Java并发编程:线程及同步的性能——线程池

线程池和ThreadPoolExecutors
虽然在程序中可以直接使用Thread类型来进行线程操作,但是更多的情况是使用线程池,尤其是在Java EE应用服务器中,一般会使用若干个线程池来处理来自客户端的请求。Java中对于线程池的支持,来自ThreadPoolExecutor。一些应用服务器也确实是使用的ThreadPoolExecutor来实现线程池。
对于线程池的性能调优,最重要的参数就是线程池的大小。
对于任何线程池而言,它们的工作方式几乎都是相同的:
- 任务被投放到一个队列中(队列的数量不定)
- 线程从队列中取得任务并执行
- 线程完成任务后,继续尝试从队列中取得任务,如果队列为空,那么线程进入等待状态
线程池往往拥有最小和最大线程数:
- 最小线程数,即当任务队列为空时,线程池中最少需要保持的线程数量,这样做是考虑到创建线程是一个相对耗费资源的操作,应当尽可能地避免,当有新任务被投入队列时,总会有线程能够立即对它进行处理。
- 最大线程数,当需要处理的任务过多时,线程池能够拥有的最大线程数。这样是为了保证不会有过多的线程被创建出来,因为线程的运行需要依赖于CPU资源和其它各种资源,当线程过多时,反而会降低性能。
在ThreadPoolExecutor和其相关的类型中,最小线程数被称为线程池核心规模(Core Pool Size),在其它Java应用服务器的实现中,这个数量也许被称为最小线程数(MinThreads),但是它们的概念是相同的。
但是在对线程池进行规模变更(Resizing)的时候,ThreadPoolExecutor和其它线程池的实现也许存在的很大的差别。
一个最简单的情况是:当有新任务需要被执行,且当前所有的线程都被占用时,ThreadPoolExecutor和其它实现通常都会新创建一个线程来执行这个新任务(直到达到了最大线程数)。
设置最大线程数
最合适的最大线程数该怎么确定,依赖以下两个方面:
- 任务的特征
- 计算机的硬件情况
为了方便讨论,下面假设JVM有4个可用的CPU。那么任务也很明确,就是要最大程度地“压榨”它们的资源,千方百计的提高CPU的利用率。
那么,最大线程数最少需要被设置成4,因为有4个可用的CPU,意味着最多能够并行地执行4个任务。当然,垃圾回收(Garbage Collection)在这个过程中也会造成一些影响,但是它们往往不需要使用整个CPU。一个例外是,当使用了CMS或者G1垃圾回收算法时,需要有足够的CPU资源进行垃圾回收。
那么是否有必要将线程数量设置的更大呢?这就取决于任务的特征了。
假设当任务是计算密集型的,意味着任务不需要执行IO操作,例如读取数据库,读取文件等,因此它们不涉及到同步的问题,任务之间完全是独立的。比如使用一个批处理程序读取Mock数据源的数据,测试在不线程池拥有不同线程数量时的性能,得到下表:
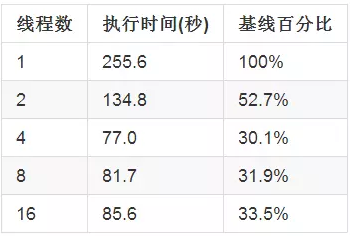
从上面中得到一些结论:
- 当线程数为4时,达到最优性能,再增加线程数量时并没有更好的性能,因为此时CPU的利用率已经达到了最高,在增加线程只会增加线程之间争夺CPU资源的行为,因此反而降低了性能。
- 即使在CPU利用率达到最高时,基线百分比也不是理想中的25%,这是因为虽然在程序运行过程中,CPU资源并不是只被应用程序线程独享的,一些后台线程有时也会需要CPU资源,比如GC线程和系统的一些线程等。
当计算是通过Servlet触发的时候,性能数据是下面这个样子的(Load Generator会同时发送20个请求):
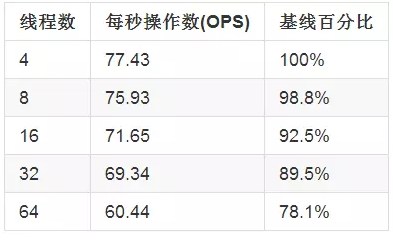
从上表中可以得到的结论:
- 在线程数量为4时,性能最优。因为此任务的类型是计算密集型的,只有4个CPU,因此线程数量为4时,达到最优情况。
- 随着线程数量逐渐增加,性能下降,因为线程之间会互相争夺CPU资源,造成频繁切换线程执行上下文环境,而这些切换只会浪费CPU资源。
- 性能下降的速度并不明显,这也是因为任务类型是计算密集型的缘故,如果性能瓶颈不是CPU提供的计算资源,而是外部的资源,如数据库,文件操作等,那么增加线程数量带来的性能下降也许会更加明显。
下面,从Client的角度考虑一下问题,并发Client的数量对于Server的响应时间会有什么影响呢?还是同样地环境,当并发Client数量逐渐增加时,响应时间会如下发生变化:
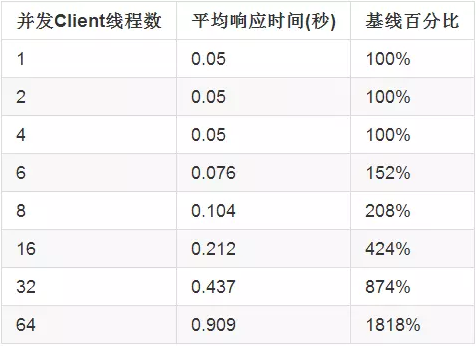
因为任务类型是计算密集型的,当并发Client数量时1,2,4时,平均响应时间都是最优的,然而当出现多余4个Client时,性能会随着Client的增加发生显著地下降。
当Client数量增加时,你也许会想通过增加服务端线程池的线程数量来提高性能,可是在CPU密集型任务的情况下,这么做只会降低性能。因为系统的瓶颈就是CPU资源,冒然增加线程池的线程数量只会让对于这种资源的竞争更加激烈。
所以,在面对性能方面的问题时。第一步永远是了解系统的瓶颈在哪里,这样才能够有的放矢。如果冒然进行所谓的“调优”,让对瓶颈资源的竞争更加激烈,那么带来的只会是性能的进一步下降。相反,如果让对瓶颈资源的竞争变的缓和,那么性能通常则会提高。
在上面的场景中,如果从ThreadPoolExecutor的角度进行考虑,那么在任务队列中一直会有任务处于挂起(Pending)的状态(因为Client的每个请求对应的就是一个任务),而所有的可用线程都在工作,CPU正在满负荷运转。这个时候添加线程池的线程数量,让这些添加的线程领取一些挂起的任务,会发生什么事情呢?这时带来的只会是线程之间对于CPU资源的争夺更加激烈,降低了性能。
设置最小线程数
设置了最大线程数之后,还需要设置最小线程数。对于绝大部分场景,将它设置的和最大线程数相等就可以了。
将最小线程数设置的小于最大线程数的初衷是为了节省资源,因为每多创建一个线程都会耗费一定量的资源,尤其是线程栈所需要的资源。但是在一个系统中,针对硬件资源以及任务特点选定了最大线程数之后,就表示这个系统总是会利用这些线程的,那么还不如在一开始就让线程池把需要的线程准备好。然而,把最小线程数设置的小于最大线程数所带来的影响也是非常小的,一般都不会察觉到有什么不同。
在批处理程序中,最小线程数是否等于最大线程数并不重要。因为最后线程总是需要被创建出来的,所以程序的运行时间应该几乎相同。对于服务器程序而言,影响也不大,但是一般而言,线程池中的线程在“热身”阶段就应该被创建出来,所以这也是为什么建议将最小线程数设置的等于最大线程数的原因。
在一些场景中,也需要要设置一个不同的最小线程数。比如当一个系统最大需要同时处理2000个任务,而平均任务数量只是20个情况下,就需要将最小线程数设置成20,而不是等于其最大线程数2000。此时如果还是将最小线程数设置的等于最大线程数的话,那么闲置线程(Idle Thread)占用的资源就比较可观了,尤其是当使用了ThreadLocal类型的变量时。
线程池任务数量(Thread Pool Task Sizes)
线程池有一个列表或者队列的数据结构来存放需要被执行的任务。显然,在某些情况下,任务数量的增长速度会大于其被执行的速度。如果这个任务代表的是一个来自Client的请求,那么也就意味着该Client会等待比较长的时间。显然这是不可接受的,尤其对于提供Web服务的服务器程序而言。
所以,线程池会有机制来限制列表/队列中任务的数量。但是,和设置最大线程数一样,并没有一个放之四海而皆准的最优任务数量。这还是要取决于具体的任务类型和不断的进行性能测试。
对于ThreadPoolExecutor而言,当任务数量达到最大时,再尝试增加新的任务就会失败。ThreadPoolExecutor有一个rejectedExecution方法用来拒绝该任务。这会导致应用服务器返回一个HTTP状态码500,当然这种信息最好以更友好的方式传达给Client,比如解释一下为什么你的请求被拒绝了。
定制ThreadPoolExecutor
线程池在同时满足以下三个条件时,就会创建一个新的线程:
- 有任务需要被执行
- 当前线程池中所有的线程都处于工作状态
- 当前线程池的线程数没有达到最大线程数
至于线程池会如何创建这个新的线程,则是根据任务队列的种类:
- 任务队列是 SynchronousQueue 这个队列的特点是,它并不能放置任何任务在其队列中,当有任务被提交时,使用SynchronousQueue的线程池会立即为该任务创建一个线程(如果线程数量没有达到最大时,如果达到了最大,那么该任务会被拒绝)。这种队列适合于当任务数量较小时采用。也就是说,在使用这种队列时,未被执行的任务没有一个容器来暂时储存。
- 任务队列是 无限队列(Unbound Queue) 无界限的队列可以是诸如LinkedBlockingQueue这种类型,在这种情况下,任何被提交的任务都不会被拒绝。但是线程池会忽略最大线程数这一参数,意味着线程池的最大线程数就变成了设置的最小线程数。所以在使用这种队列时,通常会将最大线程数设置的和最小线程数相等。这就相当于使用了一个固定了线程数量的线程池。
- 任务队列是 有限队列(Bounded Queue) 当使用的队列是诸如ArrayBlockingQueue这种有限队列的时候,来决定什么时候创建新线程的算法就相对复杂一些了。比如,最小线程数是4,最大线程数是8,任务队列最多能够容纳10个任务。在这种情况下,当任务逐渐被添加到队列中,直到队列被占满(10个任务),此时线程池中的工作线程仍然只有4个,即最小线程数。只有当仍然有任务希望被放置到队列中的时候,线程池才会新创建一个线程并从队列头部拿走一个任务,以腾出位置来容纳这个最新被提交的任务。
关于如何定制ThreadPoolExecutor,遵循KISS原则(Keep It Simple, Stupid)就好了。比如将最大线程数和最小线程数设置的相等,然后根据情况选择有限队列或者无限队列。
总结
- 线程池是对象池的一个有用的例子,它能够节省在创建它们时候的资源开销。并且线程池对系统中的线程数量也起到了很好的限制作用。
- 线程池中的线程数量必须仔细的设置,否则冒然增加线程数量只会带来性能的下降。
- 在定制ThreadPoolExecutor时,遵循KISS原则,通常情况下会提供最好的性能。
ForkJoinPool
在Java 7中引入了一种新的线程池:ForkJoinPool。
它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。
那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
比如,我们需要统计一个double数组中小于0.5的元素的个数,那么可以使用ForkJoinPool进行实现如下:
public class ForkJoinTest {
private double[] d;
private class ForkJoinTask extends RecursiveTask<Integer> {
private int first;
private int last;
public ForkJoinTask(int first, int last) {
this.first = first;
this.last = last;
}
protected Integer compute() {
int subCount;
if (last - first < 10) {
subCount = 0;
for (int i = first; i <= last; i++) {
if (d[i] < 0.5)
subCount++;
}
} else {
int mid = (first + last) >>> 1;
ForkJoinTask left = new ForkJoinTask(first, mid);
left.fork();
ForkJoinTask right = new ForkJoinTask(mid + 1, last);
right.fork();
subCount = left.join();
subCount += right.join();
}
return subCount;
}
}
public static void main(String[] args) {
d = createArrayOfRandomDoubles();
int n = new ForkJoinPool().invoke(new ForkJoinTask(0, 9999999));
System.out.println("Found " + n + " values");
}
}
以上的关键是fork()和join()方法。在ForkJoinPool使用的线程中,会使用一个内部队列来对需要执行的任务以及子任务进行操作来保证它们的执行顺序。
那么使用ThreadPoolExecutor或者ForkJoinPool,会有什么性能的差异呢?
首先,使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
当然,在上面的例子中,也可以不使用分治法,因为任务之间的独立性,可以将整个数组划分为几个区域,然后使用ThreadPoolExecutor来解决,这种办法不会创建数量庞大的子任务。代码如下:
public class ThreadPoolTest {
private double[] d;
private class ThreadPoolExecutorTask implements Callable<Integer> {
private int first;
private int last;
public ThreadPoolExecutorTask(int first, int last) {
this.first = first;
this.last = last;
}
public Integer call() {
int subCount = 0;
for (int i = first; i <= last; i++) {
if (d[i] < 0.5) {
subCount++;
}
}
return subCount;
}
}
public static void main(String[] args) {
d = createArrayOfRandomDoubles();
ThreadPoolExecutor tpe = new ThreadPoolExecutor
(4, 4, long.MAX_VALUE, TimeUnit.SECONDS, new LinkedBlockingQueue());
Future[] f = new Future[4];
int size = d.length / 4;
for (int i = 0; i < 3; i++) {
f[i] = tpe.submit(new ThreadPoolExecutorTask(i * size, (i + 1) * size - 1);
}
f[3] = tpe.submit(new ThreadPoolExecutorTask(3 * size, d.length - 1);
int n = 0;
for (int i = 0; i < 4; i++) {
n += f.get();
}
System.out.println("Found " + n + " values");
}
}
在分别使用ForkJoinPool和ThreadPoolExecutor时,它们处理这个问题的时间如下:
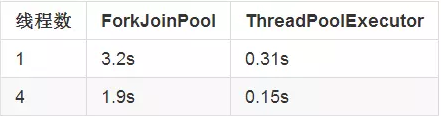
对执行过程中的GC同样也进行了监控,发现在使用ForkJoinPool时,总的GC时间花去了1.2s,而ThreadPoolExecutor并没有触发任何的GC操作。这是因为在ForkJoinPool的运行过程中,会创建大量的子任务。而当他们执行完毕之后,会被垃圾回收。反之,ThreadPoolExecutor则不会创建任何的子任务,因此不会导致任何的GC操作。
ForkJoinPool的另外一个特性是它能够实现工作窃取(Work Stealing),在该线程池的每个线程中会维护一个队列来存放需要被执行的任务。当线程自身队列中的任务都执行完毕后,它会从别的线程中拿到未被执行的任务并帮助它执行。
可以通过以下的代码来测试ForkJoinPool的Work Stealing特性:
for (int i = first; i <= last; i++) {
if (d[i] < 0.5) {
subCount++;
}
for (int j = 0; j < d.length - i; j++) {
for (int k = 0; k < 100; k++) {
dummy = j * k + i;
// dummy is volatile, so multiple writes occur
d[i] = dummy;
}
}
}
因为里层的循环次数(j)是依赖于外层的i的值的,所以这段代码的执行时间依赖于i的值。当i = 0时,执行时间最长,而i = last时执行时间最短。也就意味着任务的工作量是不一样的,当i的值较小时,任务的工作量大,随着i逐渐增加,任务的工作量变小。因此这是一个典型的任务负载不均衡的场景。
这时,选择ThreadPoolExecutor就不合适了,因为它其中的线程并不会关注每个任务之间任务量的差异。当执行任务量最小的任务的线程执行完毕后,它就会处于空闲的状态(Idle),等待任务量最大的任务执行完毕。
而ForkJoinPool的情况就不同了,即使任务的工作量有差别,当某个线程在执行工作量大的任务时,其他的空闲线程会帮助它完成剩下的任务。因此,提高了线程的利用率,从而提高了整体性能。
这两种线程池对于任务工作量不均衡时的执行时间:
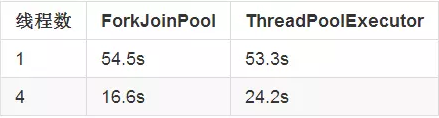
注意到当线程数量为1时,两者的执行时间差异并不明显。这是因为总的计算量是相同的,而ForkJoinPool慢的那一秒多是因为它创建了非常多的任务,同时也导致了GC的工作量增加。
当线程数量增加到4时,执行时间的区别就较大了,ForkJoinPool的性能比ThreadPoolExecutor好将近50%,可见Work Stealing在应对任务量不均衡的情况下,能够保证资源的利用率。
所以一个结论就是:当任务的任务量均衡时,选择ThreadPoolExecutor往往更好,反之则选择ForkJoinPool。
另外,对于ForkJoinPool,还有一个因素会影响它的性能,就是停止进行任务分割的那个阈值。比如在之前的快速排序中,当剩下的元素数量小于10的时候,就会停止子任务的创建。下表显示了在不同阈值下,ForkJoinPool的性能:
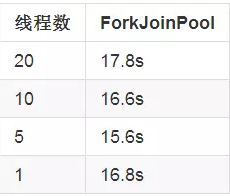
可以发现,当阈值不同时,对于性能也会有一定影响。因此,在使用ForkJoinPool时,对此阈值进行测试,使用一个最合适的值也有助于整体性能。
自动并行化(Automatic Parallelization)
在Java 8中,引入了自动并行化的概念。它能够让一部分Java代码自动地以并行的方式执行,前提是使用了ForkJoinPool。
Java 8为ForkJoinPool添加了一个通用线程池,这个线程池用来处理那些没有被显式提交到任何线程池的任务。它是ForkJoinPool类型上的一个静态元素,它拥有的默认线程数量等于运行计算机上的处理器数量。
当调用Arrays类上添加的新方法时,自动并行化就会发生。比如用来排序一个数组的并行快速排序,用来对一个数组中的元素进行并行遍历。自动并行化也被运用在Java 8新添加的Stream API中。
比如下面的代码用来遍历列表中的元素并执行需要的计算:
Stream<Integer> stream = arrayList.parallelStream();
stream.forEach(a -> {
String symbol = StockPriceUtils.makeSymbol(a);
StockPriceHistory sph = new StockPriceHistoryImpl(symbol, startDate, endDate, entityManager);
}
);
对于列表中的元素的计算都会以并行的方式执行。forEach方法会为每个元素的计算操作创建一个任务,该任务会被前文中提到的ForkJoinPool中的通用线程池处理。以上的并行计算逻辑当然也可以使用ThreadPoolExecutor完成,但是就代码的可读性和代码量而言,使用ForkJoinPool明显更胜一筹。
对于ForkJoinPool通用线程池的线程数量,通常使用默认值就可以了,即运行时计算机的处理器数量。如果需要调整线程数量,可以通过设置系统属性:-Djava.util.concurrent.ForkJoinPool.common.parallelism=N
下面的一组数据用来比较使用ThreadPoolExecutor和ForkJoinPool中的通用线程池来完成上面简单计算时的性能:
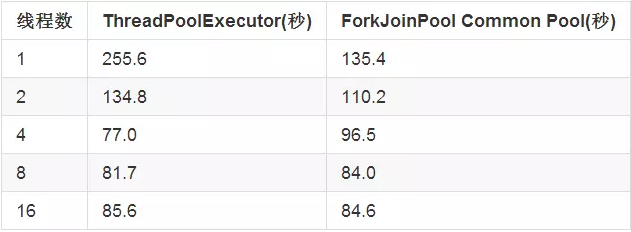
注意到当线程数为1,2,4时,性能差异的比较明显。线程数为1的ForkJoinPool通用线程池和线程数为2的ThreadPoolExecutor的性能十分接近。
出现这种现象的原因是,forEach方法用了一些小把戏。它会将执行forEach本身的线程也作为线程池中的一个工作线程。因此,即使将ForkJoinPool的通用线程池的线程数量设置为1,实际上也会有2个工作线程。因此在使用forEach的时候,线程数为1的ForkJoinPool通用线程池和线程数为2的ThreadPoolExecutor是等价的。
所以当ForkJoinPool通用线程池实际需要4个工作线程时,可以将它设置成3,那么在运行时可用的工作线程就是4了。
总结
- 当需要处理递归分治算法时,考虑使用ForkJoinPool。
- 仔细设置不再进行任务划分的阈值,这个阈值对性能有影响。
- Java 8中的一些特性会使用到ForkJoinPool中的通用线程池。在某些场合下,需要调整该线程池的默认的线程数量。
————END————
- 点赞
- ...
- 转发
- ...
- 关注
- ...
最后,欢迎做Java的工程师朋友们加入Java高级架构进阶Qqun:963944895
群内有技术大咖指点难题,还提供免费的Java架构学习资料(里面有高可用、高并发、高性能及分布式、Jvm性能调优、Spring源码,MyBatis,Netty,Redis,Kafka,Mysql,Zookeeper,Tomcat,Docker,Dubbo,Nginx等多个知识点的架构资料)
比你优秀的对手在学习,你的仇人在磨刀,你的闺蜜在减肥,隔壁老王在练腰, 我们必须不断学习,否则我们将被学习者超越!
趁年轻,使劲拼,给未来的自己一个交代!
正文到此结束
- 本文标签: ask Service id stream 测试 tar redis Docker dubbo 统计 处理器 服务端 JVM 定制 数据 DOM 总结 core queue 希望 ArrayList 服务器 https UI 遍历 volatile entity 线程池 MQ Thread pool Nginx ip sql 时间 并发编程 src JAVA架构 垃圾回收 工程师 web tomcat zookeeper 代码 参数 client 免费 Collection 高可用 rand java servlet cat Netty mybatis ThreadPoolExecutor 朋友们 IO 高并发 递归 spring db 线程 API list 同步 http executor 分布式 并发 mysql 源码 数据库 IDE value
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

