实战 | SRE案例分析—JVM非堆内存溢出

供稿 | eBay Infrastructure Engineering
翻译&编辑 | 顾欣怡
本文共3098字,预计阅读时间10分钟
更多干货请关注“eBay技术荟”公众号
导
读
大多数的 JVM内存溢出问题(OOM) 都发生在 堆(heap) 上,但这次的情况 略有不同 。 本文基于 SRE的具体案例 ,从症状入手; 通过分析 详细GC日志及应用程序日志 , 找出问题 区域及其发生原因; 从而修复区域 解决问题 。 望能给同业人员一定启发与借鉴。
JVM(Java virtual machine,即Java虚拟机)本身包含自动垃圾回收机制,所以开发人员不必担心内存对象的回收。但是可分配给JVM的内存又是有限的,所以有时候我们会看到一些 内存溢出(OOM)问题 。对于这类问题, 我们通常认为有 2种可能原因 :
1)JVM内存设置过小
2)应用程序内存泄漏
对于 前者 可以 调参修改 , 对于 后者 需要 找到泄漏根源, 在代码中修复 。这次我们将分享一个由于 非堆内存导致的内存泄漏问题。
一、症状
一开始我们注意到这个应用里面有几台服务器的 GC 开销(garbage collection overhead) (如图1) 和 CPU 使用率 开始告警, GC 开销升到了 60%~70% 的水平, 同时CPU使用率也升上去了,忙于做GC。很明显,这就是一个 JVM 内存问题 。
GC 开销:
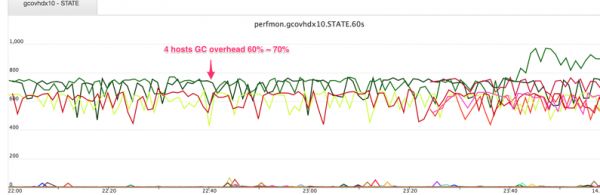
图1
二、处理
当时该应用上不是所有服务器都有这个问题, 只有一部分机器有。那就意味着内存被缓慢地占用, 并且不能被回收, 且到完全占满为止可能需要一定时间。 对于这类问题, 我们一般都是先下载详细的GC 日志, 获取 heap dump, 然后重启这些服务器,就能暂时解决问题。
三、分析
对于GC开销问题,我们一般是先分析详细的GC日志, 再分析heap dump, 最后分析源代码。
1
分析详细的GC日志
该应用默认是开启详细的GC日志的。其日志对于分析内存问题非常有帮助。如图2所示,JVM的年轻代和老年代都有大量内存可用, 可即使如此,该JVM却不断地做Full GC。
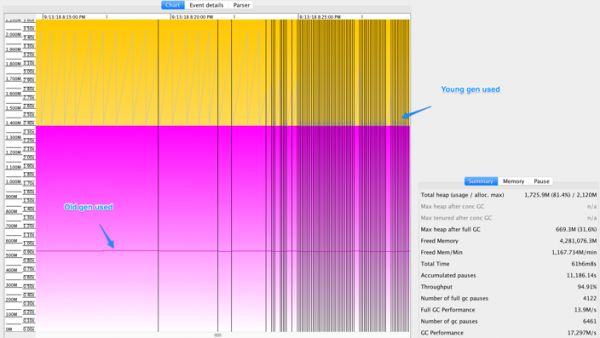
图2
这就有点奇怪了。因为 大多数情况下,GC 问题都是由于年轻代或者老年代内存吃紧, 导致JVM无法通过释放更多内存来分配新对象。 可是这个案例里面却有足够的内存可用 。 那么问题出在哪里呢?
我们知道 永久代(在Java 8中是元空间)内存不够用 也会导致不断Full GC; 在代码里面严格调用 System.gc() 或 Runtime.gc() 也会导致不断的Full GC, 下面让我们分析下是否是这两种情况:
(1)是不是由永久代内存不够用导致的,可以通过查看详细的GC日志里面的永久代使用情况判断。从下面的日志片段(如图3)中我们看到, 永久代还有很多可用内存, 所以不是这种情况。
(2) 那么是不是 System.gc() 或 Runtime. gc() 导致的呢? 对于某些JVM 实现, 如果是这类调用, 就会有 System 关键字。而这次 并没有发现这些关键字 。另外,这些服务器的代码、外部调用都没发生改变, 不大可能是走的新代码路径 。同时,对于应用里面的所有服务器来说, 其流量类型, 流量大小都是 基本等同 的, 所以也不可能部分机器走这些代码路径, 另外一些服务器走其它代码路径。
可见, 由于严格调用System.gc() 或 Runtime.gc()而引起Full GC的可能性也比较小。 退一步讲, 就算是这些严格调用引起Full GC, 也可以通过在JVM 启动时添加JVM -XX:+DisableExplicitGC 参数去对比和修复该问题。
因此,这两种可能性都被排除了。
详细的GC日志片段:

图3
以前我们也曾经遇到过类似症状的问题: Full GC 后年轻代和老年代都各有 700M 的空间剩余,老年代也没问题,却不断做Full GC。最终排查下来发现,有一个 java.util.Vector对象 , 它已经占用了 400M , 并仍在尝试扩展大小 。而根据代码所写,它每次扩展都要申请 2倍 的空间, 也就是 800M 来完成这次扩展。但是在它的 heap 中却拿不出 800M , 导致它一直请求Full GC。
但是这次,我们并未发现此类型的收集对象。
2
分析应用程序日志, 发现问题
在我们分析应用程序 heap dump的同时, 我们在 应用程序错误日志 中发现了 重要线索 。如图4所示,错误日志中输出: java.lang.OutOfMemoryError: Direct buffer memory。 这给我们的分析指明了方向。
日志中的内存溢出问题:
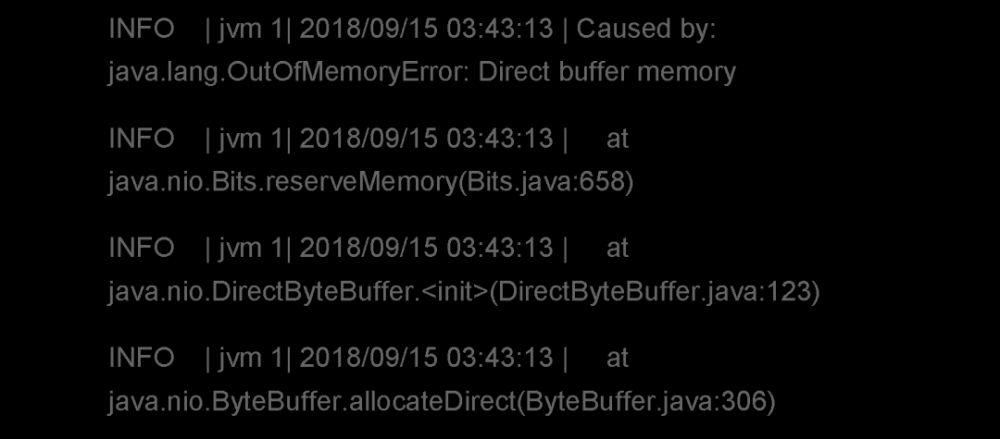
图4
这里的直接缓冲区内存(direct buffer memory)是指操作系统原生内存, 由Java进程使用, 但是不在 Java 的 heap 里面。Java 的NIO用它来加速性能, 因为它可以免去原生内存和 Java heap 之间的复制步骤。Java 应用程序可以通过设置参数: –XX:MaxDirectMemorySize 来设置可使用最大原生内存的大小。
如果没有设置这个参数, 持续申请直接缓冲区内存的Java进程就有可能耗尽所有的原生内存。我们这个案例中, 该应用设置的 最大可使用原生内存大小 是 1G 。 也就是说, 该应用程序已经把 1G 的原生内存耗尽, 之后便引起不断的Full GC 和 内存溢出。
3
在heap dump 中找到直接缓存区内存问题
尽管直接缓存区内存不在heap管理范围之内, 但是JVM还是在一定程度上管理它的使用和回收。每当JVM申请直接缓存区内存的时候,就会在heap创建一个java.nio.DirectBuffer对象来表示该内存。它包含这块内存的起始地址, 大小等元数据信息。由于这个java.nio.DirectBuffer在heap上由JVM来管理, 当没有对象引用它的时候, 它就会被回收。与此同时它表示的直接缓存区内存也将会被回收。
回到我们这个问题, 我们设置了 1G 的直接缓存区内存, 但是却被完全用完了。 那么是被谁用完的?为什么没有被回收?既然java.nio.DirectBuffer会保存相关的直接缓存区内存的元数据,我们能从heap dump中找到问题的根源吗?
从应用的错误日志中, 我们发现JVM尝试申请一个新的DirectByteBuffer实例,内存却不够了。 于是我们首先在heap dump中查看这种DirectByteBuffer的实例, 结果发现了大量的此类对象。
DirectByteBuffer是java.nio.DirectBuffer的一种实现子类,类似还有其它子类,如: DirectCharBuffers。 但是在heap dump 中,我们却没有发现任何其它子类类型。
我们可以通过下面的OQL去查询 有多少直接缓存区内存被DirectByteBuffer占用:

上面OQL中的capacity字段表示多少原生内存被这个实例对象占用。x.cleaner != null 这个条件用来过滤掉一些视图(view)形式的DirectByteBuffer。因为它们仅仅是从别的DirectByteBuffer申请的原生内存中划分一小块来用, 并没有真正申请原生内存, 所以可以 忽略 掉。同时在这个heap dump中有很多的DirectByteBuffer的实例, 他们申请的原生内存都 小于1M , 对于查这个问题帮助不大, 可以 忽略 。结果如图5:
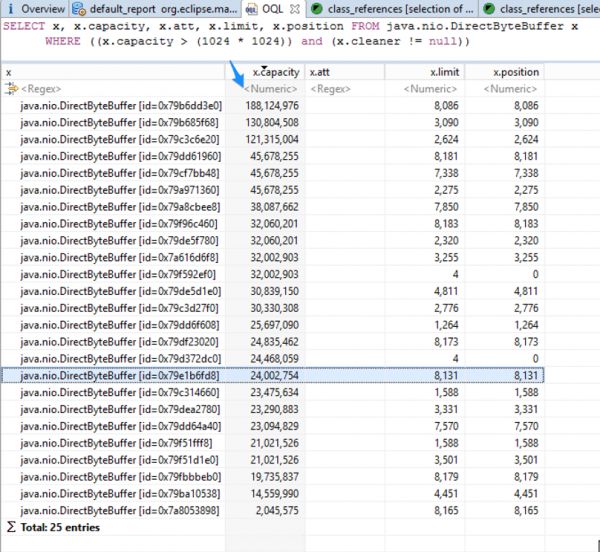
图5
从上面的结果中可以看到, 过滤后只剩下 25个 占用 大于1M 原生内存的实例对象。 最大的一个占用了 179M (188124977/1024/1024), 第二名占用 124M (130804508/1024/1024)。 如果把这 25个 实例占用的原生内存加总, 可以看到 几乎将近1G , 这也就是为什么我们设置的1G的直接缓存区内存都被用完的原因了。
4
为什么这些DirectByteBuffer未被GC回收?
如果这些 DirectByteBuffer 被GC回收, 那么与之关联的 直接缓存区内存 将被回收。这里的DirectByteBuffer一直被占用,所以与之关联的直接缓存区内存也被一直占用。
通过进一步对对象的引用链分析, 我们可以看到这些DirectByteBuffer对象都被一些 thread local BufferCaches 所引用。这些thread local BufferCaches都属于 Tomcat的守护(daemon)线程 。 由于这些线程一直存在, 并且这些BufferCaches没有剔除策略,所以它们将一直占用内存。 如图6所示:
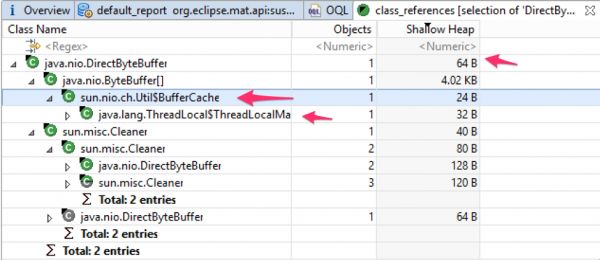
图6
那么又是谁把这些DirectByteBuffer放到thread local BufferCaches的, 为什么不清除呢?
顺着引用关系链, 我们找到了 JDK中的sun.nio.ch.Util.java类 。这个类里面包含一个thread local的BufferCache, 同时有个 getTemporaryDirectBuffer(int) 方法, 在这个方法中它会把DirectByteBuffer放到BufferCache中。
进一步分析, 我们可以看到同时有个getTemporaryDirectBuffer(int)方法被JDK NIO 里面的好几个类调用。 如果下次申请的原生内存大小不大于当前BufferCache里已有的大小, 那么当前BufferCache里的DirectByteBuffer将会被重用。 在某个线程存活期间, JDK NIO类将会一直使用当前线程里的BufferCache中的DirectByteBuffer。
其实该问题早已被认定为是一个 JDK问题 (JDK-8147468)。在JDK 8u102 更新版本说明中, 我们引入了一个新的系统属性: jdk.nio.maxCachedBufferSize 来修复问题;同时它还声明, 这个参数只能修复部分问题, 不能全部修复。
四、修复
大多数时候, 你的应用并不会遭遇这个问题, 原因有二:
1. 操作这些BufferCache的线程不是长时间运行的守护线程。 当这些线程结束的时候, 这些thread local对象将被回收, 与之关联的直接缓冲区内存也将被释放。
2. 即使某些长时间运行的守护线程频繁使用直接缓冲区内存, 但是由于每次 使用量都很小, 并且每次 都在重用范围之内 ,所以也不会出现这个问题。
在这个例子中,使用直接缓冲区内存的线程都是 长时间运行的守护线程 ,并且一直在处理上传文件。 有些文件非常大,甚至达到了 178M 的大小。 NIO在处理这些文件的时候,可能会申请相同大小的直接缓冲区内存。在本例中, 如果Tomcat开 40个 线程处理文件,由于处理大型文件比较缓慢,加上这 40个 线程可能 同时在处理大型上传文件, 那么JVM申请的 1G 直接缓存区内存就很有可能会被用完, 甚至还不够用。 最终 1G 原生内存被用光, 进而导致频繁Full GC和内存溢出。
为了在这个应用中解决该问题, 我们可以让NIO在处理文件上传的时候, 切割文件大小, 每次都处理较小的直接缓存区内存申请。 或者根据上传文件大小, 更改可以处理上传文件线程的多少, 使总的申请直接缓存区内存的大小受到限制。这样在应用处理层面就能解决该问题了。
五、总结
大多数时候,我们遇到的 内存溢出(OOM) 问题都发生在 Java heap 上, 但是有时候,也可能发生在 原生内存的直接缓存区内存 上。尽管直接缓存区内存不在堆内存里, 但还是可以通过 堆内存分析 去理解直接缓存区内存的问题。
↓点击 阅读原文 , 一键投递
eBay SRE(Software Engineer)优 质职位等你来!
我们的身边, 还缺一个你!
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

