Java开发最常犯的10个错误,打死都不要犯!
点击上方“ zhisheng ”,选择“ 设为星标 ”
做积极的人,而不是积极废人

原文: http://www.programcreek.com/2014/05/top-10-mistakes-java-developers-make/
译文: cnblogs.com/chenpi/p/5508949.html
阅读目录
-
Array转ArrayList
-
判断一个数组是否包含某个值
-
在循环内部删除List中的一个元素
-
HashTable与HashMap
-
使用集合原始类型(raw type)
-
访问级别
-
ArrayList和LinkedList
-
可变与不可变
-
父类和子类的构造方法
-
“”还是构造方法
-
未来工作
这个列表总结了10个Java开发人员最常犯的错误。
1、Array转ArrayList
当需要把Array转成ArrayList的时候,开发人员经常这样做:
List<String> list = Arrays.asList(arr);
Arrays.asList()会返回一个ArrayList,但是要特别注意,这个ArrayList是Arrays类的静态内部类,并不是java.util.ArrayList类。
java.util.Arrays.ArrayList类实现了set(), get(),contains()方法,但是并没有实现增加元素的方法(事实上是可以调用add方法,但是没有具体实现,仅仅抛出UnsupportedOperationException异常),因此它的大小也是固定不变的。为了创建一个真正的java.util.ArrayList,你应该这样做:
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(arr));
ArrayList的构造方法可以接收一个Collection类型,而java.util.Arrays.ArrayList已经实现了该接口。
2、判断一个数组是否包含某个值
开发人员经常这样做:
Set<String> set = new HashSet<String>(Arrays.asList(arr)); return set.contains(targetValue);
以上代码可以正常工作,但是没有必要将其转换成set集合,将一个List转成Set需要额外的时间,其实我们可以简单的使用如下方法即可:
Arrays.asList(arr).contains(targetValue);
或者
for(String s: arr){
if(s.equals(targetValue))
return true;
}
return false;
第一种方法可读性更强。
3、在循环内部删除List中的一个元素
考虑如下代码,在迭代期间删除元素:
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c","d"));
for (int i = 0; i < list.size(); i++) {
list.remove(i);
}
System.out.println(list);
结果打印:[b, d]
在上面这个方法中有一系列的问题,当一个元素被删除的时候,list大小减小,然后原先索引指向了其它元素。所以如果你想在循环里通过索引来删除多个元素,将不会正确工作。
你也许知道使用迭代器是在循环里删除元素的正确方式,或许你也知道foreach循环跟迭代器很类似,但事实情况却不是这样,如下代码:
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c","d"));
for (String s : list) {
if (s.equals("a"))
list.remove(s);
}
将抛出ConcurrentModificationException异常。
然而接下来的代码却是OK的:
ArrayList<String> list = new ArrayList<String>(Arrays.asList("a", "b", "c","d"));
Iterator<String> iter = list.iterator();
while (iter.hasNext()) {
String s = iter.next();
if (s.equals("a")) {
iter.remove();
}
}
next()方法需要在remove()方法之前被调用,在foreach循环里,编译器会在删除元素操作化调用next方法,这导致了ConcurrentModificationException异常。更多详细信息,可以查看ArrayList.iterator()的源码。
4、HashTable与HashMap
从算法的角度来讲,HashTable是一种数据结构名称。但是在Java中,这种数据结构叫做HashMap。
HashTable与HashMap的一个主要的区别是HashTable是同步的,所以,通常来说,你会使用HashMap,而不是Hashtable。
5、使用集合原始类型(raw type)
在Java中,原始类型(raw type)和无界通配符类型很容易让人混淆。举个Set的例子,Set是原始类型,而Set是无界通配符类型。
请看如下代码,add方法使用了一个原始类型的List作为入参:
public static void add(List list, Object o){
list.add(o);
}
public static void main(String[] args){
List<String> list = new ArrayList<String>();
add(list, 10);
String s = list.get(0);
}
运行以上代码将会抛出异常:
Exception in thread "main" java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String at …
使用原始类型集合非常危险,因为它跳过了泛型类型检查,是不安全的。另外,Set, Set, 和Set这三个有很大的不同。
6、访问级别
开发人员经常使用public修饰类字段,虽然这很容易让别人直接通过引用获取该字段的值,但这是一个不好的设计。根据经验,应该尽可能的降低成员属性的访问级别。
7、ArrayList和LinkedList
为什么开发人员经常使用ArrayList和LinkedList,却不知道他们之间的区别,因为它们看起来很像。然而它们之间有着巨大的性能差异。简单的说,如果有大量的增加删除操作并且没有很多的随机访问元素的操作,应该首选LinkedList。
8、可变与不可变
不可变对象有很多优点,如简单、安全等。但是对于每个不同的值都需要一个单独的对象,太多的对象会引起大量垃圾回收,因此在选择可变与不可变的时候,需要有一个平衡。
通常,可变对象用于避免产生大量的中间对象,一个经典的例子是大量字符串的拼接。如果你使用一个不可变对象,将会马上产生大量符合垃圾回收标准的对象,这浪费了CPU大量的时间和精力。使用可变对象是正确的解决方案(StringBuilder);
String result="";
for(String s: arr){
result = result + s;
}
另外,在有些其它情况下也是需要使用可变对象。例如往一个方法传入一个可变对象,然后收集多种结果,而不需要写太多的语法。另一个例子是排序和过滤:当然,你可以写一个方法来接收原始的集合,并且返回一个排好序的集合,但是那样对于大的集合就太浪费了。
9、父类和子类的构造方法
之所以出现这个编译错误,是因为父类的默认构造方法未定义。在Java中,如果一个类没有定义构造方法,编译器会默认插入一个无参数的构造方法;但是如果一个构造方法在父类中已定义,在这种情况,编译器是不会自动插入一个默认的无参构造方法,这正是以上demo的情况;
对于子类来说,不管是无参构造方法还是有参构造方法,都会默认调用父类的无参构造方法;当编译器尝试在子类中往这两个构造方法插入super()方法时,因为父类没有一个默认的无参构造方法,所以编译器报错;
要修复这个错误,很简单:
1、在父类手动定义一个无参构造方法:
public Super(){
System.out.println("Super");
}
2、移除父类中自定义的构造方法
3、在子类中自己写上父类构造方法的调用;如super(value);
10、“”还是构造方法
有两种创建字符串的方式:
//1. use double quotes
String x = "abc";
//2. use constructor
String y = new String("abc");
它们之间有什么区别呢?
以下代码提供了一个快速回答:
String a = "abcd";
String b = "abcd";
System.out.println(a == b); // True
System.out.println(a.equals(b)); // True
String c = new String("abcd");
String d = new String("abcd");
System.out.println(c == d); // False
System.out.println(c.equals(d)); // True
更多关于它们内存分配的信息,请参考Create Java String Using ” ” or Constructor??
未来工作
这个列表是我基于大量的github上的开源项目,Stack overflow上的问题,还有一些流行的google搜索的分析。没有明显示的评估证明它们是前10,但它们绝对是很常见的。
如果您不同意任一部分,请留下您的评论。如果您能提出其它一些常见的错误,我将会非常感激。
关注我

公众号 ( zhisheng ) 里回复 面经、 ES、 Flink、 Spring、 Java、 Kafka、 监控 等关键字 可以查看更多关键字对应的文章
Flink 实战
1、《从0到1学习Flink》—— Apache Flink 介绍
2、《从0到1学习Flink》—— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、《从0到1学习Flink》—— Flink 配置文件详解
4、《从0到1学习Flink》—— Data Source 介绍
5、《从0到1学习Flink》—— 如何自定义 Data Source ?
6、《从0到1学习Flink》—— Data Sink 介绍
7、《从0到1学习Flink》—— 如何自定义 Data Sink ?
8、《从0到1学习Flink》—— Flink Data transformation(转换)
9、《从0到1学习Flink》—— 介绍 Flink 中的 Stream Windows
10、《从0到1学习Flink》—— Flink 中的几种 Time 详解
11、《从0到1学习Flink》—— Flink 读取 Kafka 数据写入到 ElasticSearch
12、《从0到1学习Flink》—— Flink 项目如何运行?
13、《从0到1学习Flink》—— Flink 读取 Kafka 数据写入到 Kafka
14、《从0到1学习Flink》—— Flink JobManager 高可用性配置
15、《从0到1学习Flink》—— Flink parallelism 和 Slot 介绍
16、《从0到1学习Flink》—— Flink 读取 Kafka 数据批量写入到 MySQL
17、《从0到1学习Flink》—— Flink 读取 Kafka 数据写入到 RabbitMQ
18、《从0到1学习Flink》—— 你上传的 jar 包藏到哪里去了
19、大数据“重磅炸弹”——实时计算框架 Flink
20、 《Flink 源码解析》—— 源码编译运行
21、 为什么说流处理即未来?
22、 OPPO数据中台之基石:基于Flink SQL构建实数据仓库
23、 流计算框架 Flink 与 Storm 的性能对比
24、 Flink状态管理和容错机制介绍
25、 原理解析 | Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
26、 Apache Flink 是如何管理好内存的?
27、 《 从0到1学习Flink》—— Flink 中这样管理配置,你知道?
28、 《 从0到1学习Flink》—— Flink 不可以连续 Split(分流)?
29、 Flink 从0到1学习—— 分享四本 Flink 的书和二十多篇 Paper 论文
30、 360深度实践:Flink与Storm协议级对比
31、 Apache Flink 1.9 重大特性提前解读
Flink 源码解析
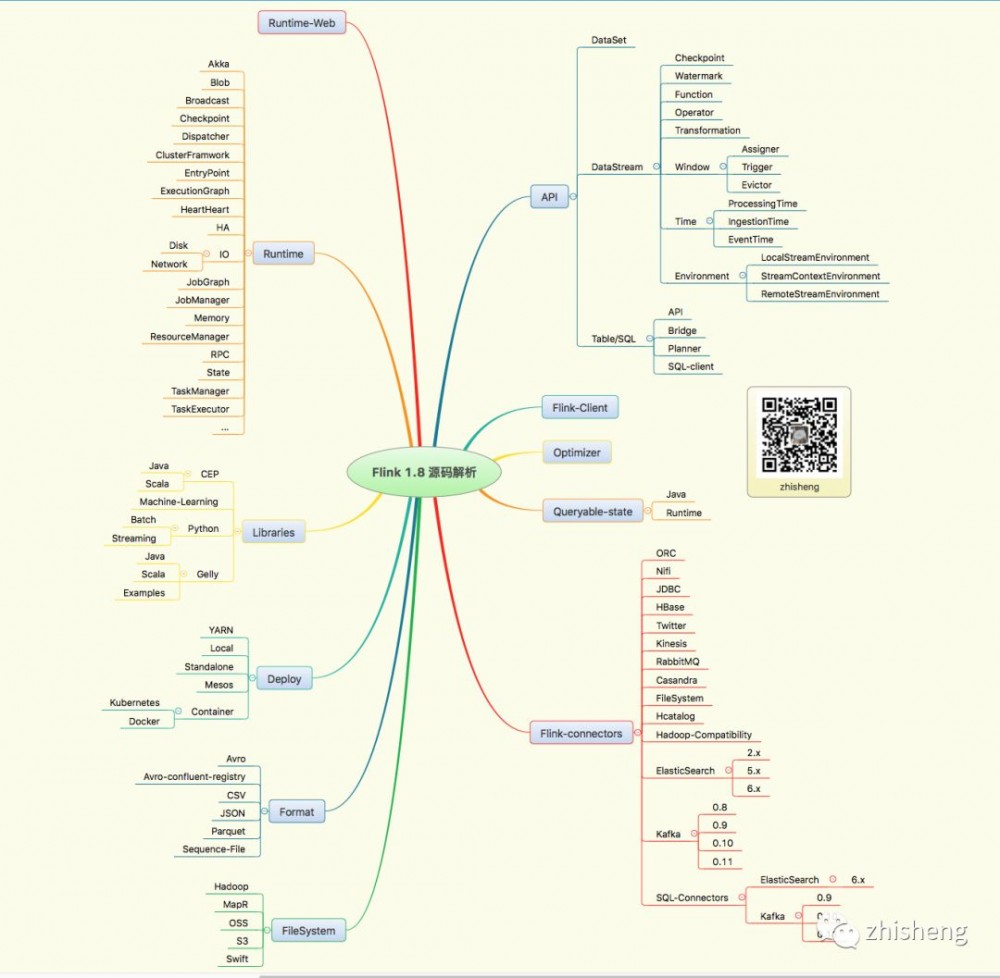

Flink 源码解析
知识星球里面可以看到下面文章
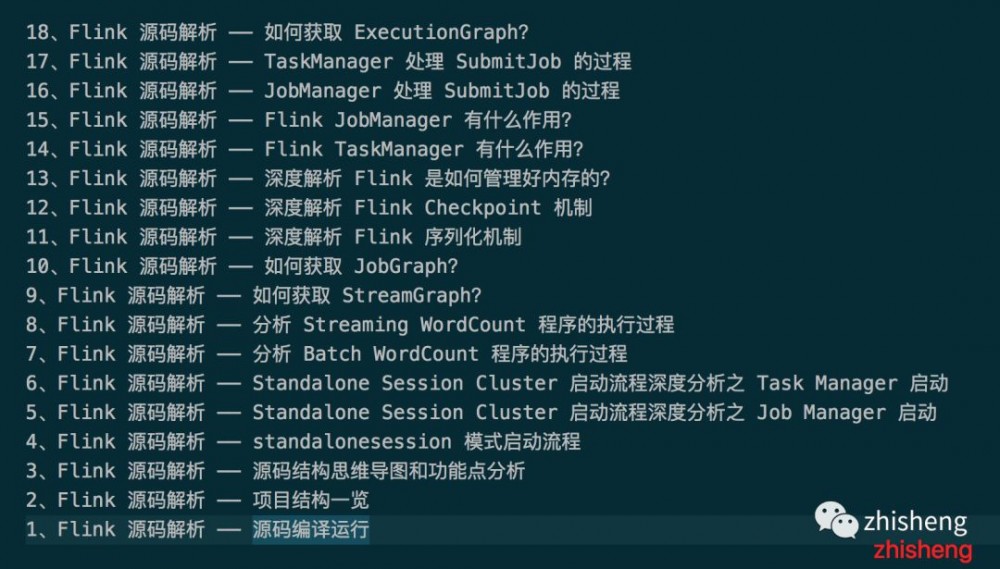
正文到此结束
- 本文标签: tab 安全 管理 value build Collection HashMap HashSet mysql 源码 cat 大数据 解析 Developer IO 回答 stream 协议 tar 开源项目 HTML 同步 ORM Elasticsearch 构造方法 编译 数据 CTO 开源 Job rabbitmq equals apache https UI 时间 总结 文章 高可用 ArrayList java git 配置 代码 开发 删除 id LinkedList spring struct map GitHub 参数 http MQ 索引 windows sql Google list src 垃圾回收 HashTable 目录
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

