Android安全之旅—ProGuard篇
ProGuard是一个压缩、优化和混淆Java字节码文件的免费的工具,是Android平台重要的防护手段之一。
ProGuard功能
ProGuard主要功能及执行流程如下图所示:
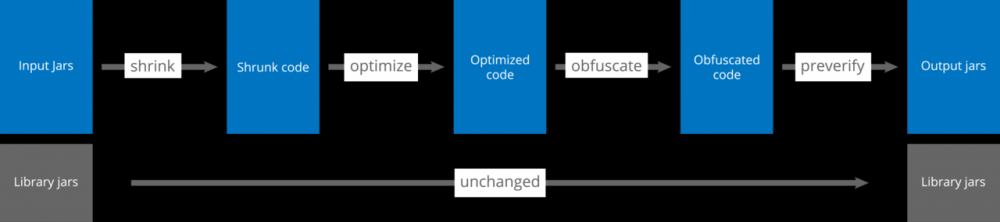
- 输入jar或者aar等格式的java字节码文件集合并且传入自定义配置
- shrink流程删除无用的类、方法和属性
- optimize流程进一步优化字节码,主要表现为优化逻辑
- obfuscate流程对优化后的字节码进行混淆,将类、方法和属性名称重新命名为短的且无意义的名字,缩减包大小并且进行防护
- preverify为提前校验的过程,并且将校验的信息添加到类文件中
重点介绍一下上述流程的工作机制
-
Shrink
Shrink是压缩字节码的过程,主要是删除Java字节码集合中没用的类、方法和属性定义。该过程和Java的GC判断流程很像,从ROOT搜索,走过的路径可被称为调用链,通过调用链判断哪些类、方法和属性没有被使用,然后删除掉。那么这些ROOT究竟是怎么被定义的? 先看下Android中proguard文件中的配置片段:
-keepattributes *Annotation*
-keepclasseswithmembernames class * {
native <methods>;
}
-keepclassmembers public class * extends android.view.View {
void set*(***);
*** get*();
}
复制代码
看到这里是不是突然明白,在proguard文件中都是输入到ProGuard库中的参数集合,所有添加keep标签的类、方法以及属性都是ROOT,被认为调用入口。
- Optimize
Optimize进一步优化字节码,该过程主要优化代码逻辑,比如if判断中条件始终为true,则可以把false分之的逻辑删除,比如一个类中的只有一个方法且只被调用一次,这个时候就可以将方法块移到调用处并且删除原来的类和方法。该过程也需要知道调用链,确认好调用链才能优化代码逻辑。 - Obfuscate
Obfuscate将类、方法和属性重命名成简短且无意义的名字,这一过程进一步压缩字节码大小,别切混淆逻辑,是常用的防护手段。 - Preverify
Preverify为提前校验,并且将校验的类信息添加到类文件中,该过程在Android里默认是关闭的。
混淆分析
目前在Android中主要使用ProGuard库中的混淆功能,通过混淆压缩字节码大小并且进行防护,之前分析一个样本,通过JADX打开后如下:

上图中成员变量被混淆成中文,并且方法中有中文也有英文,这里主要分析一下ProGuard混淆逻辑及如何订制自己的混淆字符库。
ProGuard混淆逻辑
使用JADX打开ProGuard.jar并且找到入口类:
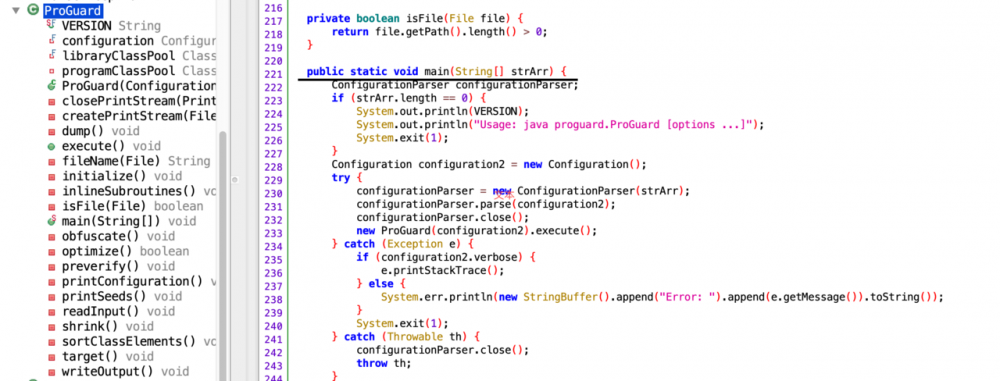
这里分享一个找入口的技巧:运行jar包且不输入任何参数,这个时候jar包肯定会输出错误信息并且退出,全局搜索错误信息就能找到入口类,如上图中会输出“Usage: java proguard.ProGuard [options ...]”错误。
通过上面的main方法找到如下处理:

这里可以很清晰看出ProGuard按顺序执行shrink,Optimize,Obfuscate,Preverify过程,直接看obfuscate方法:

在类Obfuscator中的execute方法找到上图设置NameFactory过程,先判断外部是否设置了NameFactory,如果有就使用外部设置,如果没有则使用SimpleNameFactory作为库输出名子,先看下SimpleNameFactory输出名字的逻辑,外部调用nextName获取名称,重点看下newName方法:
private String newName(int i) {
int i2 = this.generateMixedCaseNames ? 52 : CHARACTER_COUNT;
int i3 = i / i2;
char charAt = charAt(i % i2);
if (i3 != 0) {
return new StringBuffer().append(name(i3 - 1)).append(charAt).toString();
}
return new String(new char[]{charAt});
}
复制代码
其中CHARACTER_COUNT值为26,这里的意思为是否只使用a-z共26字符还是使用a-z和A-Z共52字符,生成名字的逻辑也很简单:如现在使用26字符集合且生成的名字为z,则下一个名字为aa,依次类推当字符用到最后则增加一位。
上面SimpleNameFactory分析完成,再分析一下另一个分支DictionaryNameFactory中生成名字的方法:

这里逻辑很简单,如果当前list中有足够的字符就使用当前,如果不够了则使用nameFactory的字符生成方法,这里有2个事情需要搞清楚:
- list字符集合怎么生成?
- nameFactory的字符生成方法?
看下DictionaryNameFactory的构造方法:
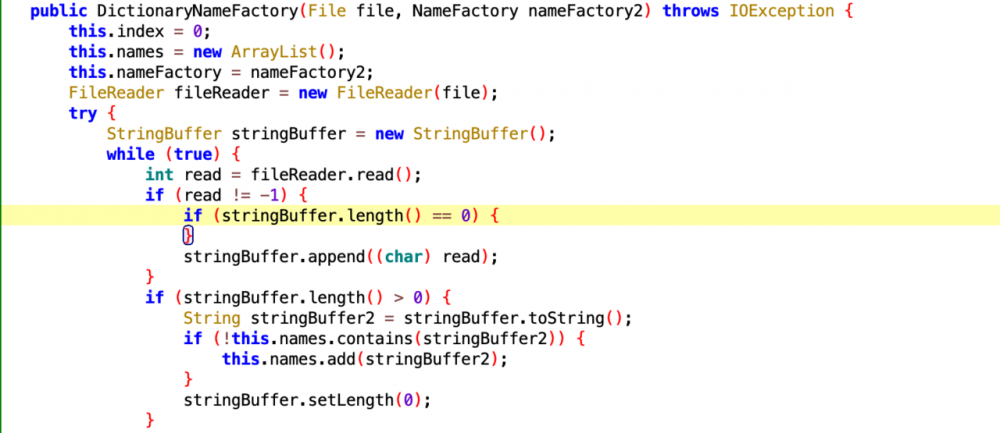
看到这里就明白:list字符是从文件中读取的并且去重,nameFactory是外面传过来的, 全局搜一下DictionaryNameFactory构造方法被调用处,最后找到3处调用:
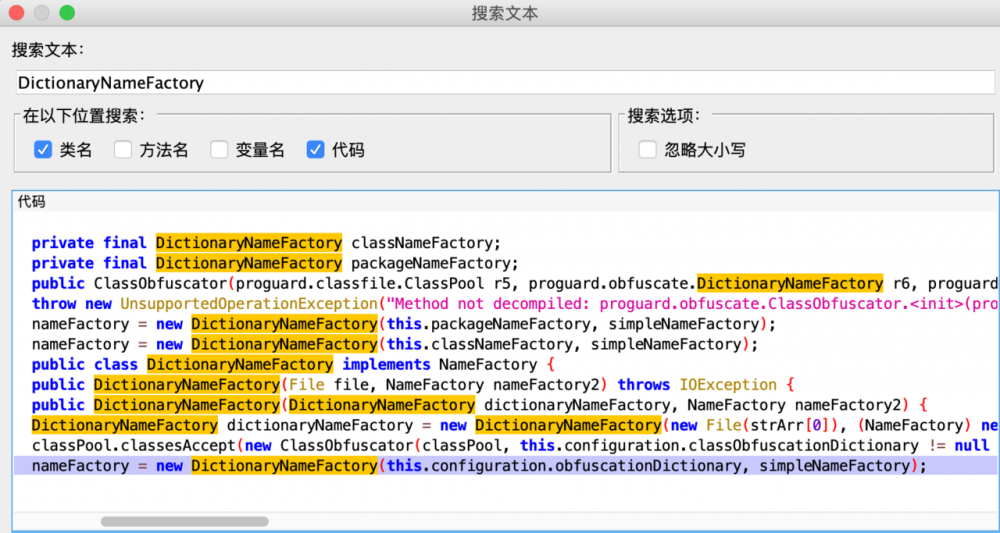
传入的NameFactory都是SimpleFactory,文件参数分别是packageNameFactory,classNameFactory和ObfucationDictionary,再跟进去看发现在Configuration中有如下定义:
public static final String OBFUSCATION_DICTIONARY_OPTION = "-obfuscationdictionary"; public static final String CLASS_OBFUSCATION_DICTIONARY_OPTION = "-classobfuscationdictionary"; public static final String PACKAGE_OBFUSCATION_DICTIONARY_OPTION = "-packageobfuscationdictionary"; 复制代码
看到这里应该明白了,可以通过设置字符集配置完成包名,类名,方法名以及属性名配置。
这里总结一下:
- 如果不设置混淆字典,则默认使用a-z 26位英文字母混淆包名,类名,方法名,属性名
- 可以通过配置分别设置包名,类名,方法名,属性名混淆字符集,当配置的字符集不够用时,会使用a-z命名
混淆升级
上面介绍了混淆的机制以及设置自定义混淆字符集的方法,这里介绍两种设置字符集的方法并且对比优缺点。
- 直接在配置文件中设置字符集
在DEMO工程中的proguard-rules.pro中添加如下信息:
-obfuscationdictionary ./dictionary -classobfuscationdictionary ./dictionary -packageobfuscationdictionary ./dictionary 复制代码
然后再在同级目录创建dictionary文件,里面设置测试字符集:
_ __ ___ ____ _____ ______ 复制代码
这里是下划线,看下最后的效果:

哈哈哈,看看现在这个混淆结果,你得有多大的耐心才能分析这样的样本。
-
修改ProGuard.jar
直接修改SimpleNameFactory中生成字符的方法生成新的ProGuard.jar
修改ProGuard.jar方案我没有亲自试,修改也比较简单。
这里对比一下上述两种方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 配置中设置字典 | 方便配置 | 当字符集使用完会使用默认的a-z |
| 修改ProGuard.jar | 能够完全掌握字符集使用 | 需要修改库 |
总结
本篇主要介绍ProGaurd库的功能,重点讲解了一下混淆相关,以及如何利用混淆功能提高应用安全防护, 这里提醒一下:设置字符集的时候也要注意包大小,原生a-z都是占用1个字节,如果设置中文或者其他字符就要衡量一下了。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

