Java Web应用服务器之一——Tomcat监控选型及实践
监控选型
Tomcat Manager和Psi-probe是不错的可视化监控工具,能够很好地查看Tomcat状态信息(比如单位时间请求数,线程状态等)。在生产环境中,随着Tomcat实例的不断增加,维护不同实例上的Manager控制台会显得有些繁琐,同时,为了与企业监控系统、运维仪表盘等结合,有必要选择兼容性和适配性更好的监控工具。

如今,企业微服务的流行和CI/CD的强需求性,要求我们的服务在易于开发和维护的同时,具有伸缩性强、快速交付等特点。在此环境下,Tomcat+Prometheus+Grafana能够很好的与企业已有架构适配,并能够很好的与其他中间件服务监控整合到一起。Prometheus作为新一代的云原生监控系统,鼓励用户监控服务的内部状态,让用户可以获取服务和应用内部真正的运行状态。
容器环境下Tomcat+Prometheus+Grafana简图如下:
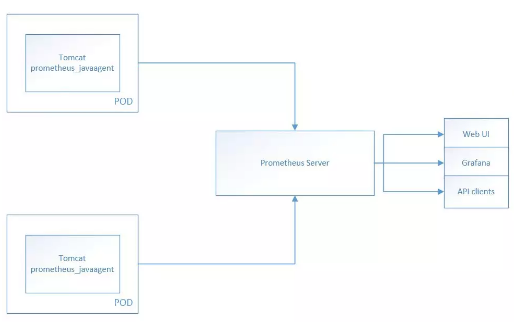
在实际部署中,可以简单分为如下几个步骤:
1、下载jmx_prometheus_javaagent (https://github.com/prometheus/jmx_exporter),若为容器环境,可将jmx_prometheus_javaagent与Tomcat一起打进运行镜像。
2、Tomcat启动时,JAVA_OPTS增加Javaagent和Tomcat config.yaml (https://github.com/prometheus/jmx_exporter/blob/master/example_configs/Tomcat.yml )配置,例如:JAVA_OPTS=”-javaagent:/var/tomcat/jmx_prometheus_javaagent-0.3.1.jar=port:/vat/tomcat/conf/config.xml”(port为实际端口)。
3、Prometheus添加Tomcat的job_name。
监控指标梳理
在《SRE: Google运维解密》一书中指出,监控系统需要能够有效的支持白盒监控和黑盒监控。通过白盒监控能够了解其内部的实际运行状态,通过对监控指标的观察能够预判可能出现的问题,从而对潜在的不确定因素进行优化。而黑盒监控,常见的如HTTP探针,TCP探针等,可以在系统或者服务在发生故障时能够快速通知相关的人员进行处理。
监控的四个黄金指标可以在服务级别帮助我们更好地衡量终端用户体验、服务中断、业务影响等层面的问题。主要关注以下四种类型的指标:错误,延迟,流量以及饱和度。
通过对黑盒、白盒监控的理解,结合监控的四个黄金指标,针对Tomcat的重要监控指标,可以从以下几个方面进行考虑:
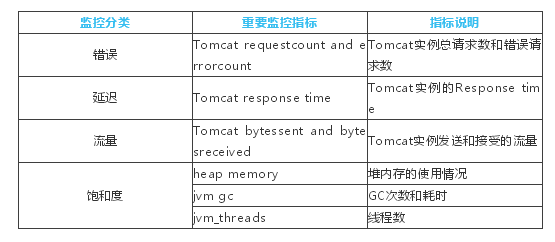
监控实践
错误
错误监控关注的是当前应用或系统发生的错误请求。针对Tomcat错误监控,主要监控指标为Tomcat错误请求数及与请求总数之间的比例,这些多为显式的错误。关于隐式的错误(比如状态码响应200,实际业务流程却是失败的),通常需要根据业务场景的不同,在服务中添加钩子及业务逻辑监控来实现。
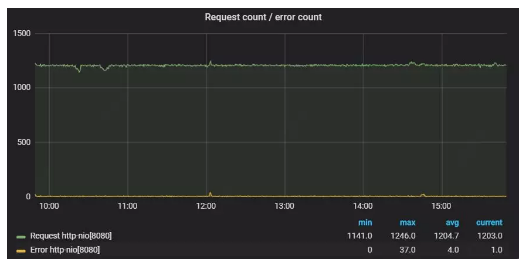
图1:某Tomcat实例在1000+qps下请求数和错误数的比例
当然,我们也可以借助ELK等工具,对Tomcat上游代理或LB进行整体的错误状态码统计,方便我们更好的定位错误,以及在发生5xx错误时考虑如何“快速失败”,来减少错误对系统性能带来的影响。
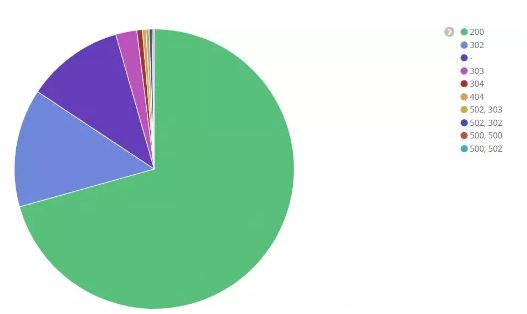
图2:通过Tomcat上游代理采集的状态码统计
延迟
延迟监控关注的是服务请求所需时间。针对Tomcat延迟监控,主要监控指标为Tomcat实例的Response time。同时,我们也可以采用黑盒监控中的HTTP语义探测来采集Tomcat对应域名的全链路延迟,发送指定GET、POST、HEAD等请求,来匹配状态码及服务器的返回内容。
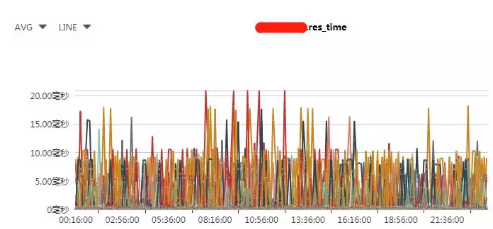
图3:某产品线下多个Tomcat实例整体的response time汇总
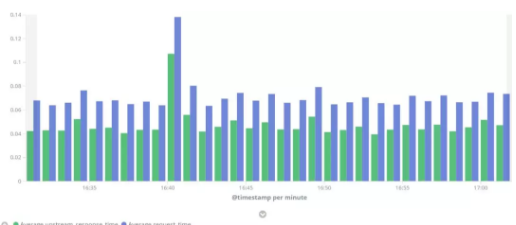
图4:通过Tomcat上游代理采集的平均请求时间和Tomcat平均响应时间
流量
流量监控关注的是当前系统或应用的流量,以便更好地衡量服务的承载能力。针对Tomcat流量监控,我们需要关注Tomcat实例发送和接收的流量。
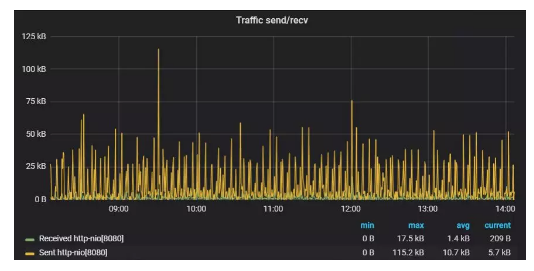
图5:某Tomcat实例发送和接收的流量
饱和度
饱和度监控关注的是系统或应用对资源的利用率,强调最能影响服务状态的受限制的资源。
不同的系统或应用对饱和度监控的需求各不相同,但共性是在服务性能明显下降时,起决定性的状态指标。针对Tomcat饱和度监控,可以从堆内存、线程数、GC次数及耗时等方面出发,在告警发生前后,通过查看各个指标的变化曲线,快速定位问题原因。
Tomcat线程池
对于Tomcat线程池初始配置的采集,可以根据不同业务场景,不同实例的压力,来进行调整,比如maxThreads、acceptCount等。

图6:某Tomcat实例线程池相关的默认配置
JVM监控
对于Tomcat JVM的监控,通常我们需要关注堆内存的使用情况、GC的次数和耗时、以及对JVM线程数的监控。
JVM堆内存监控
Java Heap是JVM所管理的内存中最大的一块,被所有线程所共享,用来存放对象实例。因此,堆内存的使用情况至关重要。
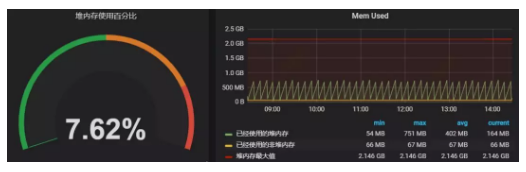
图7:某Tomcat实例堆内存的使用情况
- GC次数和耗时
通过查看单位时间内GC次数和耗时,能够让我们针对不同的业务场景,选择不同的垃圾回收器,从而进一步提高性能。
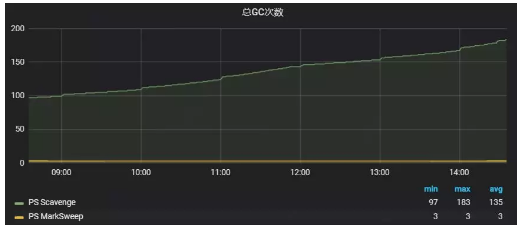
图8:某Tomcat实例默认垃圾回收器总GC次数曲线
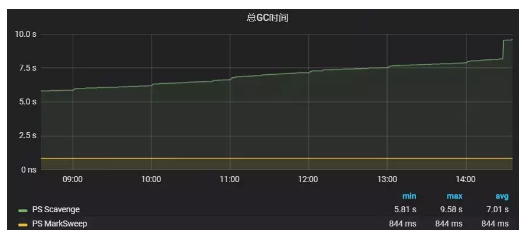
图9:某Tomcat实例默认垃圾回收器总GC时间曲线
- JVM线程数监控
JVM线程数的曲线统计,能够让我们更直观的看到JVM线程当前的运行情况。
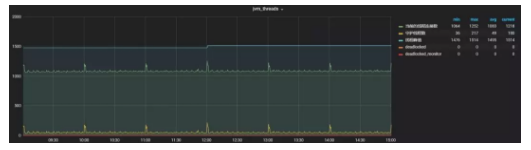
图10:某Tomcat实例JVM线程相关的统计
写在最后
通过对Tomcat重要监控指标的采集以及监控,帮助我们更方便地完成日常巡检,提高先于故障发现问题的能力,提高故障发生时的定位效率,从而更好地提高稳定性。
附:
jmx_prometheus_javaagent:
https://github.com/prometheus/jmx_exporter
Tomcat jmx_exporter:
https://github.com/prometheus/jmx_exporter/blob/master/example_configs/Tomcat.yml
本期作者:蒲公英
京东云
应用研发部
Tomcat是一款开源的轻量级Web应用服务器,广泛应用于云服务平台及企业应用系统,是最受欢迎的Java web应用服务器之一。因此,对于Tomcat的监控显得尤为重要,能让我们在不同场景下了解Tomcat的运行情况,进而能够更好的进行调优。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

