高可用架构实例:在多云和多区域中穿行
Auth0为所有技术栈上的任一平台(移动,Web,本机)应用程序提供身份验证,授权和单点登录服务。 身份验证对绝大多数应用程序至关重要。 我们从一开始就设计了Auth0,以便它可以在任何地方运行: 在我们的云上,在您的云上,甚至在您自己的私有基础架构上。
在这篇文章中,我们将更多地讨论我们的公共SaaS部署,并简要介绍auth0.com背后的基础架构以及我们用于保持高可用性并保持运行的策略。
从那以后在Auth0中发生了很多变化。这些是一些亮点:
-
我们从每月处理数百万次到 每月15亿次 登录,为数千名客户提供服务,包括FuboTV,Mozilla,JetPrivilege等。
-
我们实施了新功能,如自定义域,扩展的bcrypt操作,大大改进的用户搜索等等。
-
为了扩展我们的组织和处理日益增长,服务数量由原有的10个增加到30个。
-
云资源的数量也大幅增长; 我们曾经在一个环境(美国)中拥有几十个节点,现在我们在四个环境(美国,美国-2,欧盟,澳大利亚) 上拥有超过一千个节点。
-
我们决定为每个环境使用单一云提供商,并将所有公共云基础架构迁移到AWS。
核心服务架构
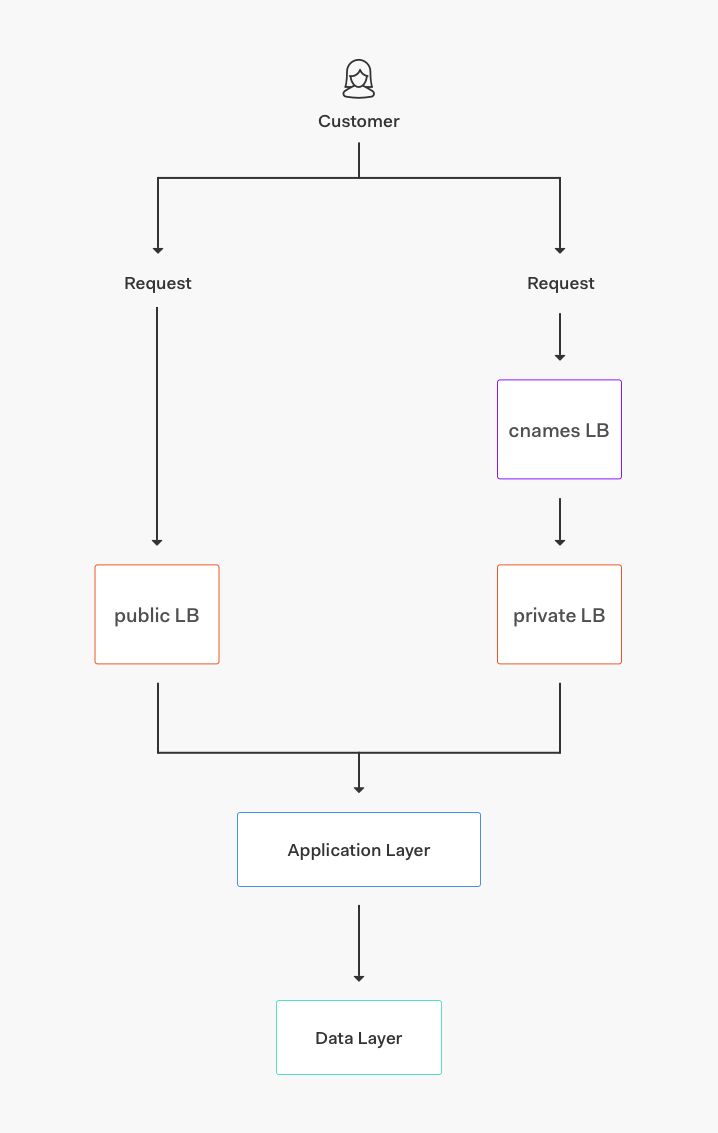
核心服务由不同的层组成:
核心应用层:自动扩展运行不同服务的服务器组(身份验证,管理API,多因素身份验证API等等)。
数据存储层:MongoDB,Elasticsearch,Redis和PostgreSQL的集群,为不同的应用程序和功能存储各种数据集。
传输/队列层:Kinesis流和RabbitMQ,SNS和SQS队列。
基本服务层:速率限制,bcrypt集群,功能标志等服务。
路由层: AWS负载均衡器(来自AWS的ALB,NLB和ELB)以及一些运行NGINX作为代理的节点。
高可用
2014年,我们使用了多云架构(使用Azure和AWS,在Google云上使用了一些额外的资源),并且多年来为我们提供了很好的服务。随着我们的使用(和负载)迅速增加,我们发现自己越来越依赖AWS资源。
首先,我们将我们环境中的主要区域切换到AWS,将Azure保留为灾备。当我们开始使用更多AWS资源(如Kinesis和SQS)时,我们开始难以在两个提供程序中保留相同的功能集。 随着我们的需求的日益增长,我们会继续在Azure部署一些新功能。如果部署在AWS上的服务全部不可用,我们仍然可以使用Azure群集支持核心身份验证功能。
(编者: 多云环境保持同步增加功能,复杂度问题)
在2016年发生一些故障后,我们决定最终融入AWS。我们停止了与保持服务和自动化平台无关的所有工作,并聚焦于以下内容:
-
在AWS内部启用主备,每个区域使用多个区域和至少3个可用区。
-
增加AWS特定资源的使用,例如自动扩展组(而不是使用固定的节点集群),应用程序负载平衡器(ALB)等。
-
编写更好的自动化:我们改进了自动化,完全采用基础架构作为代码,使用TerraForm和SaltStack来配置新的Auth0环境(以及替换现有的环境)。这使我们能够从每秒约300次登录的部分自动化环境发展到每秒执行超过3.4万次登录的全自动环境; 使用新工具可以更容易地向上扩展(并且只要有意义就向下扩展)。我们实现的自动化水平并不完美,但允许我们以更加便捷的方式发展到新的地区并创造新的环境。
-
编写更好的脚本文件:我们看到除了自动化之外,我们还需要更好的脚本文件,以便理解,管理和响应与我们不断增长的服务网格相关的事件。这大大提高了可扩展性和可靠性,同时也允许我们让新人可以更快的上手。
我们来看看我们的美国环境架构。我们有这个总体结构:

这是单个AZ内部的结构:
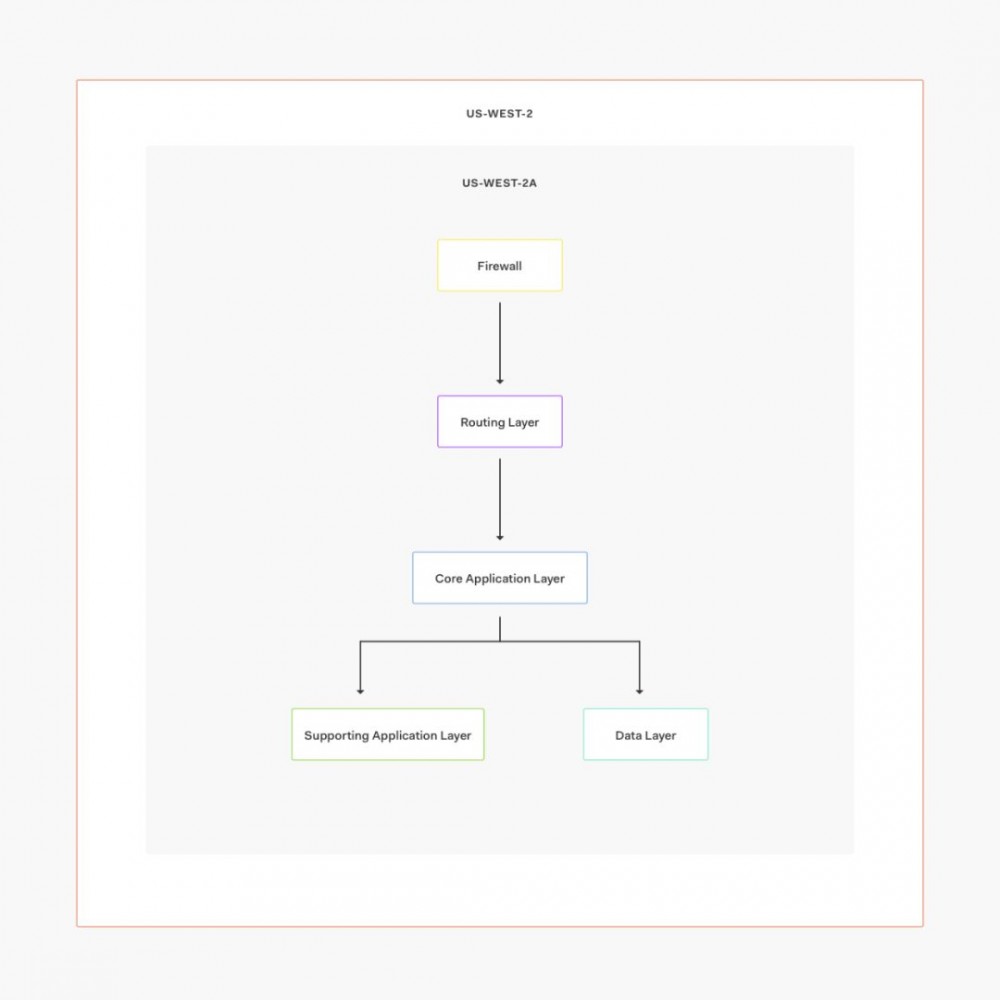
在这种情况下,我们使用两个AWS区域:us-west-2(主集群)和us-west-1(备份集群)。在正常情况下,所有请求都将转到us-west-2,由三个单独的可用区域提供服务。
这就是我们实现高可用性的方式:所有服务(包括数据库)都在每个可用区(AZ)上运行实例。如果一个AZ由于数据中心故障而关闭,我们仍有两个AZ来处理来自的请求。如果整个区域出现故障或出现错误,我们可以更新Route53以故障转移到us-west-1并恢复操作。
我们通过在每个AWS可用区域上运行所有服务实例来实现高可用性
我们在服务故障转移方面有不同的成熟度级别:某些服务,例如用户搜索v2(在Elasticsearch上构建缓存)可能有效,但数据稍有延迟;另外,核心功能保持按预期工作。
在数据层中,我们使用:
-
MongoDB的跨区域集群。
-
PostgreSQL的RDS复制。
-
Elasticsearch的每个区域的群集具有自动快照和恢复,定期运行以解决缺少跨区域群集的问题。
我们每年至少进行一次故障演练,我们有手册和自动化,以帮助新的基础设施工程师快速了解如何做到这一点以及产生什么影响。
(编者: 每年至少一次故障演练,对于真正发生区域不可用的时候指导意义是否足够?)
我们的部署通常由Jenkins节点触发; 根据服务,我们使用Puppet,SaltStack和/或Ansible来更新单个节点或节点组,或者我们更新AMI并为不可变部署创建新的自动缩放组。 我们为新旧服务部署了不同类型的部署。 维护文档和监控应该统一的内容,在我们需要维护自动化的同时,作用上很大程度上显得微乎其微。
自动化测试
除了每个项目的单元测试覆盖率外,我们还提供多个功能测试套件,可在各种环境中运行; 我们在部署到生产之前在预生产环境中运行它,并在完成部署后再次在生产环境中运行它们以确保一切正常。
亮点:
-
在不同的项目中有数千个单元测试。
-
每分钟执行Pingdom来探测核心功能。
-
我们在每次部署之前和之后都使用Selenium和基于CodeceptJS的功能测试。 功能测试套件测试不同的API端点,身份验证流程,身份提供程序等等。
除了每个项目的单元测试覆盖率外,我们还有多个功能测试套件,可在各种环境中运行:在部署到生产之前进行分段,在完成部署后再次进行生产。
CDN
直到2017年,我们在多个地区使用NGINX,Varnish和EC2节点运行我们自己定制的CDN。从那时起,我们转向CloudFront,这给了我们几个好处,包括:
-
更多位置接入,这意味着我们的客户延迟更少。
-
降低维护成本。
-
配置更简单。
有一些缺点,比如我们需要运行Lambdas来执行某些配置(比如将自定义标头添加到PDF文件等等)。 不过,好处远远大于这些。
Extend
(译者补充: Extend [https://goextend.io/]是Auth0开发的一个平台,用于实现SaaS的自定义和集成)
我们提供的功能之一是能够通过身份验证规则或自定义数据库连接将自定义代码作为登录事务的一部分运行。 这些功能由Extend提供支持,Extend是一个可扩展性平台,由Auth0开发,现在也被其他公司使用。 通过Extend,我们的客户可以在这些脚本和规则中编写他们想要的任何内容,允许他们扩展配置文件,规范化属性,发送通知等等。
我们专门为Auth0扩展了集群; 他们使用EC2自动扩展组,Docker容器和自定义代理的组合来处理来自租户的请求,每秒处理数千个请求并快速响应负载变化。 有关如何构建和运行它的更多详细信息,请查看有关如何构建自己的无服务器平台的帖子。
监控
我们使用不同工具的组合来监控和调试问题:
-
CloudWatch
-
DataDog
-
Pingdom的
-
SENTINL
我们的绝大多数警报都来自CloudWatch和DataDog。
我们倾向于通过TerraForm配置CloudWatch警报,我们在CloudWatch上保留的主要监视器是:
-
来自主负载均衡器的HTTP错误。
-
目标组中的不健康实例。
-
SQS处理延迟。
CloudWatch是基于AWS生成的指标(如来自负载均衡器或自动扩展组的指标)的最佳警报工具。 CloudWatch警报通常发送给PagerDuty,从PagerDuty发送到Slack / phones。
DataDog是我们用来存储时间序列指标并采取行动的服务。 我们从Linux机箱,AWS资源,现成服务(如NGINX或MongoDB)以及我们构建的自定义服务(如我们的Management API)发送指标。
我们有很多DataDog监视器。 几个例子:
-
$环境中$ service的响应时间增加。
-
$ instance($ ip_address)中$ volume的空间不足。
-
$ environment / $ host($ ip_address)上的$ process问题。
-
$ environ ment 下$ service 的处理时间增加。
-
NTP在$ host($ ip_address)上漂移/关闭时钟问题。
-
MongoDB副本设置在$ environment上发生了变化。
从上面的示例中可以看出,我们监控了低级指标(如磁盘空间)和高级指标(如MongoDB副本集更改,例如如果主节点定义发生更改,则会提醒我们)。 我们做了很多,并在一些服务周围有一些非常复杂的监视器。
DataDog警报的输出非常灵活,我们通常会将它们全部发送给Slack,只向那些应该“唤醒人们”的人发送给PagerDuty(如错误峰值,或者我们确定会对客户产生影响的大多数事情)。
对于日志记录,我们使用Kibana和SumoLogic; 我们使用SumoLogic来记录审计跟踪和许多AWS生成的日志,我们使用Kibana来存储来自我们自己的服务和其他“现成”服务(如NGINX和MongoDB)的应用程序日志。
未来
随着业务发展,我们的平台增长了,而且我们的工程组织规模不断扩大: 我们有许多新团队建立自己的服务,并且需要自动化,工具和可扩展性指导。 考虑到这一点,这些是我们不仅要扩展我们的平台而且要扩展我们的工程实践的举措:
构建PaaS风格的平台: 正如前面所提到的,今天我们有不同的自动化和部署流程;这会造成混乱并为工程师设置了障碍,因为很难在没有涉及太多存储库的情况下进行实验和扩展。 我们正在开发一个平台的PoC(目前运行在ECS之上),工程师可以在其中配置YAML文件并将其部署以获取计算资源,监控,日志记录,备份等等。 所有这些都无需明确配置。 这项工作还处于早期阶段,可能仍会发生很大变化(EKS? )。 但是,鉴于我们不断扩大的规模和可扩展性限制,我们认为我们正在采取正确的方向。
为每个新的PR(pull request)实施冒烟测试: 除了单元测试(已经在每个新PR上运行),我们希望在可能的情况下在短暂环境中运行集成测试。
将我们的日志记录解决方案集中到一个提供商这可能意味着远离Kibana并仅使用SumoLogic,但我们仍需要评估功能集,数据量等。
自动化指标: 现在我们的指标数据太多是手动的: 在部署时添加与代码相关的指标调用,并使用DataDog界面构建仪表板和监视器。 如果我们使用标准格式和命名,我们可以自动构建仪表板/监视器,从日志中提取度量而不是显式添加对代码的调用等等。
原文地址: https://auth0.com/blog/auth0-architecture-running-in-multiple-cloud-providers-and-regions/
这篇文章是由Auth0的网站SER Dirceu Pereira Tiegs撰写的,最初发表于Auth0。
往期推荐 :
-
996.icu火爆之后,从程序到健身 -
智能监控成效的上限该如何突破?
-
”我是技术总监,我确实答不出那么多技术细节”
-
消息中间件不少,消息总线过时了吗?
-
第三方支付账务系统论述
-
研发慢、宕机多、品牌弱怎么办?前携程 CTO 解密技术体系
……
技术琐话
以分布式设计、架构、体系思想为基础,兼论研发相关的点点滴滴,不限于代码、质量体系和研发管理。本号由坐馆老司机技术团队维护。

正文到此结束
- 本文标签: src IO Kibana 备份 ip 美国 数据 需求 Docker 同步 ORM Elasticsearch 部署 Nginx 质量 数据库 调试 代码 实例 Service rabbitmq 覆盖率 web jenkins UI Google DOM provider 第三方支付 高可用 lambda 云 自动化 CDN Region API MongoDB 文章 分布式 单元测试 linux db 负载均衡 配置 管理 智能 开发 Architect id 缓存 测试 突破 sql IDE CTO 滴滴 http 希望 mongo 定制 js 集群 PaaS 空间 快的 ECS MQ 工程师 服务器 https 网站 redis 时间 组织
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

