经验分享:将微服务迁移到Spring WebFlux - allegro.tech
反应式编程在这几个月内一直是许多会议演讲的热门话题。找到简单的代码示例和教程并将它们应用于绿地新项目是毫不费力的。当需要从现有解决方案迁移时,特别是它是具有数百万用户和每秒数千个请求的生产服务时,事情变得有点复杂。在本文中,我想 通过一个Allegro微服务的例子讨论从 Spring Web MVC 到 Spring WebFlux 的迁移策略 。我将展示一些常见的陷阱,以及生产中的性能指标如何受迁移的影响。
改变的动机
在详细探讨迁移策略之前,让我们先讨论其变更的动机。其中一个由我的团队开发和维护的微服务,参与了2018年7月18日的重大Allegro停运(详见 尸检) )。虽然我们的微服务不是问题的根本原因,但由于线程池饱和,一些实例也崩溃了。临时修复是增加线程池大小并减少外部服务调用的超时; 然而,这还不够。
临时解决方案仅略微提高了外部服务延迟的吞吐量和弹性。我们决定转而使用非阻塞方法来彻底摆脱线程池作为并发的基础。
使用WebFlux的另一个动机是新项目,它使我们的微服务中的外部服务调用流程变得复杂。无论复杂程度如何增加,我们都面临着保持代码库可维护性和可读性的挑战。我们看到WebFlux比我们之前基于Java 8的解决方案(CompletableFuture可以模拟复杂的流程)更加友好。
什么是Spring WebFlux?
让我们从了解Spring WebFlux的内容和内容开始。Spring WebFlux是反应堆栈Web框架,定位为众所周知且广泛使用的Spring Web MVC的后续版本。创建新框架的主要目的是支持:
- 一种非阻塞方法,可以用少量线程处理并发并有效扩展,
- 函数式编程,它有助于使用流畅的API编写更多的声明性代码。
最重要的新功能是功能端点,事件循环并发模型和 反应式Netty服务器 。您可能会认为通过引入一个全新的堆栈和范例,WebFlux和Web MVC之间的兼容性已被打破。实际上,Pivotal致力于使共存尽可能轻松。
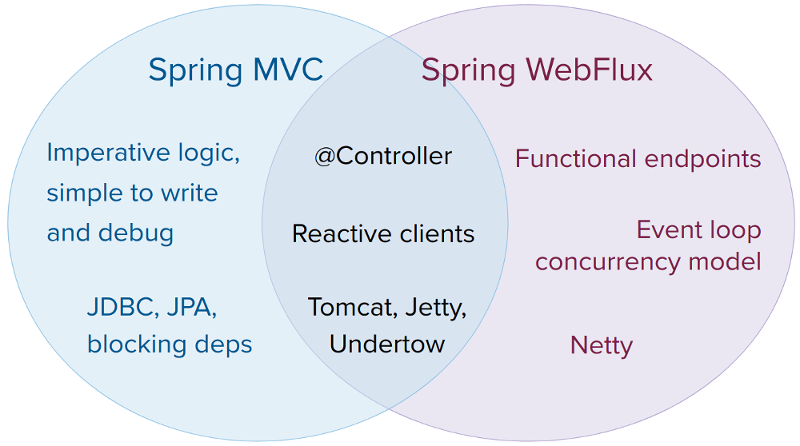
我们不会被迫将代码的每个方面都迁移到新方法。我们可以轻松地选择一些需要Reactive的东西(比如 反应式WebClient )并前进一小步。如果我们不认为它们提供真正的价值但是具有显着的变化成本,我们甚至可以省略一些功能的改进。此外,如果您熟悉 Undertow 或 Tomcat 配置 ,您不必使用Netty服务器。
什么时候(不)迁移?
每一种新兴技术都倾向于其炒作周期。玩一种新的解决方案,特别是在生产环境中,仅仅因为它新鲜,有光泽和嗡嗡声 - 可能导致沮丧,有时甚至是灾难性的后果。每个软件供应商都想宣传他的产品,并说服客户使用它。但是,Pivotal表现得非常负责任,密切关注迁移到WebFlux不是最好的想法。官方文件的 第1.1.4部分 详细介绍了这一点。最重要的一点是:
- 不要改变工作正常的东西。如果您的服务中没有性能或扩展问题 - 找一个更好的地方来尝试WebFlux。
- 堵塞API和WebFlux不是最好的朋友。他们可以合作,但从迁移到反应堆栈没有效率提升。你应该带着一点点的意见来接受这个建议。当代码中只有一些依赖项被阻塞时 - 有一些优雅的方法来处理它。当它们占多数时 - 您的代码变得更加复杂且容易出错 - 一个阻塞调用可以锁定整个应用程序。
- 团队的学习曲线,特别是如果没有反应性东西的经验,可能会很陡峭。你应该在迁移过程中非常注意人为因素。
我们来谈谈性能。对此有很多误解。反应Reactive并不意味着自动提升性能。此外,WebFlux文档警告我们,以非阻塞方式执行操作需要做更多工作。但是,每次呼叫的延迟或呼叫之间的相互依赖性越高,其益处就越大。反应性闪耀点:等待其他服务响应不会阻塞线程。因此,获得相同吞吐量所需的线程更少,线程越少意味着使用的内存越少。
始终建议检查独立来源以避免框架作者的偏见。在选择新技术时,一个很好的意见来源是 ThoughtWorks的 技术雷达 。他们报告了迁移到WebFlux后系统吞吐量和代码可读性的改进。另一方面,他们指出,思维的重大转变是成功采用WebFlux的必要条件。
总而言之,迁移到WebFlux有四个指标如果符合则可行:
- 当前的技术堆栈没有解决具有足够性能和可扩展性的问题。
- 对外部服务或数据库的调用很多,响应速度可能很慢。
- 现有的阻塞依赖项可以很容易地被替换为依赖。
- 开发团队面临新的挑战并愿意学习。
迁移战略
根据我们的迁移经验,我想介绍三阶段迁移策略。为什么3个阶段?
如果我们谈论具有大型代码库的实时服务,每秒数千个请求和数百万用户, 从头开始重写是一个相当大的风险。让我们看看如何在后续的小步骤中将应用程序从Spring Web MVC迁移到Spring WebFlux,从而实现从阻塞到非阻塞世界的平滑过渡。
第1阶段,入门 - 迁移一小段代码
通常,首先在系统的非关键部分尝试新技术是一种很好的做法。反应性技术也不例外。这个阶段的想法是只要找到一个非关键特性功能,它又是被封装在一个阻塞方法调用中,那就将其重写为非阻塞风格。让我们看看执行此阻塞方法的示例,该方法用于RestTemplate从外部服务检索结果。
Pizza getPizzaBlocking(<b>int</b> id) {
<b>try</b> {
<b>return</b> restTemplate.getForObject(<font>"http://localhost:8080/pizza/"</font><font> + id, Pizza.<b>class</b>);
} <b>catch</b> (RestClientException ex) {
<b>throw</b> <b>new</b> PizzaException(ex);
}
}
</font>
我们从丰富的WebFlux功能集中选择一件事 - 反应式WebClient - 并使用它以非阻塞方式重写此方法:
Mono<Pizza> getPizzaReactive(<b>int</b> id) {
<b>return</b> webClient
.get()
.uri(<font>"http://localhost:8080/pizza/"</font><font> + id)
.retrieve()
.bodyToMono(Pizza.<b>class</b>)
.onErrorMap(PizzaException::<b>new</b>);
}
</font>
现在是时候将我们的新方法与应用程序的其余部分连接起来了。非阻塞方法返回Mono,但我们需要一个普通类型。我们可以使用Mono.block()方法从中检索值。
Pizza getPizzaBlocking(<b>int</b> id) {
<b>return</b> getPizzaReactive(id).block();
}
最终,我们的方法仍在都塞等待。但是,它内部使用了非阻塞库。此阶段的主要目标是熟悉非阻塞API。这种更改对应用程序的其余部分是透明的,易于测试并可部署到生产环境中。
第二阶段,主菜 - 将关键路径转换为非阻塞方法
在使用WebClient转换一小段代码后,我们准备更进一步。第二阶段的目标是将应用程序的关键路径转换为所有层中的非阻塞 - 从HTTP客户端到处理外部服务响应的类,再到控制器。在这个阶段,重要的是避免重写所有代码。应用程序中较不重要的部分,例如没有外部调用或很少使用的部分,应该保持不变。我们需要关注非阻塞方法揭示其优势的领域。
<font><i>//parallel call to two services using Java8 CompletableFuture</i></font><font>
Food orderFoodBlocking(<b>int</b> id) {
<b>try</b> {
<b>return</b> CompletableFuture.completedFuture(<b>new</b> FoodBuilder())
.thenCombine(CompletableFuture.supplyAsync(() -> pizzaService.getPizzaBlocking(id), executorService), FoodBuilder::withPizza)
.thenCombine(CompletableFuture.supplyAsync(() -> hamburgerService.getHamburgerBlocking(id), executorService), FoodBuilder::withHamburger)
.get()
.build();
} <b>catch</b> (ExecutionException | InterruptedException ex) {
<b>throw</b> <b>new</b> FoodException(ex);
}
}
</font><font><i>//parallel call to two services using Reactor</i></font><font>
Mono<Food> orderFoodReactive(<b>int</b> id) {
<b>return</b> Mono.just(<b>new</b> FoodBuilder())
.zipWith(pizzaService.getPizzaReactive(id), FoodBuilder::withPizza)
.zipWith(hamburgerService.getHamburgerReactive(id), FoodBuilder::withHamburger)
.map(FoodBuilder::build)
.onErrorMap(FoodException::<b>new</b>);
}
</font>
使用.subscribeOn()方法可以轻松地将阻塞部分系统与非阻塞代码合并。我们可以使用默认的Reactor调度程序之一以及我们自己创建并提供的线程池ExecutorService。
Mono<Pizza> getPizzaReactive(<b>int</b> id) {
<b>return</b> Mono.fromSupplier(() -> getPizzaBlocking(id))
.subscribeOn(Schedulers.fromExecutorService(executorService));
}
此外,只需对控制器进行少量更改即可 - 将返回类型更改Foo为Mono<Foo>或Flux<Foo>。它甚至可以在Spring Web MVC中运行 - 您不需要将整个应用程序的堆栈更改为被动。第2阶段的成功实施为我们提供了非阻塞方法的所有主要优点。是时候测量并检查我们的问题是否已解决。
第3阶段,甜点 - 让我们改变WebFlux的一切!
我们可以在第2阶段之后做更多的事情。我们可以重写代码中不太关键的部分并使用Netty服务器而不是servlet。我们也可以删除@Controller注释并将端点重写为函数风格,尽管这是风格和个人偏好而非性能的问题。
这里的关键问题是:这些优势的成本是多少?代码可以一直重构,并且通常定义“足够好”的点是很有挑战性的。在我们的案例中,我们没有决定更进一步。
重写整个代码库需要很多工作。 帕累托原则 结果证明是有效的一次。我们认为我们已经取得了显着的收益,而后续的收益也相对较高。作为一般规则 - 当我们从头开始编写新服务时,获得WebFlux的所有特权是很好的。另一方面,当我们重构现有(微)服务时,通常最好尽可能少地完成工作。
迁移陷阱 - 经验教训
正如我之前所说,将代码迁移到非阻塞需要思想发生重大转变。我的团队也不例外 - 我们陷入了一些陷阱,主要是因为根植于阻塞和命令式编码实践。如果您打算将一些代码重写为WebFlux - 这里有一些准备好的具体内容供您使用!
问题1 - 在构建服务器中挂起集成测试
优秀的代码测试覆盖率是安全重构的最佳朋友。特别是集成测试可以确认我们在重写应用程序的大部分内容后感觉一切正常。在我们的例子中,大多数是框架甚至编程语言不可知 - 他们使用HTTP请求查询测试中的服务。不幸的是,我们注意到我们的集成测试有时会开始挂起。
这是一个令人震惊的信号 - 在迁移到WebFlux之后,从客户端的角度来看,服务应该表现相同。经过几天的研究,我们终于发现 Wiremock (我们的测试中使用的 模拟 库)与WebFlux启动器不完全兼容。经过进一步调查,我们了解到webmvc启动器的测试工作正常。 GitHub问题#914 详细介绍了这一点。
经验教训:
- 仔细检查您的测试库是否完全支持WebFlux。
- 在重构的早期阶段,不要将spring-boot-starter依赖从webmvc更改为webflux。尝试将代码重写为非阻塞,并且只有在servlet应用程序类型的一切正常工作时才将应用程序类型更改为响应。
问题2 - 挂起了单元测试
我们使用 Groovy + Spock 作为单元测试的基础。虽然WebFlux提供了新的令人兴奋的测试可能性,但我们尝试以尽可能少的努力使现有的单元测试适应非阻塞现实。当某些方法转换为return Mono<Foo>而不是Foo,通常在测试中跟随此方法.block()调用就足够了。否则,存根和模拟配置为返回foo,现在应该用反应类型包装它,通常返回Mono.just(foo)。
理论似乎很简单,但我们的测试开始挂起。幸运的是,以可重现的方式。出了什么问题?
在经典的阻塞方法中,当我们忘记(或故意省略)在存根或模拟中配置一些方法调用时,它只返回null。在许多情况下,它不会影响测试。但是,当我们的stubbed方法返回一个被动类型时,错误配置可能会导致它挂起,因为预期Mono或Flux永远不会解析。
学到的经验教训: 返回反应性类型的方法的存根或Mock,在测试执行期间调用,之前隐式返回 null,现在必须显式配置为至少返回Mono.empty()或Mono.just(some_empty_object)。
问题3 - 缺乏订阅
WebFlux初学者有时会忘记反应流往往尽可能地会惰加载。由于缺少订阅,以下功能永远不会向控制台打印任何内容:
Food orderFood(<b>int</b> id) {
FoodBuilder builder = <b>new</b> FoodBuilder().withPizza(<b>new</b> Pizza(<font>"margherita"</font><font>));
hamburgerService.getHamburgerReactive(id).doOnNext(builder::withHamburger);
</font><font><i>//hamburger will never be set, because Mono returned from getHamburgerReactive() is not subscribed to</i></font><font>
<b>return</b> builder.build();
}
</font>
教训: 每一个Mono和Flux应订阅。在控制器中返回反应式类型就是这种隐式订阅。
问题4 - .block()在Reactor线程中
正如我之前所展示的(在第1阶段),.block()有时用于将反应函数加入到阻塞代码中。
Food getFoodBlocking(<b>int</b> id) {
<b>return</b> foodService.orderFoodReactive(id).block();
}
在Reactor线程中无法调用此函数。这种尝试会导致以下错误:
block()/blockFirst()/blockLast() are blocking, which is not supported in thread reactor-http-nio-2
.block()只允许在其他线程中使用显式用法(请参阅参考资料.subscribeOn())。Reactor抛出一个异常并告知我们这个问题是有帮助的。不幸的是,许多其他方案允许将阻塞代码插入到Reactor线程中,这不会自动检测到。
学到的经验教训:.block()只能在scheduler中执行的代码中使用。更好的是避免使用.block()。
问题5 - 阻塞Reactor线程中的代码
没有什么能阻止我们将阻塞代码添加到被动流中。而且,我们不需要使用.block()- 我们可以通过使用可以阻止当前线程的库无意识地引入阻塞。请考虑以下代码示例。第一个类似于正确的“反应性”延迟。
Mono<Food> getFood(<b>int</b> id) {
<b>return</b> foodService.orderFood(id)
.delayElement(Duration.ofMillis(1000));
}
另一个示例模拟了一个危险的延迟,它阻塞了订户线程。
Mono<Food> getFood(<b>int</b> id) throws InterruptedException {
<b>return</b> foodService
.orderFood(id)
.doOnNext(food -> Thread.sleep(1000));
}
一目了然,这两个版本似乎都有效。当我们在localhost上运行此应用程序并尝试请求服务时,我们可以看到类似的行为。“Hello,world!”在延迟1秒后返回。然而,这种观察极具误导性。在更高的流量下,我们的服务响应会发生巨大变化 让我们使用 JMeter 来获得一些性能特征。
使用100个线程查询了两个版本。我们可以看到,具有反应式延迟(上一段代码)的版本在重负载下运行良好,另一方面,具有阻塞延迟(下一段代码)的版本不能提供任何可观的流量。
为什么这么危险?如果延迟与外部服务调用相关联,只要其他服务快速响应,一切正常。这是一颗滴答作响的定时炸弹。这样的代码甚至可以在生产环境中生存几天,并在您最不期望的时候导致突然中断。
经验教训:
- 始终仔细检查在反应式环境中使用的库。
- 对应用程序进行性能测试,尤其是考虑外部调用的延迟。
- 使用 BlockHound 等特殊库,可以检测隐藏的阻塞调用,提供宝贵的帮助。
问题6 - WebClient未消费响应
WebClient .exchange()方法的文档明确指出: 您必须始终使用响应的主体或实体方法之一来确保释放资源。 官方WebFlux文档的第2.3章 给出了类似的信息。这个要求很容易被遗漏,主要是当我们使用.retrieve()方法时,是.exchange()的一个快捷方式。我们偶然发现了这样一个问题。我们正确地将有效响应映射到对象,并在出现错误时完全忽略响应。
Mono<Pizza> getPizzaReactive(<b>int</b> id) {
<b>return</b> webClient
.get()
.uri(<font>"http://localhost:8080/pizza/"</font><font> + id)
.retrieve()
.onStatus(HttpStatus::is5xxServerError, clientResponse -> Mono.error(<b>new</b> Pizza5xxException()))
.bodyToMono(Pizza.<b>class</b>)
.onErrorMap(PizzaException::<b>new</b>);
}
</font>
只要外部服务返回有效响应,上面的代码就能很好地工作。在前几个错误响应后不久,我们可以在日志中看到令人担忧的消息:
ERROR 3042 --- [ctor-http-nio-5] io.netty.util.ResourceLeakDetector : LEAK: ByteBuf.release() was not called before it's garbage-collected. See http:<font><i>//netty.io/wiki/reference-counted-objects.html for more information.</i></font><font> </font>
资源泄漏意味着我们的服务将崩溃。在几分钟,几小时或几天内 - 它取决于其他服务错误计数。此问题的解决方案很简单:使用错误响应生成错误消息。现在它被正确消费了。
经验教训: 始终在考虑外部服务错误的情况下测试您的应用程序,尤其是在高流量时。
问题7 - 意外的代码执行
Reactor有许多有用的方法,有助于编写富有表现力和声明性的代码。但是,其中一些可能有点棘手。请考虑以下代码:
String valueFromCache = <font>"some non-empty value"</font><font>;
<b>return</b> Mono.justOrEmpty(valueFromCache)
.switchIfEmpty(Mono.just(getValueFromService()));
</font>
我们使用类似的代码检查特定值的缓存,然后在缺少值时调用外部服务。作者的意图似乎很明确:getValueFromService() 仅在缺少缓存值的情况下执行。但是,此代码每次都会运行,即使是缓存命中也是如此。赋给.switchIfEmpty()的参数不是lambda,而是Mono.just()直接执行作为参数传递的代码。
显而易见的解决方案是使用Mono.fromSupplier()并将条件代码作为lambda传递,如下例所示:
String valueFromCache = <font>"some non-empty value"</font><font>;
<b>return</b> Mono.justOrEmpty(valueFromCache)
.switchIfEmpty(Mono.fromSupplier(() -> getValueFromService()));
</font>
经验教训: Reactor API有许多不同的方法。始终考虑参数是应该按原样传递还是用lambda包装。
迁移带来的好处
总结一下,在迁移到WebFlux之后检查我们服务的生产指标。明显而直接的影响是应用程序使用的线程数量减少。有趣的是,我们没有将应用程序类型更改为Reactive(我们仍然使用servlet,有关详细信息,请参阅第3阶段),但Undertow工作线程的使用也变小了一个数量级。
低级指标如何受到影响?我们观察到更少的垃圾收集,并且他们花费的时间更少。
此外,响应时间略有下降,但我们没有预料到这样的效果。其他指标(如CPU负载,文件描述符使用情况和消耗的总内存)未发生变化。我们的服务也做了很多工作,这与调用无关。将流量迁移到HTTP客户端和控制器周围的响应是至关重要的,但在资源使用方面并不重要。正如我在开始时所说的那样, 迁移的预期收益是延迟的可扩展性和弹性。我们确信我们已经实现了这一目标。
结论
你在绿地新项目上工作吗?这是一个熟悉WebFlux或其他反应框架的好机会。
您是否正在迁移现有的微服务?考虑到文章中涉及的因素,不仅仅是技术因素 - 检查时间和人员使用新解决方案的能力。有意识地决定不盲目信任技术炒作。
始终测试您的应用程序 覆盖外部呼叫延迟和错误的集成和性能测试在迁移过程中至关重要。请记住,反应性思维不同于众所周知的阻碍,命令式方法。
玩得开心,构建弹性微服务!
正文到此结束
- 本文标签: JMeter REST src cache zab db tar UI 注释 软件 client ORM Reactor tab 配置 时间 value build Service 缓存 部署 测试 https map 代码 实例 函数式编程 模型 并发 服务器 git 安全 解析 总结 线程池 id 覆盖率 web ip cat GitHub HTML 锁 文章 IO 微服务 zip tomcat 产品 Netty 初学者 开发 删除 NIO lambda java servlet 线程 API CTO 参数 http executor 单元测试 spring cpu负载 数据库 数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

