你还在为了JVM而烦恼么?(内存结构和垃圾回收算法)

做JAVA也有接近2年的时间了,公司的leader说,做JAVA,三年是个坎,如果过了三年你还没有去研究JVM的话,那么你这个程序员只能是板砖的工具了。恰逢辞职,来个JVM的解析可好?
JVM是Java Virtual Machine(Java虚拟机)的缩写,也就是指的JVM虚拟机,属于是一种虚构出来的计算机,在我们实际的电脑上来进行模拟各种计算机的功能的这么个东西。
因为有了JVM的存在,搞JAVA的不再需要去关心什么时候去释放内存,也不会像C++程序员那样为了一点点内存而惆怅,对就是你,JVM虚拟机帮你把这些东西都完成了,那么我们来说说JAVA的JVM吧!
我们先来看看JVM的模型吧,之前在百度上看文档,上面就说了几个,方法区,堆,栈,计数器。没了,很难受,于是看了深入理解JVM的书,也算是有点体会。
在深入理解JVM一书中提到,JVM运行时的数据区域会划分为几个不同的区域,有方法区(Method Area),虚拟机栈(VM Stack),本地方法栈(Native Method Stack),堆(heap),程序计数器(Program Counter Register),下面就是书中的图:
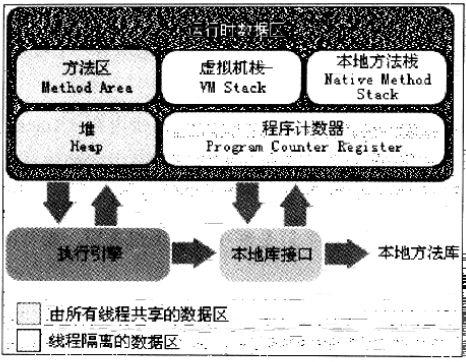
咱们一个一个来解释,
先说 程序计数器 (Program Counter Register):程序计数器实际上就是用于存放下一条指令所在地址的地方,当我们执行一条指令的时候,要先知道他存放的指令位置,然后把指令带到寄存器上这是就是获取指令,然后程序计数器中的存贮地址会加1,然后这样子循环的去执行,
而且程序计数器这个小的内存区是“线程私有的内存”。为什么会是私有的呢?,在深入理解JVM一书中说的是虚拟机的多线程通过线程的轮流切换来切换分配处理器的执行时间的方式来实现,说起来其实很拗口的,其实也就是说一个处理器,同一个时刻,只会执行一个线程的指令,但是时间可能不均衡,可能第一分钟在a线程,第二分钟就去执行b线程了,但是呢,为了保证切换回来还需要是一致的,那么每个线程中就会有一个独立存在的程序计数器,独立来存贮,为了保证不影响。所以他是一个“线程私有的内存”。
程序计数器还有几个特点:
1.如果线程正在执行的是Java 方法,则这个计数器记录的是正在执行的虚拟机字节码指令地址。
2.如果正在执行的是Native 方法,则这个计数器值为空(Undefined)
3.此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域、
分别解释一下这三句话吧,这是深入理解java虚拟机中的原话,第一句好像已经很直白了,没的说,来说说第二句话吧
因为这个计数器记录的是字节码指令地址,但是Native(本地方法);就比如说(System.currentTimeMillis())他是通过C来实现,直接通过系统就能直接调用了不需要去编译成需要执行的字节码指令的话,那么就相当于不过程序计数器,它没有记录的话,那他的计数器的值就肯定为空了。
第三句话 我们可以试试编译一小段代码,然后反编译出来看看
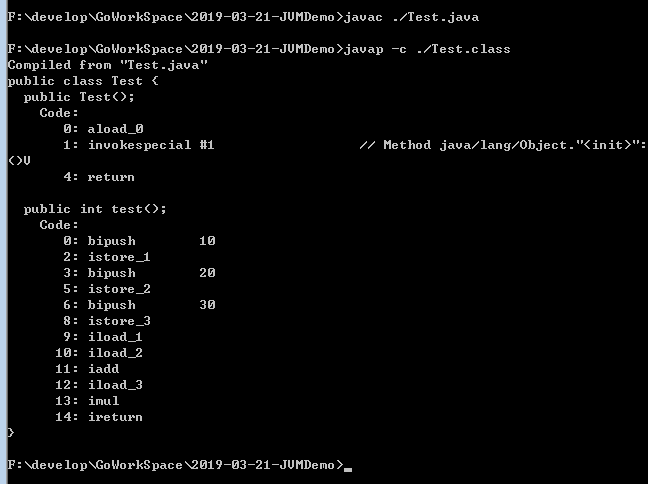
也就是实际上是这个样子的
public class Test{ public int test(){ int a = 10; //0 ...... int b = 20; //3....... int c = 30; //6...... return (a+b)*c; //11.... 13.... 14...执行加减乘除操作 } }
上面的0,2,3,5,6,8....就是指令的偏移地址bipush就是入栈指令, 在执行到test方法的时候,线程就会创建对应的程序计数器在计数器中放0,2,3,5,6,8....这些指令地址,所以计数器里改变的不是内存的大小,它也就没有溢出了。
下面我们再来说一下: JAVA虚拟机栈 (VM Stack)
线程私有,生命周期和线程一样,这个虚拟机栈描述的是JAVA方法执行的内存模型,用于存局部变量,操作数栈,方法出口等信息的,上面那个bipush就是入栈指令,在这里最需要注意的就是他存放的是什么数据.局部变量里面放的就是那些我们所知道的基本的数据类型,对象引用的话那就是一个地址。
在虚拟机规范里面还说,他的2个异常状况,
1.一个是StackOverflowError异常,栈内存溢出,这肯定很容易理解,就是栈的内存不够,你的请求线程太大。(固定长度的栈)
2.如果说在动态扩展的过程中,申请的长度还是不够,那么会抛出另外一个异常OutOfMemoryError异常。
3.本地方法栈(Native Method Stack)
它和虚拟机栈很类似,区别就在于虚拟机栈执行的是JAVA方法,但是本地方法栈则是Native方法,其他的没啥不同就连抛出异常都一样的,
4. JAVA堆 (heap)
在JVM一书中也有提到,Heap是在JAVA虚拟机中内存占用最大的一个地方,也是所有线程共享的一个内存区域,堆内存中主要就是用于存放对象实例的。
几乎是所有的对象实例都在这里分配内存,JAVA堆是垃圾收集器管理的主要区域,那么现在重点来了,面试中问到最多的垃圾回收机制接下来就要仔细说说了。
内存回收,现在都是进行的分代算法,堆中也是,新生代,老年代,而且两种垃圾回收机制是采用的不同的回收机制的,在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用"标记-清理"或"标记-压缩"算法来进行回收,说回收机制先看看heap的分区(这个from和to 并不是绝对的,看对象处在哪个位置,GC的次数不一样之后,那from和to会有相应转变)

分区一目了然,下面研究一下算法实现吧
Minor GC:GC新生代,
Full GC:老年代GC,
因为新生代中对象的存活率比较低,所以一般采用复制算法,老年代的存活率一般比较高,一般使用”标记-清理”或者”标记-整理”算法进行回收。
看了有几天才明白啥意思,我说说我自己的见解吧,还是画图吧,
Minor GC:
我们每次new对象的时候都会先在新生代的Enden区放着也就是最开始 是这样子的

然后在Enden用完的时候里面会出现待回收的
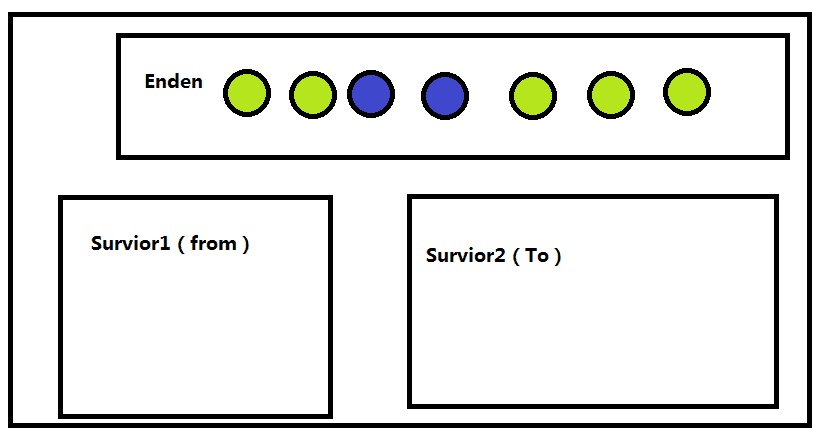
然后就来了把存活的对象复制放到Survior1(from)中,待回收的等待给他回收掉 就是这样的
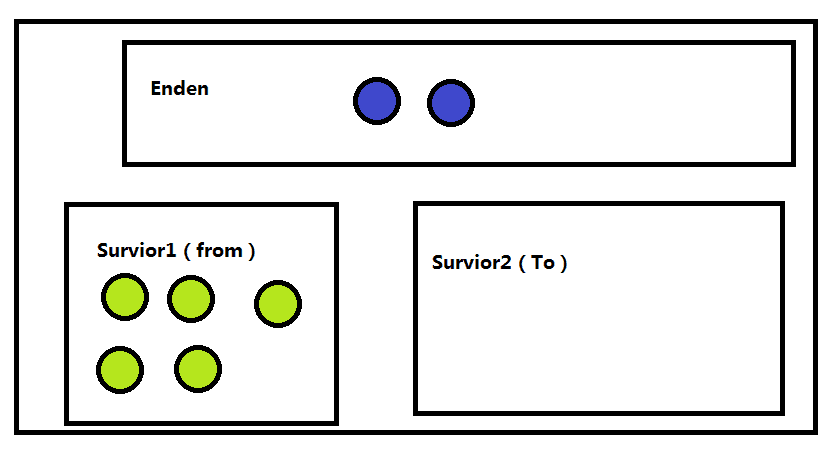
然后把Enden区清空回收掉
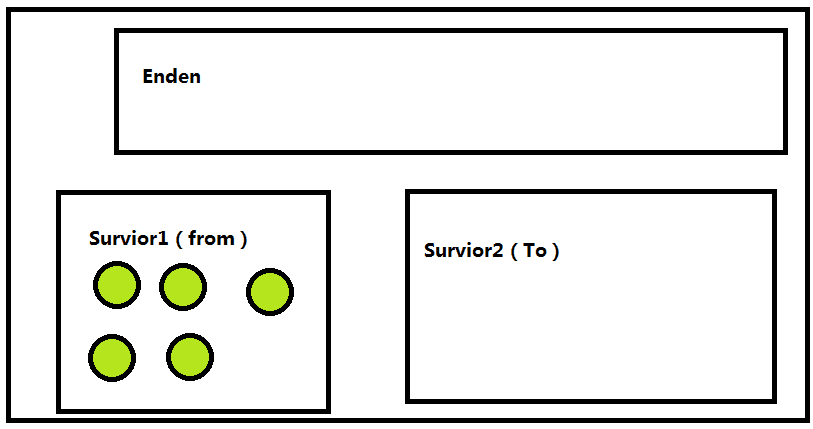
这样的话 第一次GC就完成了,下面再往下走
当Enden充满的时候就会再次GC
先是这个样子的
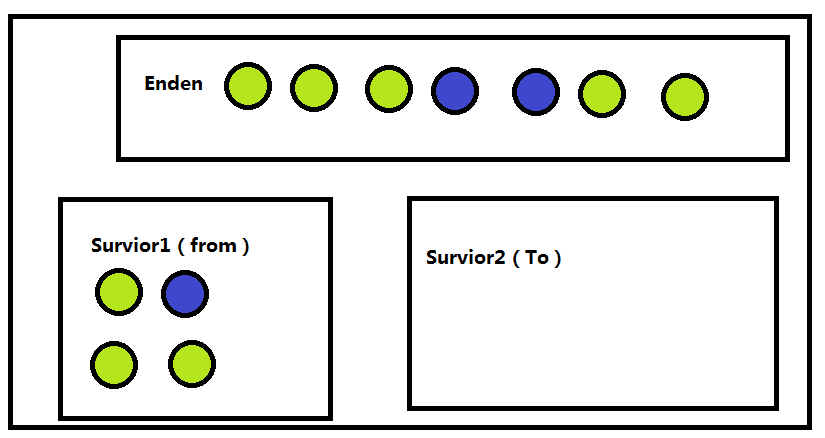
然后会把 Enden和Survoir1中的内容复制到Survior中,
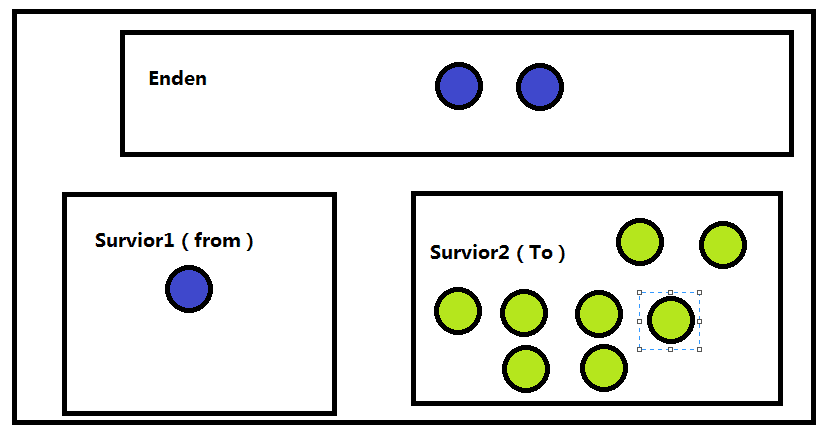
然后就会把Enden和Survior进行回收
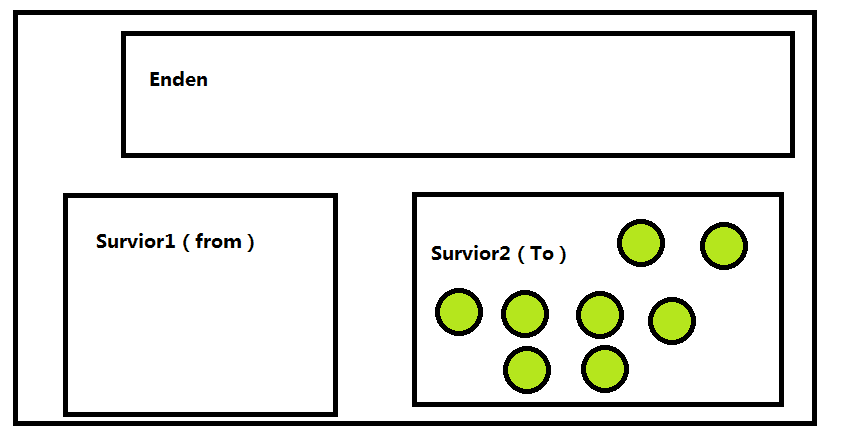
然后从Enden中过去的就相当于次数少的,而从Survior1中过去的就相当于移动了2次
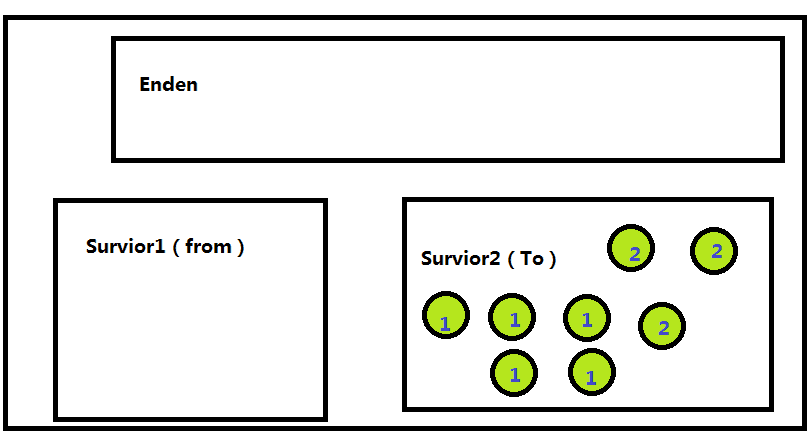
这样新生代的GC就执行了2次了,当Enden再次被使用完成的时候,就会从Survior2复制到Survior1中,接下来是连图
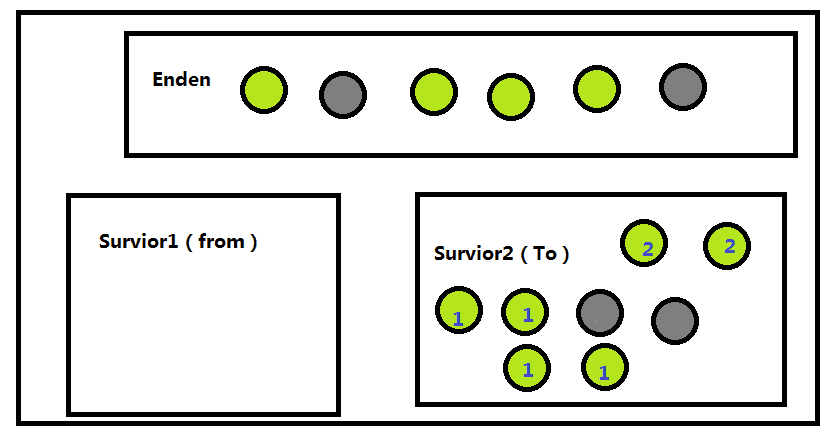
经过回收之后Surior1就变了,1对象是从Enden直接复制过来的,2对象是Enden-->Survior2-->Survior1 ,3对象则是从Enden-->Surivior1-->Survior2-->Survior1 复制过来的,这样一步一步的执行下去的时候,就是新生代的GC。
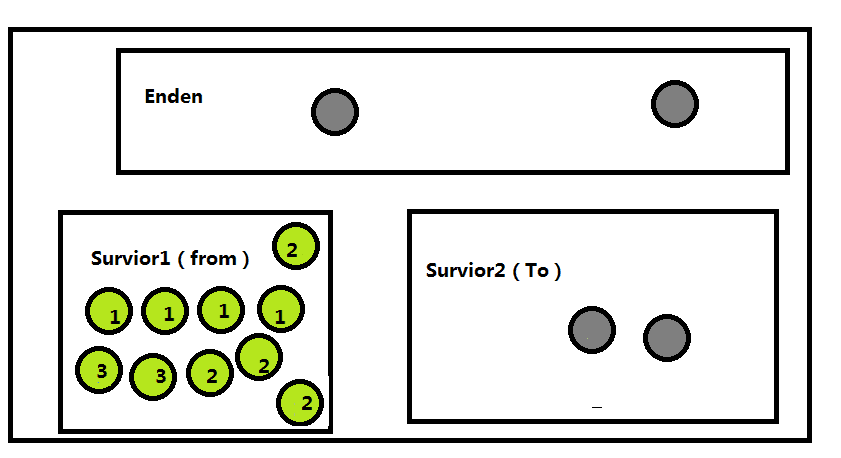
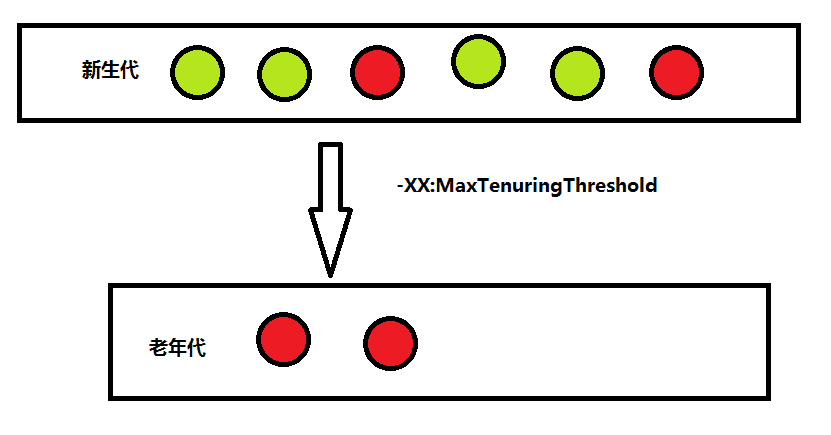
既然这样,那为什么还会存在老年代呢?其实如果GC在执行的时候有些对象一直没有被回收,那么他移动次数就会无限的累计,每次从Surior(from)到Surior(to)的过程中就相当于又增加了一次移动,当他达到一定的次数的时候(默认是15),就会移动到老年代里了,所以不存在不会被回收的对象,但是这个次数可以设置的,
-XX:MaxTenuringThreshold
就类似这样子
其实上边的这只是一种情况,还有就是如果对象太大,存不下,那就直接会进入老年代。
还有那种默认就是长期活着的也会进入老年代,
而且这种复制算法的垃圾回收机制是比较浪费内存的,每次都会有一块内存区是闲着不干活的,但是优点很明显,简单高效
以上就是GC中垃圾回收中的新生代复制算法解析,新生代的Minor GC也算是知道了不少东西了,以上就是一些个人的见解,图比较清晰,容易理解,有不对的地方希望能够各位同行指点一下。
Java 极客技术公众号,是由一群热爱 Java 开发的技术人组建成立,专注分享原创、高质量的 Java 文章。如果您觉得我们的文章还不错,请帮忙赞赏、在看、转发支持,鼓励我们分享出更好的文章。
关注公众号,大家可以在公众号后台回复“掘金”,获得作者 Java 知识体系/面试必看资料。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

