你为什么可以持有数百万个goroutine却只能持有几千个Java线程?
很多使用基于jvm的语言的资深工程师都曾经见过下面这样的错误:
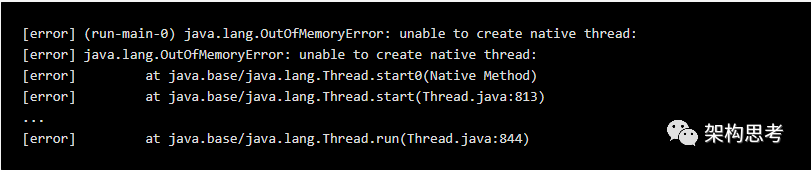
在我那台跑Linux系统的手提电脑上,才开11500个线程就会报这种错误。
如果你用go语言创建goroutine,结果会完全不同。在我的手提电脑上,可以创建7千万个goroutine。为什么goroutine数量比线程都这么多呢?这个答案需要深入到操作系统内部,很有意思。这不只是一个学术问题,它对你设计软件也有影响。我多次遇到过jvm线程数量的极限,要么是因为某些烂代码导致线程泄露,要么是因为工程师没意识到jvm的线程限制。
线程是什么?
“线程”这个术语有很多不同的含义。在本文中,我用这个词表示逻辑线程。也就是说:线性顺序执行的一系列指令;一个逻辑上的执行路径。在CPU上,一个核在一个时刻只能执行一个逻辑线程。【1】这种特性的副作用是如果你的线程数量比核数还多,线程必须被阻塞让其他线程工作,然后轮到这些线程时,再被唤醒。要支持阻塞和唤醒,线程最少需要两样东西:
一个程序计数器,指向当线程阻塞时线程正在执行的指令。
一个栈,用于保存当前状态。栈中保存着局部变量和指向堆(变量分配到堆中)的指针。同一个进程中的所有线程共享该堆。【2】
有了这两样东西,系统调度线程就有足够的信息去暂停一个线程,允许其他线程执行,然后在原来的线程暂停的地方恢复它。这个操作对线程来说是透明的。从线程的角度看,它是连续运行的。线程观察自己被取消调度的唯一办法是测量后续操作之间的时间。【3】
回到我们最初的问题上:你为什么能多出这么多goroutine?
jvm使用操作系统线程
虽然规范中没有要求,但是我所知道的所有现代通用的jvm都把线程委托给操作系统线程。接下来,我会使用“用户空间线程”表示由语言调度而非操作系统内核调度的线程。由操作系统实现的线程有两个属性极大地限制了可创建的线程数。将语言线程和操作系统线程作一比一映射的的方法中,没有一种可以支持大规模并发。
在jvm中:固定的栈大小
使用操作系统线程会导致每个线程消耗大量的内存
操作系统线程的第二个大问题的出现是因为每个os线程都有自己的固定大小的栈。虽然栈大小可以配置,但是在64位环境中,jvm默认为每个线程分配1MB的栈。你可以让默认的栈大小更小,但是需要权衡内存消耗和栈溢出的风险。你代码中的递归越多,栈溢出的可能性越高。如果你使用默认值,1k个线程将消耗约1GB的RAM!如今RAM很便宜,但是几乎没人会有太字节(1TB=1024G)级别的ram让你跑一百万个线程。
go是如果做的呢:动态大小的栈
golang避免大容量(大部分未被使用)的栈耗尽内存:go中的栈的容量是根据需要存储的数据量动态变化的。这不是件容易的事,设计经过了数次迭代。【4】尽管我不想在这里深入到其内部细节,但是结果是一个新建的goroutine的栈只有4KB。每个栈4KB,你可以在一个1GB的RAM上创建250万个goroutine--相对于Java的每个线程1MB是一个巨大的提升了。
在jvm中:上下文切换的延迟
如果使用操作系统线程,仅是因为上下文切换延迟,你就将被限制在100k个线程以内
因为jvm使用操作系统线程,它靠操作系统内核去调度。操作系统持有一张表记录着所有运行中的进程和线程,并尝试给它们一个“公平”的运行时间。【5】当内核从一个线程切换到另一个线程,有很多工作要做。新运行的进程或线程启动时,必须移除其他线程正在同一个CPU上运行这一事实。我不会深入到细节,但如果你很好奇,你可以阅读更多内容(https://en.wikipedia.org/wiki/Context_switch)。关键点是切换上下文需要1~100微秒。这看起来可能不多,但是以每次切换实际上会花10微秒来计算,如果你想在一秒内将每个线程调度至少一次,在一个核上你将只能运行100k个线程。并且线程没有时间做任何有用的工作。
go如何做呢:在一个操作系统线程上跑多个goroutine
golang实现了自己的调度器,该调度器允许多个goroutine在一个操作系统线程上跑。即使go像内核一样运行相同的上下文切换代码,它通过避免切换到ring-0(https://en.wikipedia.org/wiki/Protection_ring)去运行内核并返回来节省大量的时间。但是要真正地支持100万个goroutine,go要做的工作复杂得多。
即使jvm将线程引入到用户空间,它仍然不能支持数百万个线程。假设在你的新系统中,新线程间的切换只需要100纳秒。即使你只需要进行上下文切换,如果你想在一秒内调度每个线程十次,你只能运行大约一百万个线程。更重要的是,你将使CPU满负荷。真正支持大规模并发需要另一个优化:仅在你知道线程可以做有用的工作时调度它!如果你正在跑那么多线程,实际上只有少数在做有用的工作。go通过集成通道和调度器来实现这一点。如果一个goroutine正在一个空的通道上等待,调度器能看到并且不会运行这个goroutine。go更进一步,它将空闲goroutine粘在自己的操作系统线程上。这样,活跃线程(希望少得多)可以被一个线程调度。这有助于减小延迟。
除非Java增加语言特性,让调度器可以观察,否则支持智能调度是不可能的。然而,你可以在能感知线程何时可以干活的用户空间中构建运行时调度器。这构成了像Akka(支持百万级的actors)这样的框架的基础。【6】
结束语
从使用操作系统线程的模型到使用轻量级的用户空间线程的模型的转变已经一次又一次地发生,并且可能继续发生。【7】对于需要高并发性的用例,它是唯一的选择。但是这伴随着相当高的复杂性。如果go选择了操作系统线程而没有选择使用自己的调度器和可扩展栈的机制,它们可以删掉runtime包中的数千行代码。对于很多用例,它是一个更好的模型。复杂性可以通过语言和库移除,然后软件工程师就能写出高并发代码。
【1】超线程使有效核心加倍。指令流水线也会增加CPU允许的有效并行性。不管怎么说,它将是O(numCores)。
【2】可能在一些深奥的案例中不是这样。我确信会有人告诉我的。
【3】这实际上是一个攻击媒介。JavaScript能检测到由于键盘中断造成的时间上的细微差别。恶意网站可以使用它监听它们的时间。https://mlq.me/download/keystroke_js.pdf
【4】golang最初使用分段栈模型,该模型中栈实际上会扩展到内存中一块单独的区域,并使用簿记来跟踪这些内存。后来的实现使用连续栈(很像调整hash表大小)改进了特定情况下的性能。连续栈的做法是分配一个新的更大的栈,然后将所有的内容复制到新栈中。
【5】线程可以通过调用nice命令(详见man nice)获取更多信息来标记其优先级,从而控制被调度的频率。
【6】通过实现大规模并发,Actor为Scala/Java提供同样的功能。和goroutine一样,actor调度器可以看到哪些actor的邮箱中有消息,然后只运行那些已准备好做有用工作的actor。实际上,相比于你可以拥有的goroutine的数量,你可以持有更多的actor,因为actor不需要栈。然而,这意味着不能快速地处理消息,调度器将会阻塞(因为actor没有自己的栈,它不能在消息处理过程中暂停)。阻塞的调度器意味着没有消息被处理,那么系统将阻塞。权衡!
【7】在Apache中,每个请求由一个操作系统线程处理,这有效地将Apache限制在数千个并发连接。Nginx选择了一个模型,该模型中一个操作系统线程处理数百甚至数千个并发连接,这允许更高程度的并发。Erlang使用一个相似的模型,该模型允许数百万个actor并发执行。Gevent将greenlet(用户空间线程)引入python,实现了比其它方式支持的并发度更高程度的并发(Python线程是操作系统线程)。
初次翻译,请轻喷!
如果觉得别扭,请阅读原文:
https://rcoh.me/posts/why-you-can-have-a-million-go-routines-but-only-1000-java-threads/#fnref:switch?nsukey=m0OzpMaVYZzp7H5h37D2WV0MED1mBDaBmmkCqsEUEoVuwoUKT27h%2F1R3%2F8w1YIQA7pA28Tt0ErMsOyrBVkaFzSDVnGjV4nsIT8xENzYqTmRjnwJHOQXA9tM6xtj7BfgZ0qIN4UO4lrBPg2y9ukkHDDePS7HkicGvluDy7uU4iKXzJurzt2PBewcbIpPFOroOmXsLBSY1yAw9SQ8QRkEMVQ%3D%3D
欢迎关注博主个人微信公众号~~~

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

