『互联网架构』调⽤链系统架构设计(109)
上两次对比现在国内和国外的调用链系统,通过可视化的方式了解调用链的流程,来我们一起解读下目前找到这个项目是如何设计的,中间的设计思路。
源码:https://github.com/limingios/netFuture/tree/master/源码/『互联网架构』调⽤链系统架构设计(109)/
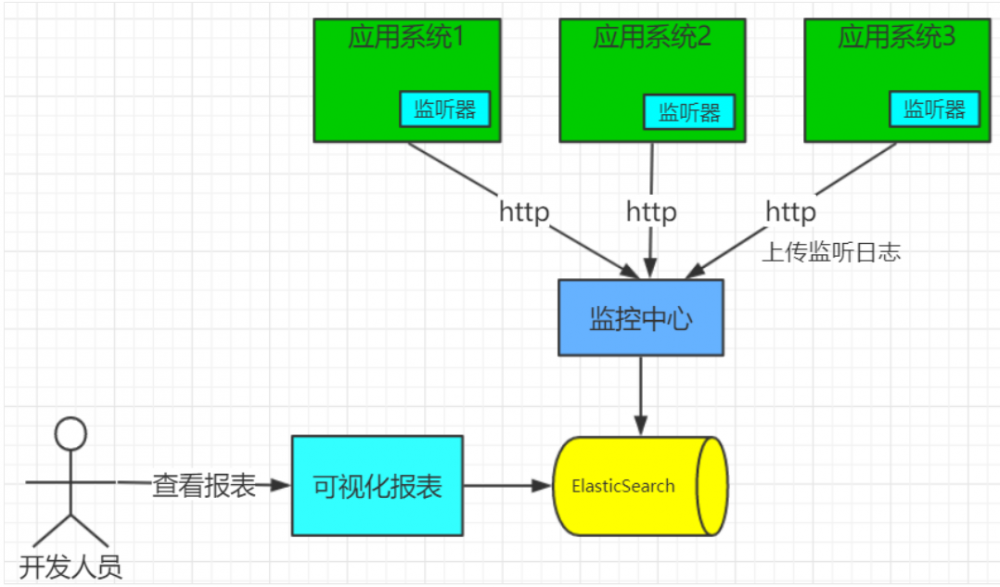
整体架构
- (一)基本功能实现架构
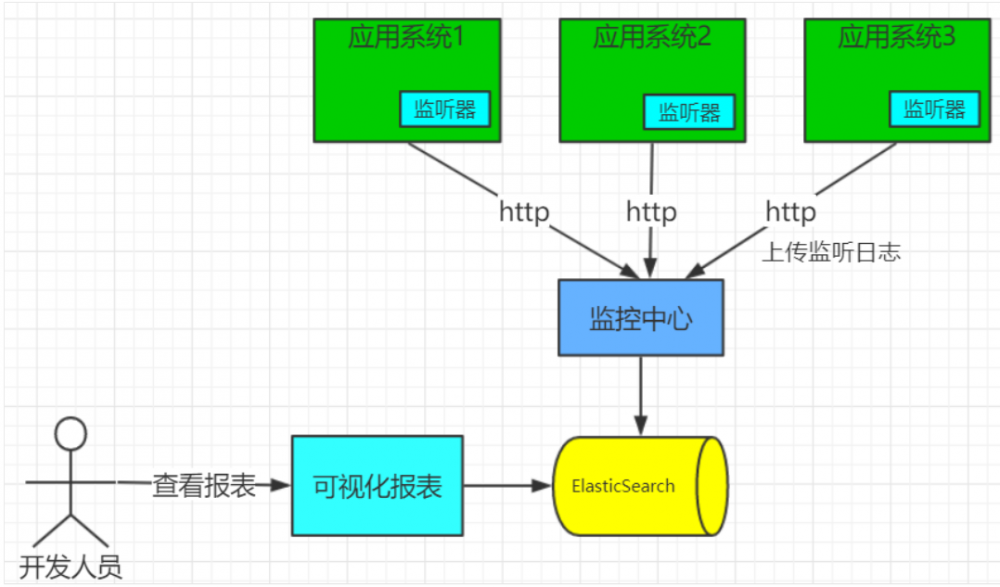
- 应用系统1,应用系统2,应用系统3,其实就是我们需要监控的系统。在这些项目启动的时候加入agent.jar参数,就是为了引入我们agent.jar。
- 引入后需要重启应用,然后通过http登录到监控中心,下载对应的jar包下载到应用系统1,应用系统2,应用系统3的监听器中。
- 监听器开始收集应用系统的监听数据通过http-json的方式发送给监控中心,监控中心把这些数据上传到ElasticSearch中。
- 开发人员打开可视化报表,调用ElasticSearch中的内容完成数据的展示。
- 监听器就是部署到我们系统中的一个间谍,只是他的部署方式比较特殊,通过tomcat启动的中加入jvm的jar包的方式,上次说过。
- 如果是线上系统通过http的方式会不会挂掉?监控中心能受的的了不?
- 在生产环境都是通过打印日志,然后把日志收集起来通过Flume或者Logstash,或者kafka。收集上传到ElasticSearch中。
- 监听器基于埋点采集,接⼝、SQL、Servlet等响应信息。
-
(二)可扩展性
> 插件机制、灵活⾃定义扩展
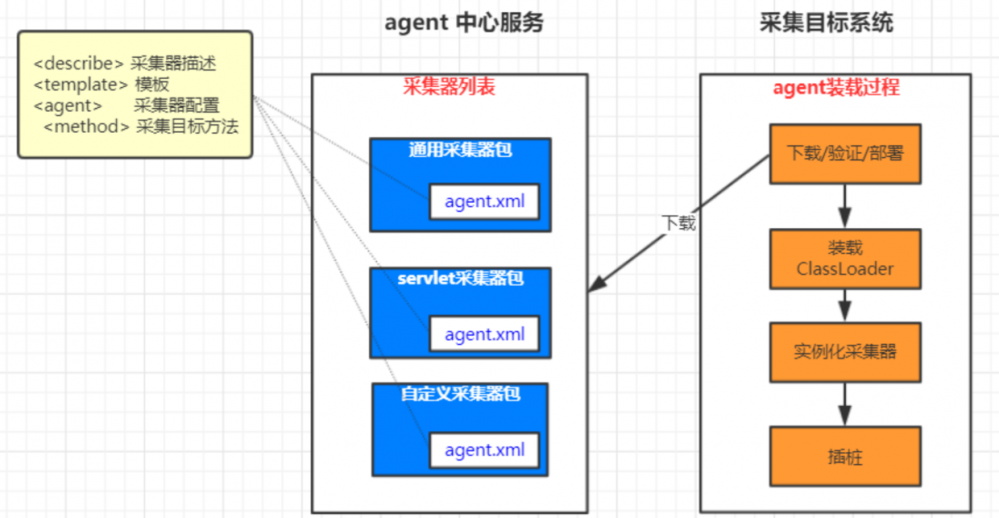
- 我们的系统肯定要有一个中心服务器。没有中心服务器系统肯定是跑不起来的。
- 采集目标系统,其实就是我们需要监控的系统,公司的某个系统。
- 首先采集目标系统先去中心服务器中下载一个一个采集包,下载到本地,然后本地通过Plugin的机制直接使用采集包。
- 这些插件采集包由谁来指定下载那个,是由服务器决定的。里面有个特殊配置agent.xml,里面由采集器描述,模板,采集器配置,采集目标方法。
- 下载的时候先解析里面的agent.xml进行,才会认为他是真正的采集器包。
- 目标系统就是在启动的时候会一个一个将各种采集包下载到服务器本地的。只不过下载的过程没那么简单。
- 下载的包中一定是包括agent.xml文件的,就描述了我们采集器的配置。类似maven的仓库。
- 这么做的好处就是我们这些包需要更新修改的时候,随时都可以发布一个新的版本。不会干扰采集目标系统。
- 明白插件是由服务器配置的,不是由目标系统来配置的就可以了。目标系统对这些东西不需要感知。如果要服务别人尽量不要知道服务的存在,这才是更好的服务。
(三)可配置性
灵活的配置⽅式,就是为了做集中化的配置
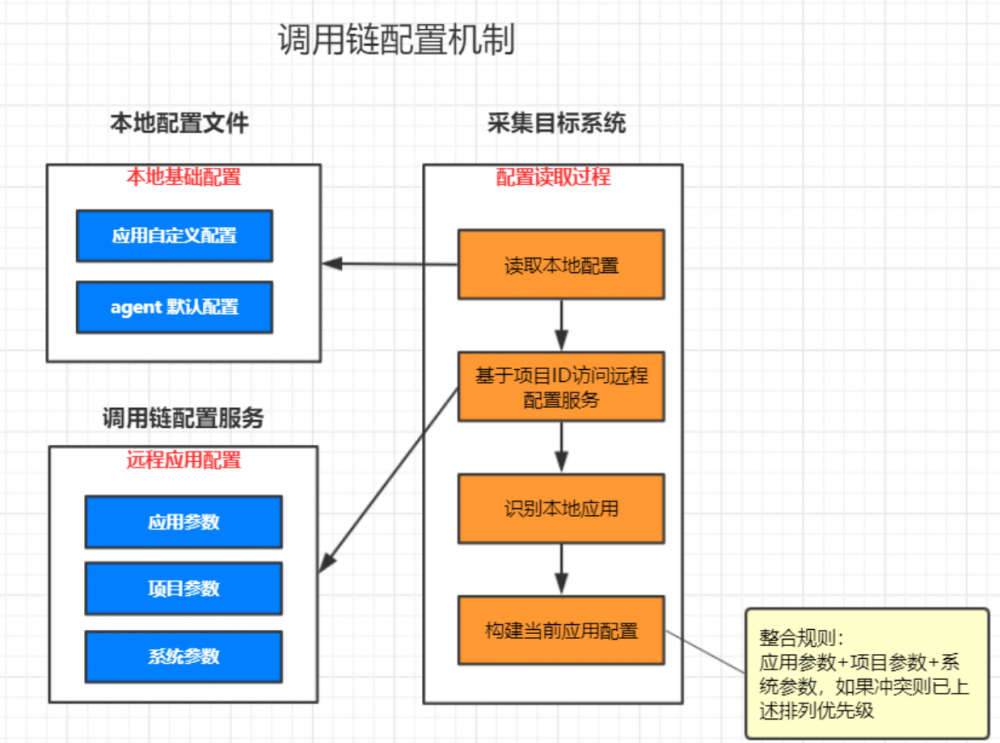
源码中,有sql的脚本,project_app主要是描述联调所在的项目名称。
里面有个命名空间的概念,必须指定该应用下的一个包路径作为值,目的是区分同项目下其它应用。指定唯一的包名来区别项目。
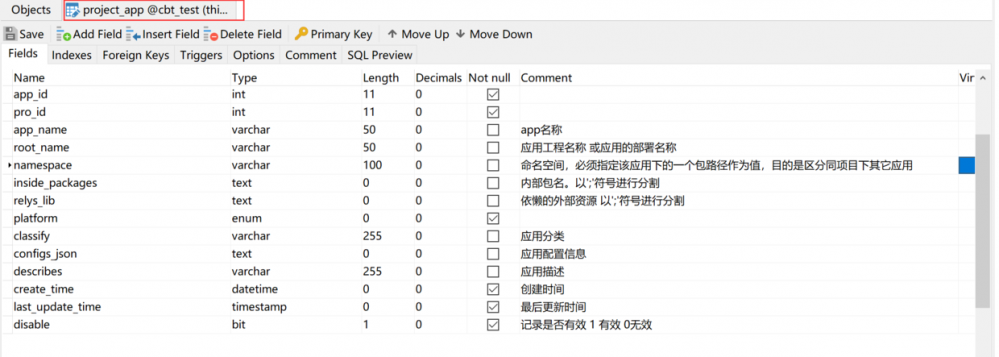
表 project_app

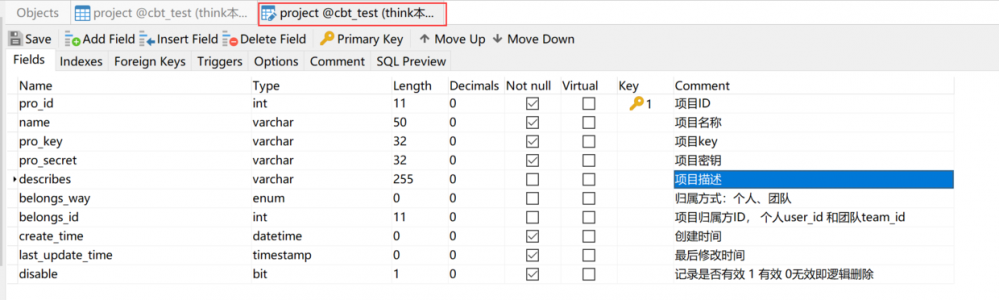
project 表,主要是为了接入的时候使用的。跟agent的conf中保持一致

(四)可运维
⾃动更新
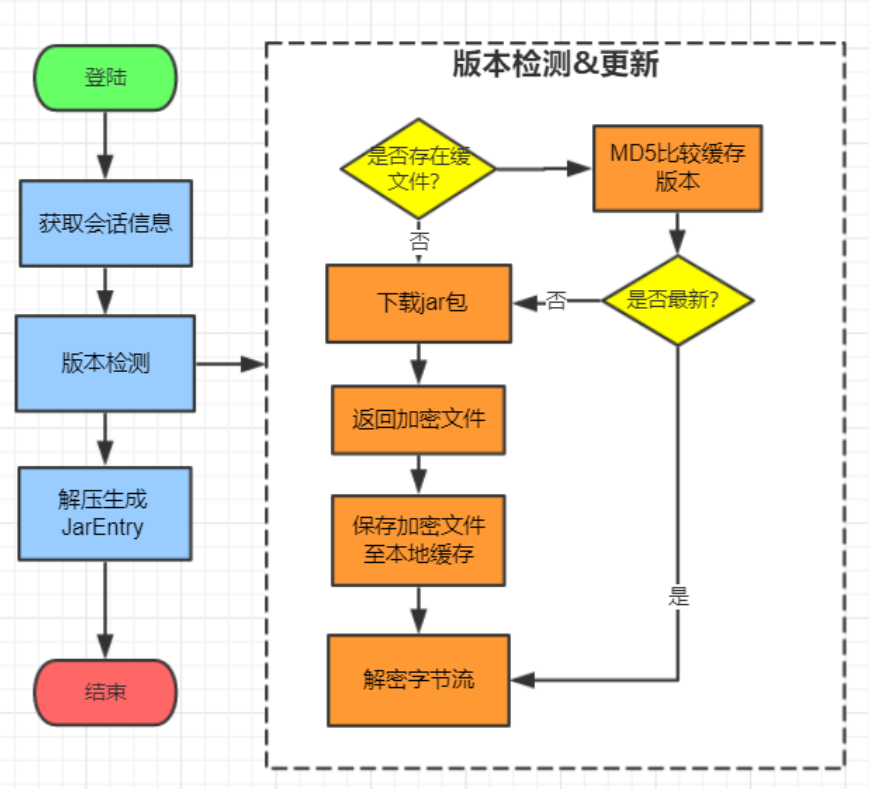
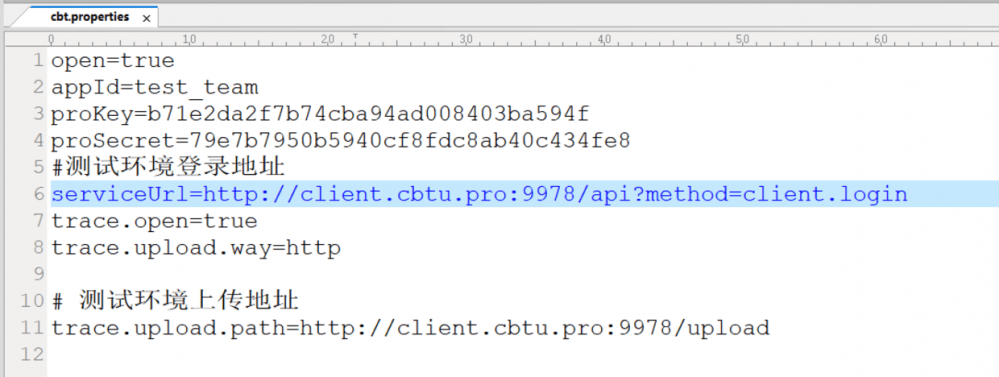
可以,urls可以设置多个。
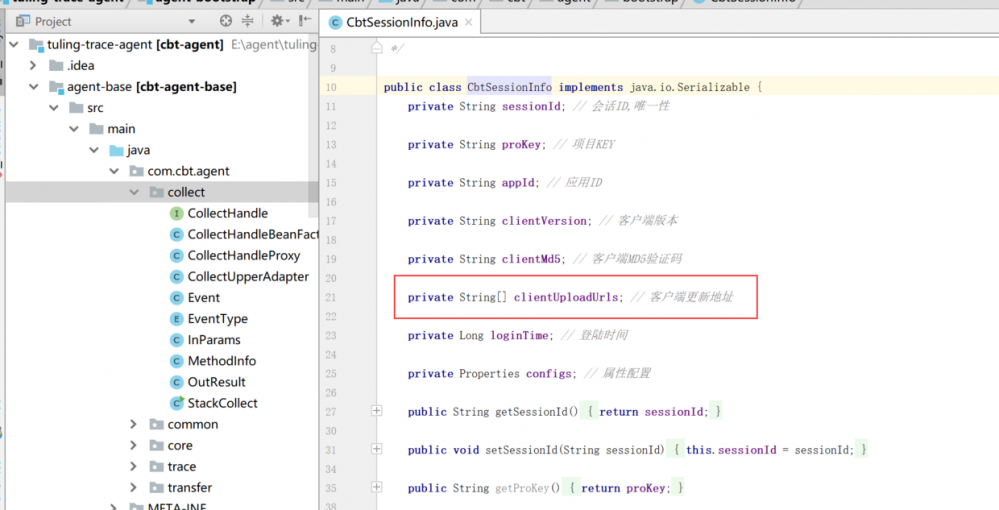
这样做的目的,就是为了服务端来控制客户端下载那个插件,客户端就下载那个插件。可以根据项目和应用进行调配。
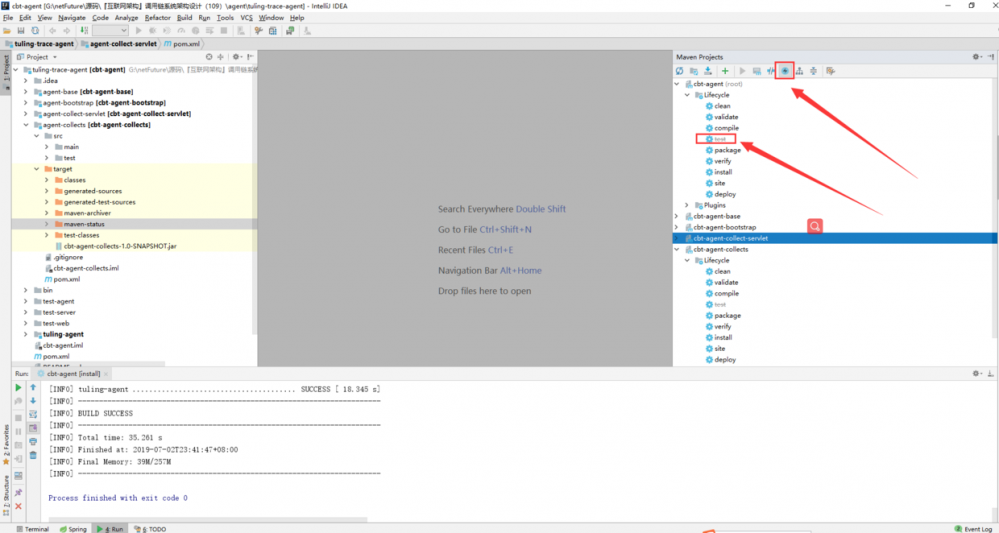
通过源码导入cbt-agent:idea跳过test直接install
生成对应的采集器jar包。然后获取jar包进行md5
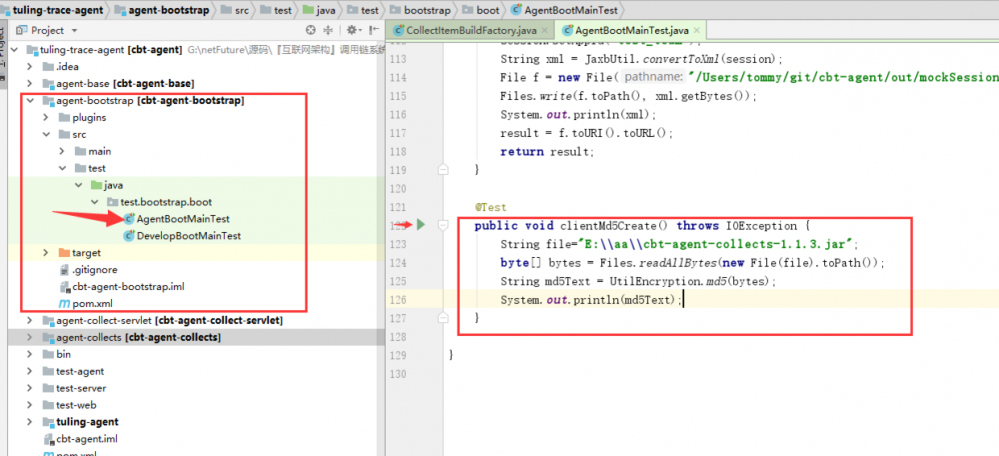
上传对应的jar包和md5值。对应的jar包名称,这些都是由服务端进行控制的。

PS:整个项目结构在源码中都是有的,2个项目,下次说下这2个项目的项目结构。顺便一步一步的让项目跑起来。
>>原创文章,欢迎转载。转载请注明:转载自,谢谢!>>原文链接地址:上一篇:已是最新文章
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

