拆解大数据总线平台DBus的系统架构
mysql 日志抽取模块由两部分构成:
- canal server:负责从mysql中抽取增量日志。
- mysql-extractor storm程序:负责将增量日志输出到kafka中,过滤不需要的表数据,保证at least one和高可用。
我们知道,虽然mysql innodb有自己的log,mysql主备同步是通过binlog来实现的。而binlog同步有三种模式:Row 模式,Statement 模式,Mixed模式。因为statement模式有各种限制,通常生产环境都使用row模式进行复制,使得读取全量日志成为可能。
通常我们的mysql布局是采用 2个master主库(vip)+ 1个slave从库 + 1个backup容灾库 的解决方案,由于容灾库通常是用于异地容灾,实时性不高也不便于部署。
为了最小化对源端产生影响,我们读取binlog日志从slave从库读取。
读取binlog的方案比较多,DBus也是站在巨人的肩膀上,对于Mysql数据源使用阿里巴巴开源的Canal来读取增量日志。这样做的好处是:
- 不用重复开发避免重复造轮子
- 享受canal升级带来的好处
关于Canal的介绍可参考: github.com/alibaba/can… 由于canal用户抽取权限比较高,一般canal server节点也可以由DBA组来维护。
日志抽取模块的主要目标是将数据从canal server中读出,尽快落地到第一级kafka中,避免数据丢失(毕竟长时间不读日志数据,可能日志会滚到很久以前,可能会被DBA删除),因此需要避免做过多的事情,主要就做一下数据拆包工作防止数据包过大。
从高可用角度考虑,在使用Canal抽取过程中,采用的基于zookeeper的Canal server高可用模式,不存在单点问题,日志抽取模块extractor也使用storm程序,同样也是高可用架构。
不同数据源有不同的日志抽取方式,比如oracle,mongo等都有相应的日志抽取程序。
DBus日志抽取模块独立出来是为了兼容这些不同数据源的不同实现方式。
1.2 增量转换模块(Stream)
增量数据处理模块,根据不同的数据源类型的格式进行转换和处理。
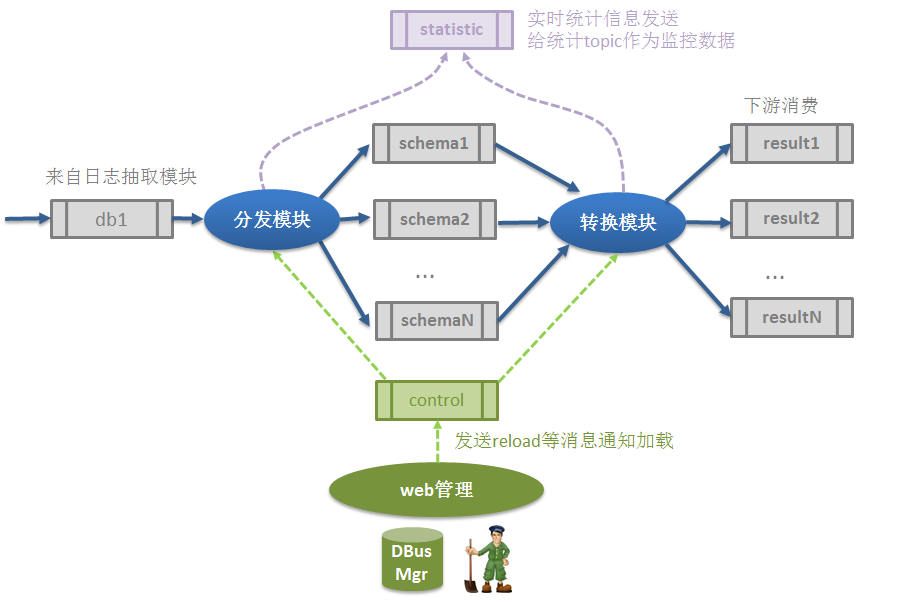
1)分发模块dispatcher
- 将来自数据源的日志按照不同的schema分发到不同topic上。这样做的目的
- 是为了数据隔离(因为一般不同的shema对应不同的数据库)
- 是为了分离转换模块的计算压力,因为转换模块计算量比较大,可以部署多个,每个schema一个提高效率。
2)转换模块appender
- 实时数据格式转换:Canal数据是protobuf格式,需要转换为我们约定的UMS格式,生成唯一标识符ums_id和ums_ts等;
- 捕获元数据版本变更:比如表加减列,字段变更等,维护版本信息,发出通知触发告警
- 实时数据脱敏:根据需要对指定列进行脱敏,例如替换为***,MD5加盐等。
- 响应拉全量事件:当收到拉全量请求时为了保证数据的相应顺序行,会暂停拉增量数据,等全量数据完成后,再继续。
- 监控数据:分发模块和转换模块都会响应心跳event,统计每一张表在两次心跳中的数据和延时情况,发送到statistic作为监控数据使用。
- 分发模块和转换模块都会相应相关reload通知事件从Mgr库和zk上进行加载配置操作。
1.3 全量拉取模块(FullPuller)
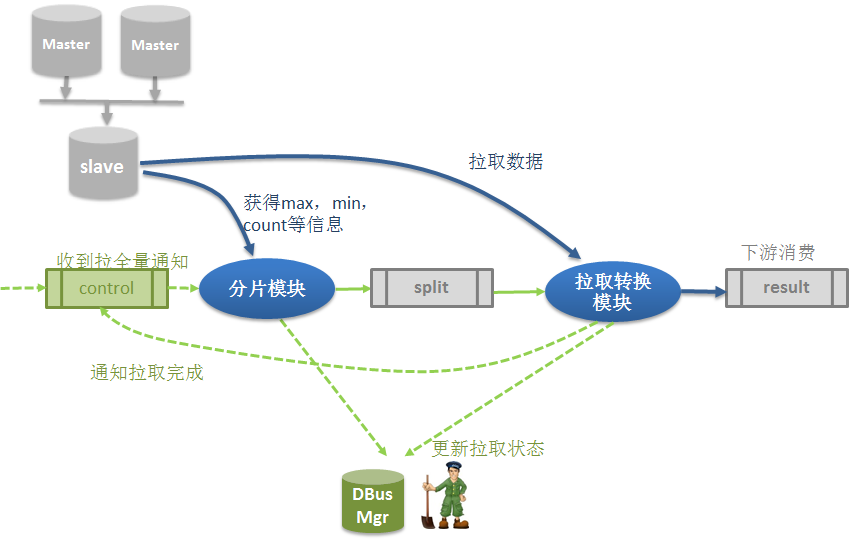
全量拉取可用于初始化加载(Initial load), 数据重新加载,实现上我们借鉴了sqoop的思想。将全量过程分为了2 个部分:
1)数据分片
分片读取max,min,count等信息,根据片大小计算分片数,生成分片信息保存在split topic中。下面是具体的分片策略:
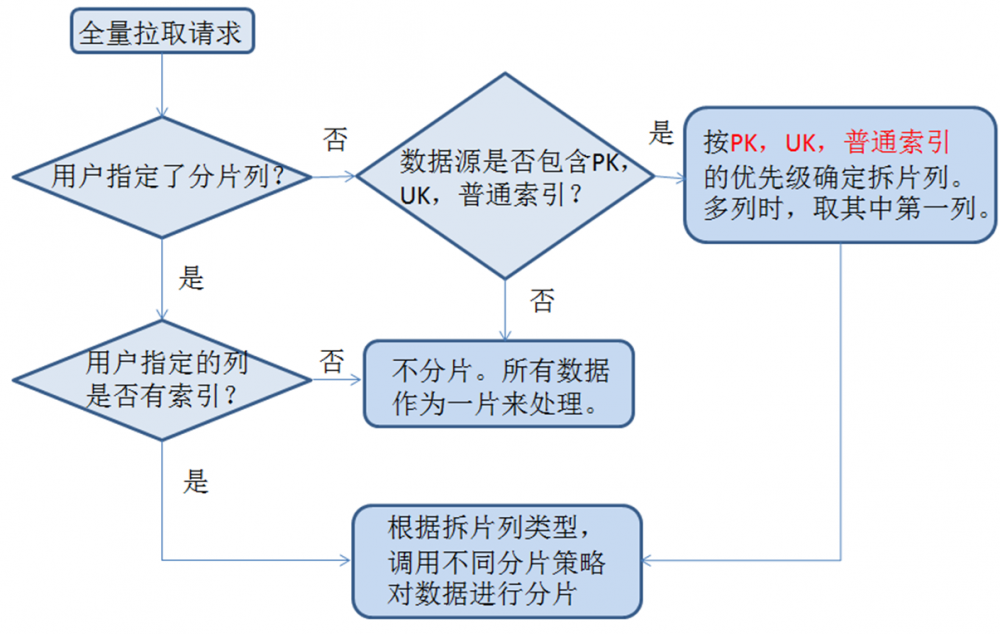
以实际的经验,对于mysql InnDB,只有使用主键索引进行分片,才能高效。因为mysql innDB的主键列与数据存储顺序一致。
2)实际拉取
每个分片代表一个小任务,由拉取转换模块通过多个并发度的方式连接slave从库进行拉取。 拉取完成情况写到zookeeper中,便于监控。
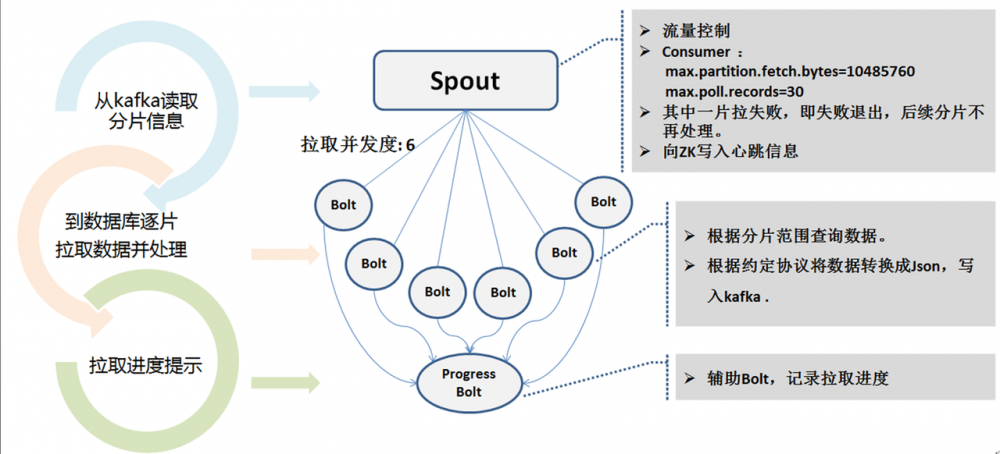
全量拉取对源端数据库是有一定压力的,我们做法是:
- 从slave从库拉取数据
- 控制并发度6~8
- 推荐在业务低峰期进行
全量拉取不是经常发生的,一般做初始化拉取一次,或者在某种情况下需要全量时可以触发一次。
1.3 全量和增量的一致性
在整个数据传输中,为了尽量的保证日志消息的顺序性,kafka我们使用的是1个partition的方式。在一般情况下,基本上是顺序的和唯一的。 但如果出现写kafka异步写入部分失败, storm也用重做机制,因此,我们并不严格保证exactly once和完全的顺序性,但保证的是at least once。
因此ums_id_变得尤为重要。 对于全量抽取,ums_id是一个值,该值为全量拉取event的ums_id号,表示该批次的所有数据是一批的,因为数据都是不同的可以共享一个ums_id_号。ums_uid_流水号从zk中生成,保证了数据的唯一性。 对于增量抽取,我们使用的是 mysql的日志文件号 + 日志偏移量作为唯一id。Id作为64位的long整数,高6位用于日志文件号,低13位作为日志偏移量。 例如:000103000012345678。 103 是日志文件号,12345678 是日志偏移量。 这样,从日志层面保证了物理唯一性(即便重做也这个id号也不变),同时也保证了顺序性(还能定位日志)。通过比较ums_id_就能知道哪条消息更新。
ums_ts_的价值在于从时间维度上可以准确知道event发生的时间。比如:如果想得到一个某时刻的快照数据。可以通过ums_ts 来知道截断时间点。
二、日志类数据源的实现
业界日志收集、结构化、分析工具方案很多,例如:Logstash、Filebeat、Flume、Fluentd、Chukwa. scribe、Splunk等,各有所长。在结构化日志这个方面,大多采用配置正则表达式模板:用于提取日志中模式比较固定、通用的部分,例如日志时间、日志类型、行号等。对于真正的和业务比较相关的信息,这边部分是最重要的,称为message部分,我们希望使用可视化的方式来进行结构化。
例如:对于下面所示的类log4j的日志:
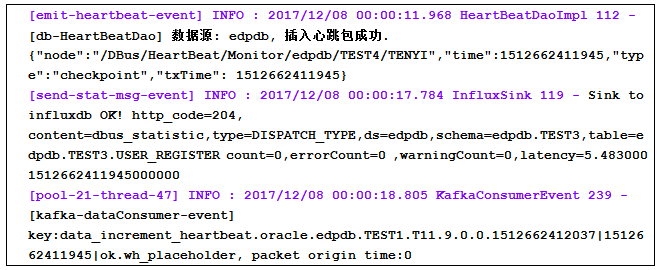
如果用户想将上述数据转换为如下的结构化数据信息:
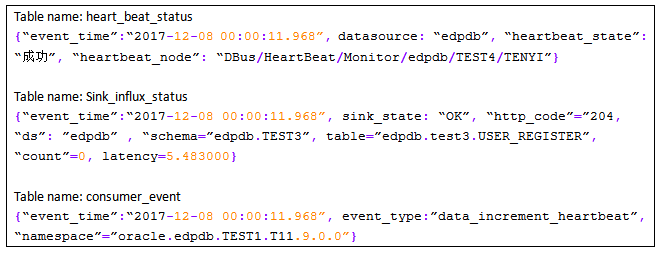
我们称这样的日志为“数据日志”
DBUS设计的数据日志同步方案如下:
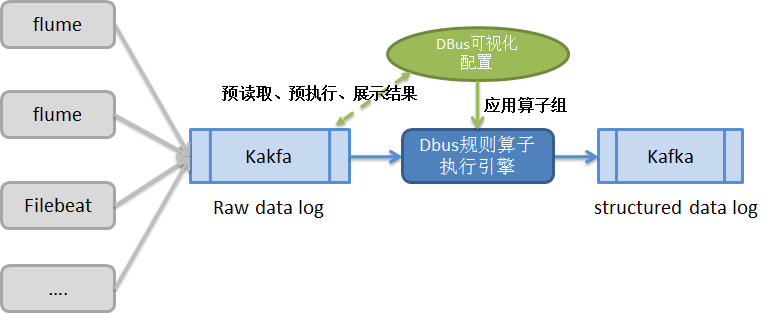
- 日志抓取端采用业界流行的组件(例如Logstash、Flume、Filebeat等)。一方面便于用户和业界统一标准,方便用户的整合;另一方面也避免无谓的重造轮子。抓取数据称为原始数据日志(raw data log)放进Kafka中,等待处理。
- **提供可视化界面,配置规则来结构化日志。**用户可配置日志来源和目标。同一个日志来源可以输出到多个目标。每一条“日志源-目标”线,中间数据经过的规则处理用户根据自己的需求来自由定义。最终输出的数据是结构化的,即:有schema约束,可以理解为类似数据库中的表。
- 所谓规则,在DBUS中,即**“规则算子”**。DBUS设计了丰富易用的过滤、拆分、合并、替换等算子供用户使用。用户对数据的处理可分多个步骤进行,每个步骤的数据处理结果可即时查看、验证;可重复使用不同算子,直到转换、裁剪得到自己需要的数据。
- 将配置好的规则算子组运用到执行引擎中,对目标日志数据进行预处理,形成结构化数据,输出到Kafka,供下游数据使用方使用。
系统流程图如下所示:
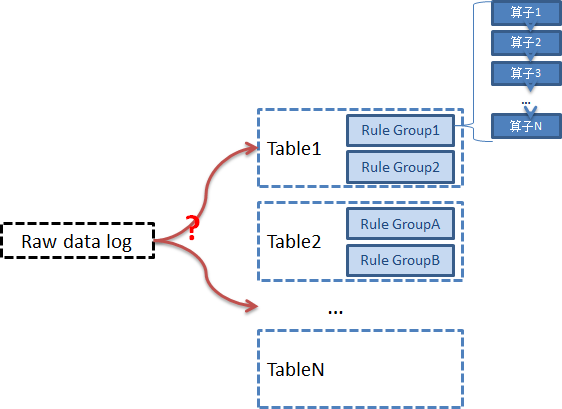
根据配置,我们支持同一条原始日志,能提取为一个表数据,或者可以提取为多个表数据。
每个表是结构化的,满足相同的schema。
- 每个表是一个规则 算子组的合集,可以配置1个到多个规则算子组
- 每个规则算子组,由一组规则算子组合而成
拿到一条原始数据日志, 它最终应该属于哪张表呢?
每条日志需要与规则算子组进行匹配:
- 符合条件的进入规则算子组的,最终被规则组转换为结构化的表数据。
- 不符合的尝试下一个规则算子组。
- 都不符合的,进入unknown_table表。
2.1 规则算子
规则算子是对数据进行过滤、加工、转换的基本单元。常见的规则算子如下:
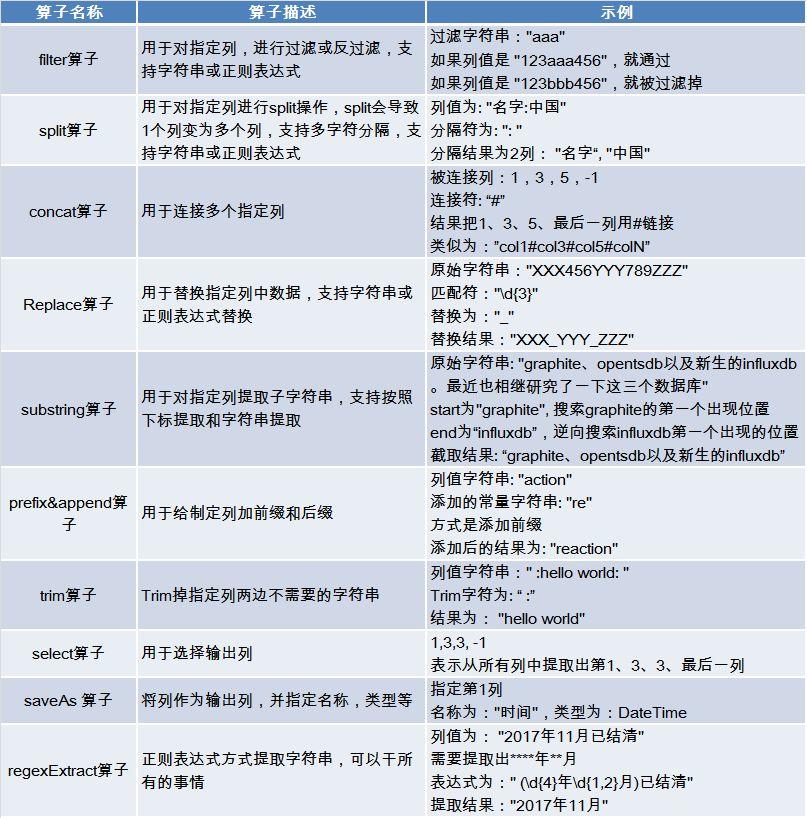
算子之间是独立的,通过组合不同的算子达到更复杂的功能,对算子进行迭代使用最终达到对任意数据进行加工的目的。
我们试图使得算子尽量满足正交性或易用性(虽然正则表达式很强大,但我们仍然开发一些简单算子例如trim算子来完成简单功能,以满足易用性)。
三、UMS统一消息格式
无论是增量、全量还是日志,最终输出到结果kafka中的消息都是我们约定的统一消息格式,称为UMS(unified message schema)格式。如下图所示:
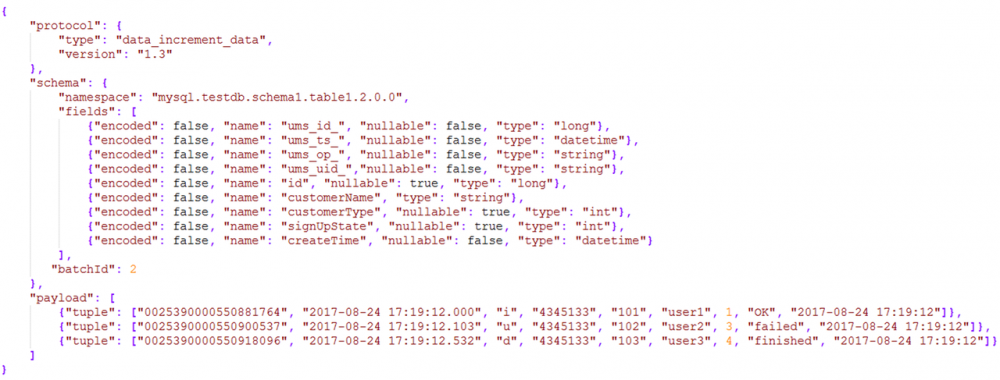
3.1 Protocol
数据的类型,被UMS的版本号
3.2 schema
1)namespace 由:类型. 数据源名.schema名 .表名.表版本号. 分库号 .分表号 组成,能够描述所有表。
例如:mysql.db1.schema1.testtable.5.0.0
2)fields是字段名描述。
- ums_id_ 消息的唯一id,保证消息是唯一的
- ums_ts_ canal捕获事件的时间戳;
- ums_op_ 表明数据的类型是I (insert),U (update),B (before Update),D(delete)
- ums_uid_ 数据流水号,唯一值
3)payload是指具体的数据。
一个json包里面可以包含1条至多条数据,提高数据的有效载荷。
四、心跳监控和预警
RDBMS类系统涉及到数据库的主备同步,日志抽取,增量转换等多个模块等。
日志类系统涉及到日志抽取端,日志转换模模块等。
如何知道系统正在健康工作,数据是否能够实时流转? 因此对流程的监控和预警就尤为重要。
4.1 对于RDBMS类系统
心跳模块从dbusmgr库中获得需要监控的表列表,以固定频率(比如每分钟)向源端dbus库的心跳表插入心跳数据(该数据中带有发送时间),该心跳表也作为增量数据被实时同步出来,并且与被同步表走相同的逻辑和线程(为了保证顺序性,当遇到多并发度时是sharding by table的,心跳数据与table数据走同样的bolt),这样当收到心跳数据时,即便没有任何增删改的数据,也能证明整条链路是通的。
增量转换模块和心跳模块在收到心跳包数据后,就会发送该数据到influxdb中作为监控数据,通过grafana进行展示。 心跳模块还会监控延时情况,根据延时情况给以报警。
4.2 对于日志类系统
从源端就会自动产生心跳包,类似RDBMS系统,将心跳包通过抽取模块,和算子转换模块同步到末端,由心跳模块负责监控和预警。
正文到此结束
- 本文标签: ACE 高可用 并发 https zookeeper GitHub 开源 删除 id stream git 阿里巴巴 大数据 开发 http Master Statement ip 压力 数据 json 统计 希望 索引 db 线程 UI App src MQ bus tab 数据库 系统架构 CTO lib IO sharding update Oracle 配置 schema ORM mongo mysql sqoop 时间 同步 message 一致性 部署 正则表达式 js sql 需求
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

