图解JVM垃圾回收
第一阶段:标记出可回收对象 第二阶段:回收被标记的对象 缺点:产生大量的内存碎片
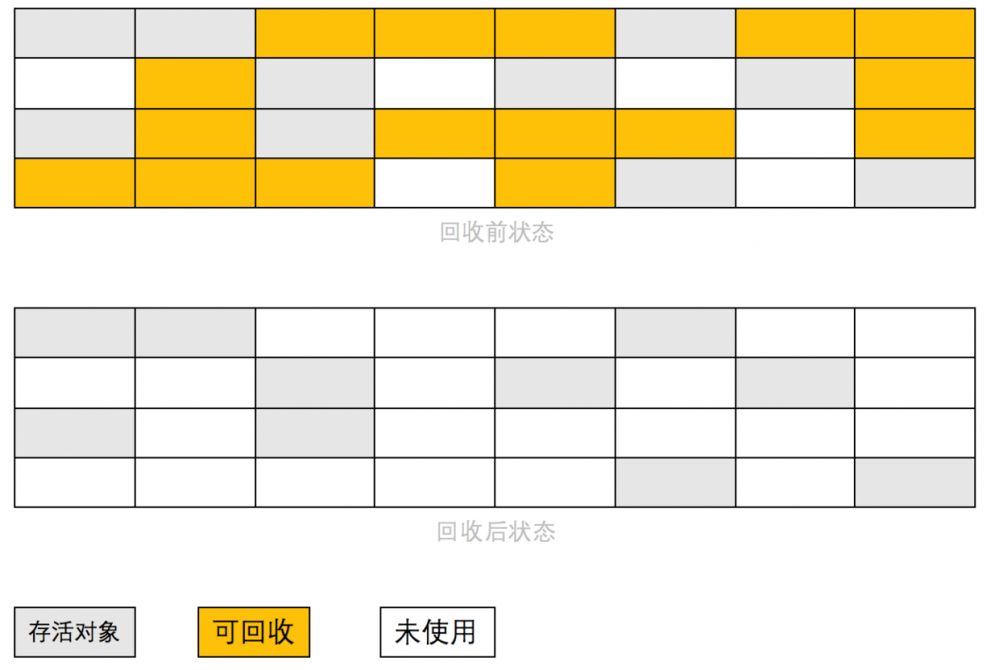
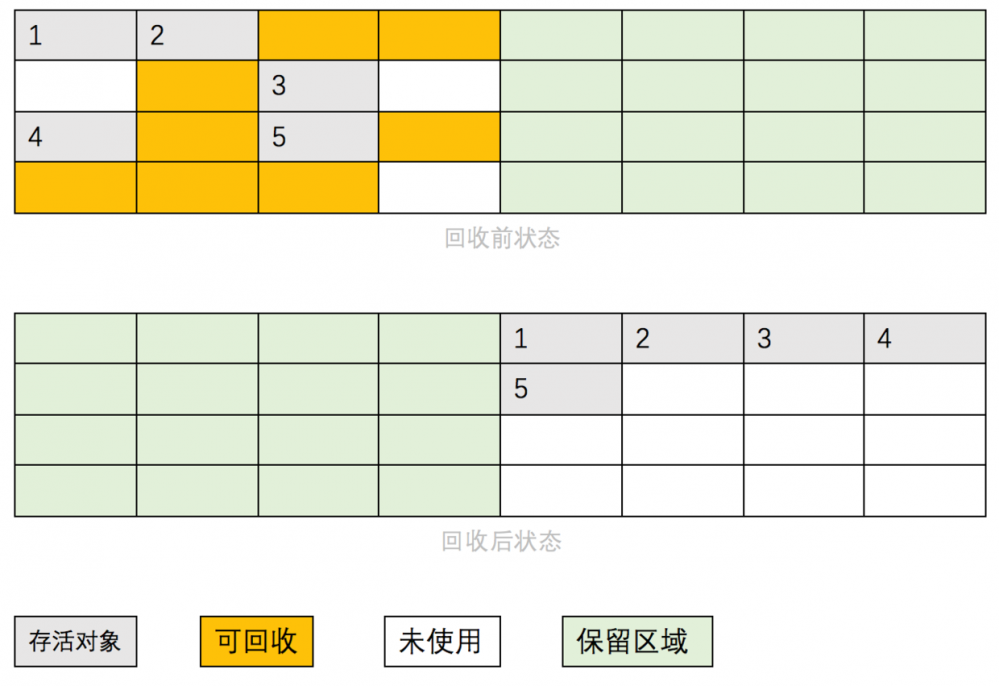
2.2、复制回收过程
内存被分为相等的两块(S0+S1),S0为使用内存,S1为保留内存,回收时将S0的存活对象一次性全部复制到S1,再一次性清空S0内存 缺点:内存使用率只有50%
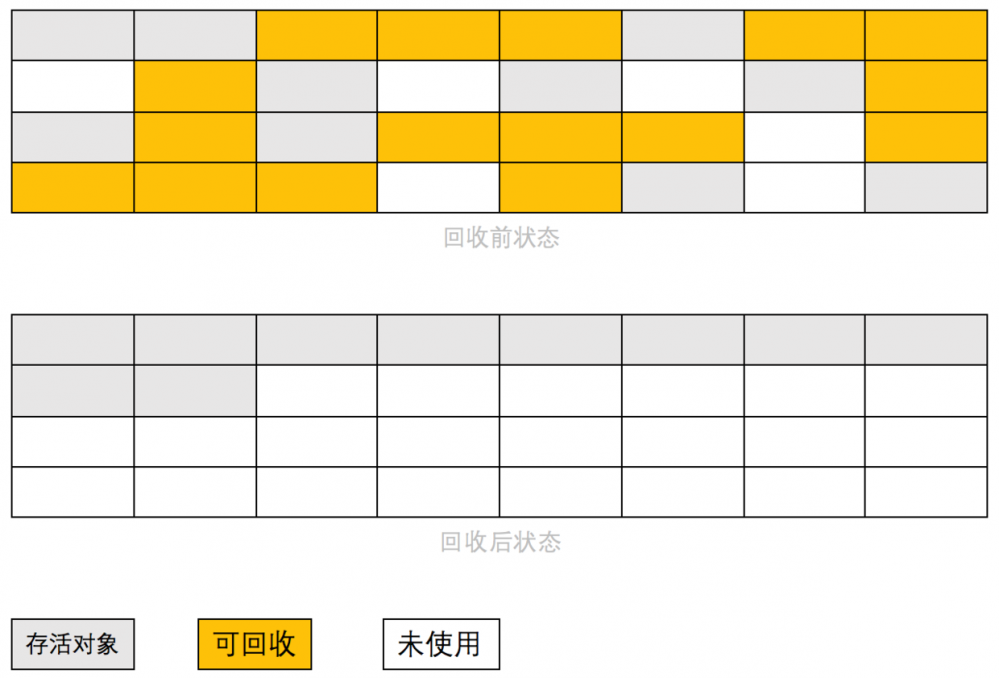
2.3、标记整理过程
第一阶段:标记出存活对象 第二阶段:存活对象往一端移动,清理边界外内存
3、各收集器采用的收集算法
业界商用的JVM收集算法都是采用分代收集,按不同代的特点采用不同的收集算法。 通常情况,年轻代采用复制算法,年老代采用标记-整理或标记-清除算法。
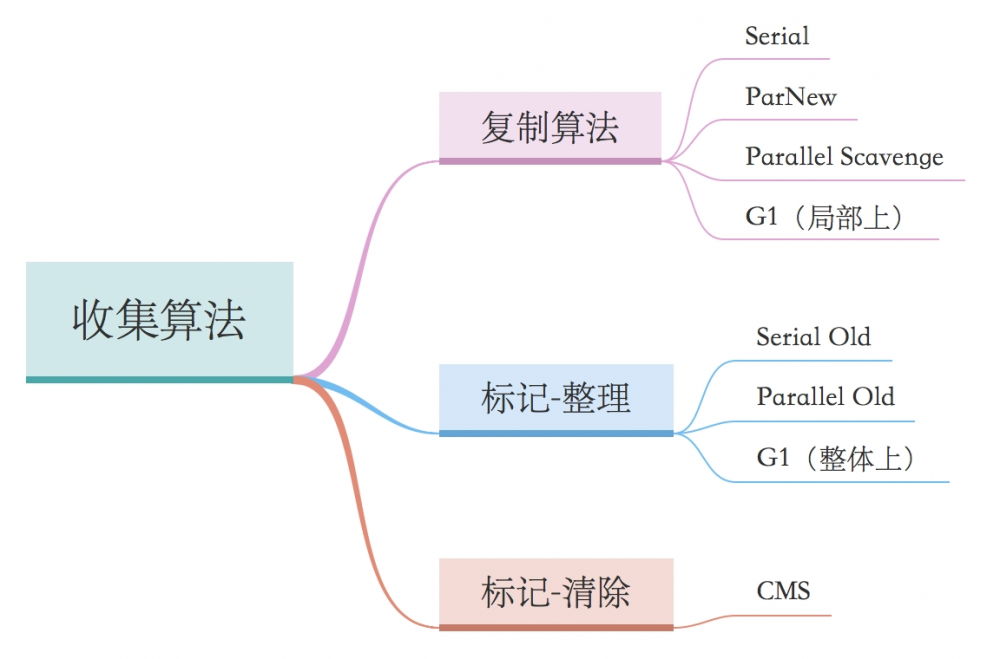
G1整体上看基于 "标记-整理" 算法,而两个Region之间则基于 "复制" 算法
二、各垃圾收集器详解
1、Serial 和Serial Old组合收集
单线程串行收集器,垃圾收集时会“Stop The World”
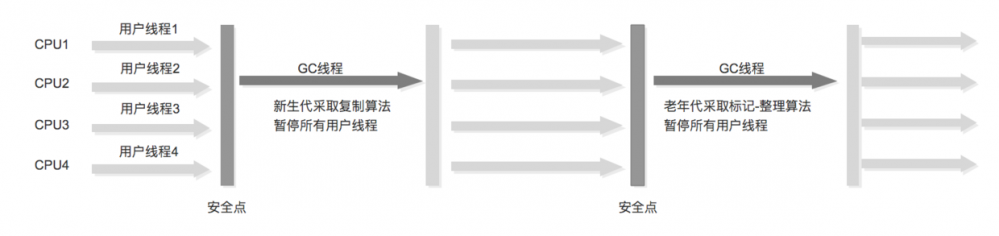
2、ParNew 和Serial Old组合收集
ParNew收集器就是Serial收集器的多线程版本,收集算法和回收策略和Serial完全一样,也会Stop The World。 注意:ParNew是并行收集器,不是并发收集器
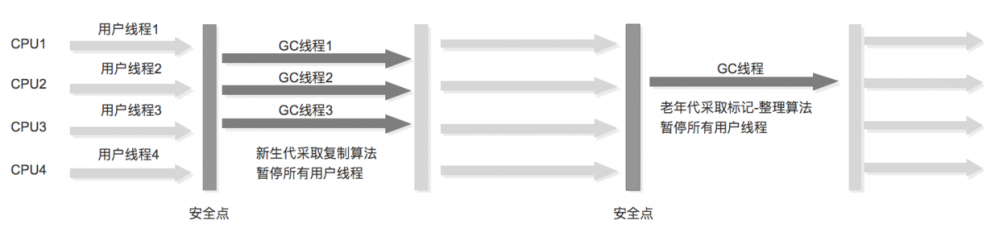
3、Parallel Scavenge收集器
跟ParNew类似,是一种 吞吐量优先 收集器,即目标是达到一个可控制的吞吐量
吞吐量 = 运行用户代码时间 / (运行用户代码时间) + 垃圾收集时间 复制代码
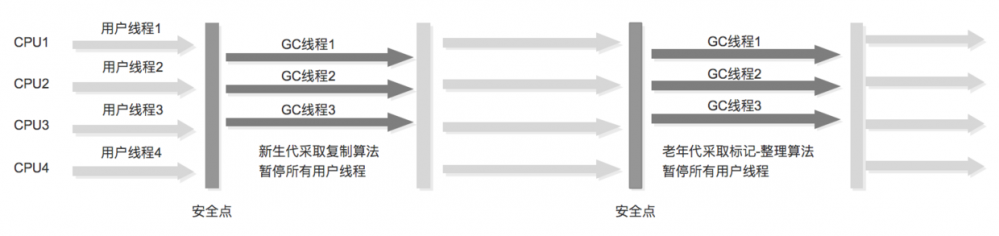
4、Parallel Scavenge和Parallel Old组合收集
Parallel Old是Parallel Scavenge收集器的老年代版本
5、CMS收集器
CMS收集器是一种并发收集器,目标时已达到最小回收停顿时间,采用标记清除算法。
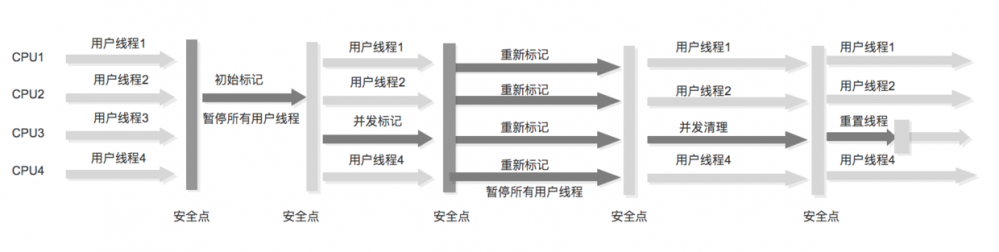
6、G1收集器
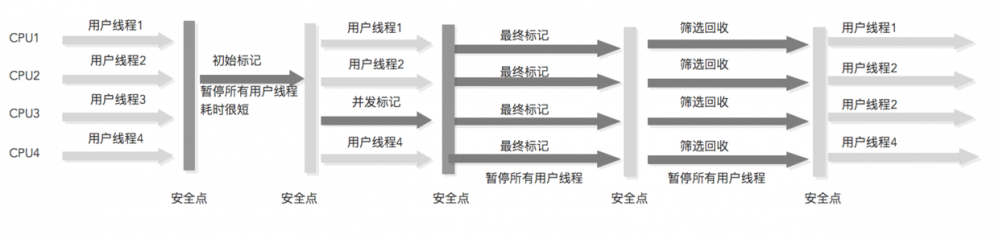
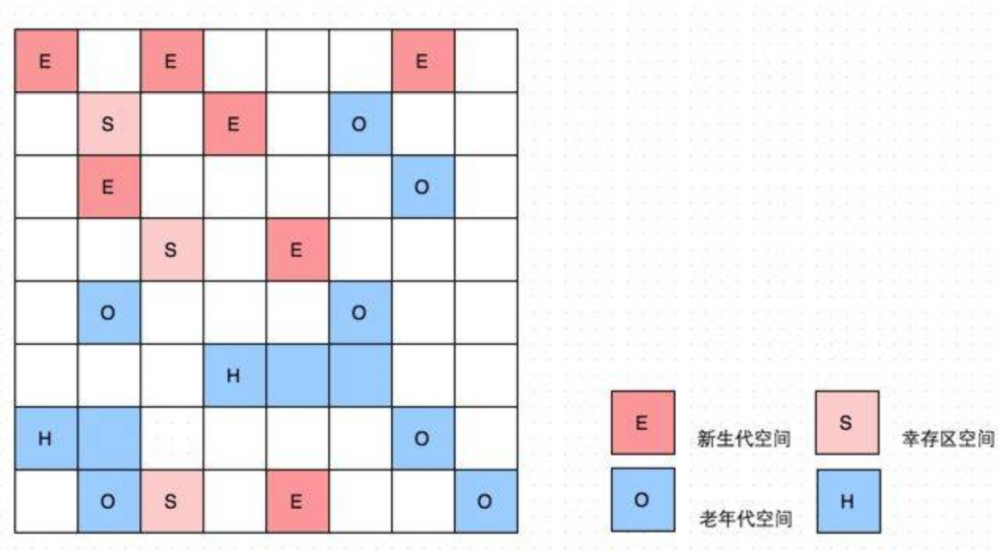
G1内存布局中,保留了年轻代年老代的概念,但不是物理隔离,而是很多个大小相同的独立区域(Region),年轻代和年老代都是一部分Region(不需要连续)的集合 初始标记:标记GC Roots能直接关联到的对象 并发标记:从GC Roots中对堆对象进行可达性分析,找出存活对象 最终标记:修改并发期间变动的标记记录 筛选回收:根据用户指定的停顿时间制定回收计划
三、存活对象的判断
不管是采用什么样的垃圾回收算法,都需要判断对象的存活状态,通常会采用两种方式判断
1、引用计数法
对象中增加一个引用计数器,每当有地方引用该对象时,其计数器+1,引用失效后计数器-1,当计数器为0的对象,即认为是可回收的对象,但是这种方式无法解决循环引用的问题,所以目前主流的垃圾回收器都没有采用这种方式。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

