了/instance/beat接口,只返回了一个心跳间隔时长,将这个返回值用于client设置定时任务间隔,同时将scheduled置为false,表示完成了此次心跳发送任务,可以进行下次心跳。
NACOS接到心跳后,会有一段instance判空的逻辑,如果找不到对应的instance,就会直接创建出来,也就是默认相信心跳的请求源是合理的。
Instance instance = serviceManager.getInstance(namespaceId, serviceName, clientBeat.getCluster(), clientBeat.getIp(), clientBeat.getPort());
if (instance == null) {
instance = new Instance();
instance.setPort(clientBeat.getPort());
instance.setIp(clientBeat.getIp());
instance.setWeight(clientBeat.getWeight());
instance.setMetadata(clientBeat.getMetadata());
instance.setClusterName(clusterName);
instance.setServiceName(serviceName);
instance.setInstanceId(instance.generateInstanceId());
instance.setEphemeral(clientBeat.isEphemeral());
serviceManager.registerInstance(namespaceId, serviceName, instance);
}
Service service = serviceManager.getService(namespaceId, serviceName);
if (service == null) {
throw new NacosException(NacosException.SERVER_ERROR, "service not found: " + serviceName + "@" + namespaceId);
}
service.processClientBeat(clientBeat);
对于client的心跳处理,放在了对应的Service里面,处理心跳的代码逻辑放在了ClientBeatProcessor:
@Override
public void run() {
Service service = this.service;
String ip = rsInfo.getIp();
String clusterName = rsInfo.getCluster();
int port = rsInfo.getPort();
Cluster cluster = service.getClusterMap().get(clusterName);
List<Instance> instances = cluster.allIPs(true);
for (Instance instance : instances) {
if (instance.getIp().equals(ip) && instance.getPort() == port) {
instance.setLastBeat(System.currentTimeMillis());
if (!instance.isMarked()) {
if (!instance.isHealthy()) {
instance.setHealthy(true);
getPushService().serviceChanged(service.getNamespaceId(), this.service.getName());
}
}
}
}
}
逻辑很简单,将集群下所有ephemeral=true的实例找出来,然后根据ip和port匹配到对应的instance,然后记录此次心态时间。
marked属性暂时没有发现有什么用处,唯一调用过setMarked的地方是通过解析一段字符串来构建Instance,下划线分割,可以指定marked。
// 7 possible formats of config: // ip:port // ip:port_weight // ip:port_weight_cluster // ip:port_weight_valid // ip:port_weight_valid_cluster // ip:port_weight_valid_marked // ip:port_weight_valid_marked_cluster
按照处理心跳的逻辑,如果marked=true的话,这个实例就不会处理ServiceChanged事件,状态也就得不到改变了。
PushService在处理ServiceChanged事件的时候,主要做了两件事情:
其一,根据上次记录的心跳时间,判断现有的实例在缓存的时效内(默认10s)是否有心跳发送过来,主要的调用方法:
public boolean zombie() {
return System.currentTimeMillis() - lastRefTime > switchDomain.getPushCacheMillis(serviceName);
}
其二、是发送udp广播通知所有的client,有instance发生了变更。
if (compressData != null) {
ackEntry = prepareAckEntry(client, compressData, data, lastRefTime);
} else {
ackEntry = prepareAckEntry(client, prepareHostsData(client), lastRefTime);
if (ackEntry != null) {
cache.put(key, new org.javatuples.Pair<>(ackEntry.origin.getData(), ackEntry.data));
}
}
udpPush(ackEntry);
最后再关注一个问题:NACOS怎么处理长时间没有发送心跳的服务实例?
相关代码逻辑放在了PushService:
static {
try {
udpSocket = new DatagramSocket();
Receiver receiver = new Receiver();
Thread inThread = new Thread(receiver);
inThread.setDaemon(true);
inThread.setName("com.alibaba.nacos.naming.push.receiver");
inThread.start();
executorService.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
try {
removeClientIfZombie();
} catch (Throwable e) {
Loggers.PUSH.warn("[NACOS-PUSH] failed to remove client zombie");
}
}
}, 0, 20, TimeUnit.SECONDS);
} catch (SocketException e) {
Loggers.SRV_LOG.error("[NACOS-PUSH] failed to init push service");
}
}
可以看到,又是熟悉的定时器,移除client的判断依据仍然是zombie方法。
二、选举机制
NACOS选举机制的底层原理是 RAFT共识算法 ,NACOS没有依赖诸如zookeeper之类的第三方库,而是自实现了一套RAFT算法。
相较于大名鼎鼎的Paxos算法,RAFT算法最突出的优势就是易于理解,学习起来很轻松。
在RAFT算法领域中,有三种基本的状态(角色): follower 、 candidate 、 leader 。
处于follower状态的server不会发起任何的request,只是被动的响应leader和candidate。
处于leader状态的server会主动的发送心跳包给各个follower,并且接收client所有的request。
而candidate是一种过渡状态,只有整个cluster在进行新的选举的时候,才会出现此种状态的server。
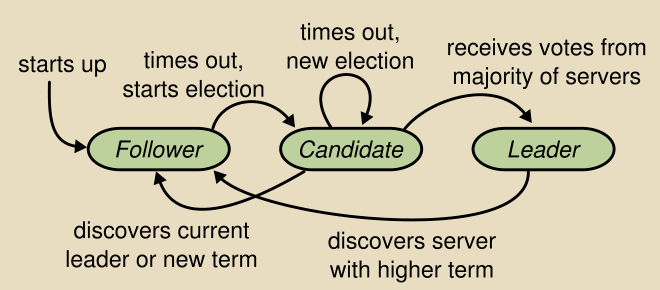
还有一个重要的概念是 term ,可以理解为一个任意(随机)的时间片段,在这个时间段内实施选举。
更多的RAFT算法知识不在此展开讲述了,接下来进入源码阅读,核心部分在RaftCore类中。此类被注解为@component,我们从init()方法开始阅读:
@PostConstruct
public void init() throws Exception {
executor.submit(notifier);
long start = System.currentTimeMillis();
datums = raftStore.loadDatums(notifier);
setTerm(NumberUtils.toLong(raftStore.loadMeta().getProperty("term"), 0L));
while (true) {
if (notifier.tasks.size() <= 0) {
break;
}
Thread.sleep(1000L);
}
initialized = true;
GlobalExecutor.registerMasterElection(new MasterElection());
GlobalExecutor.registerHeartbeat(new HeartBeat());
}
咋一看,有一个比较扎眼的while(true)死循环,当然也会有跳出循环的条件。再细看loadDatums()方法,是在读取本地缓存目录,如果不为空,就会调用notifier.addTask,这种情况下就会导致死循环跳出条件得不到满足,而notifier内部又是一个死循环,调用了tasks.take()取出任务,如果没有没有任务可取了,就会阻塞于此,上述初始化方法中的死循环也就顺利跳出了。
其实这一步操作是在利用Failover机制来同步本地的service和instance信息,与选举机制无关。
最后两行代码才是关键,分别启动了MasterElection和HeartBeat两个任务。看这部分代码的时候,需要你有分布式的思维方式,可以在脑海中假定有三个独立部署的NACOS服务组成的cluster。
先来看选举任务的定义:
public class MasterElection implements Runnable {
@Override
public void run() {
try {
if (!peers.isReady()) {
return;
}
RaftPeer local = peers.local();
local.leaderDueMs -= GlobalExecutor.TICK_PERIOD_MS;
if (local.leaderDueMs > 0) {
return;
}
// reset timeout
local.resetLeaderDue();
local.resetHeartbeatDue();
sendVote();
} catch (Exception e) {
Loggers.RAFT.warn("[RAFT] error while master election {}", e);
}
}
比较关键的是对时效性的处理。local.leaderDueMs的值一开始是随机生成的,范围是[0, 15000),单位是毫秒,此后按照500毫秒一个梯度进行递减,减少到≤0后,就会触发选举操作。当然,选举之前,把超时时间重置一下。resetLeaderDue()方法是把leaderDueMs变量重新赋值,但是并不是像初始化随机赋值一样的逻辑,而是在15000毫秒的基础上加上了一个随机值,其随机值的范围是[0, 5000)毫秒。
接下来就是选举方法:
public void sendVote() {
RaftPeer local = peers.get(NetUtils.localServer());
peers.reset();
local.term.incrementAndGet();
local.voteFor = local.ip;
local.state = RaftPeer.State.CANDIDATE;
Map<String, String> params = new HashMap<String, String>(1);
params.put("vote", JSON.toJSONString(local));
for (final String server : peers.allServersWithoutMySelf()) {
final String url = buildURL(server, API_VOTE);
try {
HttpClient.asyncHttpPost(url, null, params, new AsyncCompletionHandler<Integer>() {
@Override
public Integer onCompleted(Response response) throws Exception {
if (response.getStatusCode() != HttpURLConnection.HTTP_OK) {
return 1;
}
RaftPeer peer = JSON.parseObject(response.getResponseBody(), RaftPeer.class);
peers.decideLeader(peer);
return 0;
}
});
} catch (Exception e) {
Loggers.RAFT.warn("error while sending vote to server: {}", server);
}
}
}
进入这个方法之后,会将自身的term自增1,为自己投一票,状态变成了candidate,然后将自己投票的结果发送给其他NACOS服务。发送投票是若干次HTTP Request,由各自的RaftController来接收处理,最终调用的还是RaftCore.receivedVote方法:
public RaftPeer receivedVote(RaftPeer remote) {
if (!peers.contains(remote)) {
throw new IllegalStateException("can not find peer: " + remote.ip);
}
RaftPeer local = peers.get(NetUtils.localServer());
if (remote.term.get() <= local.term.get()) {
if (StringUtils.isEmpty(local.voteFor)) {
local.voteFor = local.ip;
}
return local;
}
local.resetLeaderDue();
local.state = RaftPeer.State.FOLLOWER;
local.voteFor = remote.ip;
local.term.set(remote.term.get());
return local;
}
这里面主要是对term的数值大小比较,如果一旦发现request请求过来的term比自己本地的term要大,那就放弃竞选,自己转为follower的状态,将term设置为request中带过来的term参数值;反之,就不做任何处理,直接返回local。
发送投票后,可以同时拿到对方的投票结果,然后根据各方投票结果来计算最终哪台server出于leader状态。
public RaftPeer decideLeader(RaftPeer candidate) {
peers.put(candidate.ip, candidate);
SortedBag ips = new TreeBag();
int maxApproveCount = 0;
String maxApprovePeer = null;
for (RaftPeer peer : peers.values()) {
if (StringUtils.isEmpty(peer.voteFor)) {
continue;
}
ips.add(peer.voteFor);
if (ips.getCount(peer.voteFor) > maxApproveCount) {
maxApproveCount = ips.getCount(peer.voteFor);
maxApprovePeer = peer.voteFor;
}
}
if (maxApproveCount >= majorityCount()) {
RaftPeer peer = peers.get(maxApprovePeer);
peer.state = RaftPeer.State.LEADER;
if (!Objects.equals(leader, peer)) {
leader = peer;
}
}
return leader;
}
因为发起投票的请求是异步进行的,进入decideLeader方法中并不意味着所有的candidate都完成了投票,所以会在for循环中忽略未投票的peer。接下来要经过两个步骤,其一是计算出得票数最多的peer,其二是最多的得票数还必须超过整个集群实例数的一半。这也就说明了服务实例为什么要是奇数个,并且是三个及以上。RAFT算法推荐的是5个实例。
然后就是由leader发送心跳包给各个follower。对于心跳时效性的处理逻辑和选举的时候如出一辙,这里就不再赘述了。run方法里面没有调用resetLeaderDue()方法,而是推迟到了sendBeat()方法里面进行调用了,达到的效果是一样的,防止在不必要的时候发起了选举。
public class HeartBeat implements Runnable {
@Override
public void run() {
try {
if (!peers.isReady()) {
return;
}
RaftPeer local = peers.local();
local.heartbeatDueMs -= GlobalExecutor.TICK_PERIOD_MS;
if (local.heartbeatDueMs > 0) {
return;
}
local.resetHeartbeatDue();
sendBeat();
} catch (Exception e) {
Loggers.RAFT.warn("[RAFT] error while sending beat {}", e);
}
}
当然,follower在接收到心跳包之后,也会调用resetLeaderDue()方法,也就意味着,如果follower长时间收不到leader的心态,就认为leader已经不可用了,随机触发选举操作,选出新的leader。
最后来讨论两种可能发生的情况,可能性微乎其微的奇葩场景就不再讨论了。
1、在一轮投票中,大家很凑巧的都投给了自己,那就等待下一轮投票开始吧!不可能每次都这么凑巧。同时,NACOS选举加入了时间的随机性,如果发现不满足时间点的要求,就会放弃选举,维持上一轮的term,最终肯定是处于follower的状态。
2、leader选举成功后,因为网络抖动,follower接收不到心跳包,将会重新发起选举。重新选举的过程中,如果旧的leader恢复了,那就皆大欢喜,一切照常;如果没有及时恢复过来,那就造成了双leader的问题。不过NACOS在处理心跳包的时候会修正,当发现自己不是follower状态,却收到了心跳包的时候,会强制把自己的状态变为follower。如果凑巧两个leader都将自己变为了follower,也没关系,心跳过期时间一到,马上就可以开始新的选举流程了。
三、总结
本文深入探讨了NACOS的心跳和选举机制,并且对可能遇到的情况进行了进一步分析。总的来说,心跳机制是比较好理解的,而选举机制则需要一些RAFT算法的基础知识,加之目前NACOS源码的注解甚少,如果对NACOS没有一定的了解,阅读起来还是有些困难的。总之,把握整体,不要在意太多细节。
扫描下方二维码,进入原创干货,搞“技”圣地。

正文到此结束
- 本文标签: IDE 解析 二维码 client 发送任务 id Reactor 源码 js UI App list build 文章 Master 缓存 java https map CTO value ftp ACE IO Proxy spring struct zookeeper UDP key Connection http executor equals 目录 ip 集群 时间 json 同步 ask cache HashMap cat 代码 实例 总结 core ORM Spring cloud heartbeat find API DOM final src Service maxap 部署 db 管理 parse 参数 lib Property 分布式 tag remote tar
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

