Java基础1-String详解
概览
1. 类声明
String 被声明为 final,因此它不可被继承。
在 Java 8 及之前,内部使用 char 数组存储数据。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
在 Java 9 及之后,String 类的实现改用 byte 数组存储字符串,同时使用 coder 来标识使用了哪种字符集编码。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final byte[] value;
/** The identifier of the encoding used to encode the bytes in {@code value}. */
private final byte coder;
}
2. 构造函数
- 空参构造
/**
* final声明的 value数组不能修改它的引用,所以在构造函数中一定要初始化value属性
*/
public String() {
this.value = "".value;
}
- 用一个String来构造
/**
* 除非你明确需要 这个original字符串的 副本
*/
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
- 用char数组来构造
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
- 用byte[]来构造
/**
* 构造一个由byte[]生产的字符串,使用系统默认字符集编码
* 新数组的长度 不一定等于 数组的length
* 如果默认字符集编码不可用时,此构造器无效。
*/
public String(byte bytes[], int offset, int length) {
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}
- 用 Unicode编码的int[]来构造
/**
* 使用 Unicode编码的int数组 初始化字符串
* 入参数组修改不影响新创建的String
* @since 1.5
*/
public String(int[] codePoints, int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
//count = 0
if (offset <= codePoints.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > codePoints.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
final int end = offset + count;
// Pass 1: Compute precise size of char[]
int n = count;
for (int i = offset; i < end; i++) {
int c = codePoints[i];
// 从 U+0000 至 U+FFFF 之间的字符集有时候被称为基本多语言面
// 可以使用单个char来表示这样的代码点
if (Character.isBmpCodePoint(c))
continue;
// 确认c 是不是
else if (Character.isValidCodePoint(c))
n++;
else throw new IllegalArgumentException(Integer.toString(c));
}
// Pass 2: Allocate and fill in char[]
// 得到可以转成有效字符的 个数
final char[] v = new char[n];
for (int i = offset, j = 0; i < end; i++, j++) {
int c = codePoints[i];
if (Character.isBmpCodePoint(c))
v[j] = (char)c;
else
Character.toSurrogates(c, v, j++);
}
this.value = v;
}
}
- 用变长字符串StringBuffer,StringBuilder来构造
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
3. 常用api
方法列表:
boolean isEmpty() //当且仅当 length() 为 0 时返回 true
int length() //返回此字符串的长度
boolean contains(CharSequence s) //当且仅当此字符串包含指定的 char 值序列时,返回 true
char charAt(int index) //返回指定索引处的 char 值
String concat(String str) //将指定字符串连接到此字符串的结尾
int indexOf(int ch) //返回指定字符在此字符串中第一次出现处的索引
int lastIndexOf(int ch) //返回指定字符在此字符串中最后一次出现处的索引
String substring(int beginIndex, int endIndex) //返回一个新字符串,它是此字符串的一个子字符串
CharSequence subSequence(int beginIndex, int endIndex) //返回一个新的字符序列,它是此序列的一个子序列
int compareTo(String anotherString) //按字典顺序比较两个字符串
int compareToIgnoreCase(String str) //按字典顺序比较两个字符串,不考虑大小写
boolean equalsIgnoreCase(String anotherString) //将此 String 与另一个 String 比较,不考虑大小写
static String valueOf(double d)
static String valueOf(boolean b)
byte[] getBytes(Charset charset) //使用给定的 charset 将此 String 编码到 byte 序列,并将结果存储到新的 byte 数组
byte[] getBytes(String charsetName) //使用指定的字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中
String toLowerCase(Locale locale) //使用给定 Locale 的规则将此 String 中的所有字符都转换为小写
String toUpperCase(Locale locale)
boolean matches(String regex) //告知此字符串是否匹配给定的正则表达式
String[] split(String regex, int limit) //根据匹配给定的正则表达式来拆分此字符串
boolean startsWith(String prefix, int toffset) //测试此字符串从指定索引开始的子字符串是否以指定前缀开始
boolean endsWith(String suffix)
static String copyValueOf(char[] data)//返回指定数组中表示该字符序列的
char[] toCharArray() //将此字符串转换为一个新的字符数组
String replace(char oldChar, char newChar) //返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的
String replaceAll(String regex, String replacement) //使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串
String intern() //返回字符串对象的规范化表示形式,字符串pool中的存在返回,不存在存入pool并返回
String trim()//返回字符串的副本,忽略前导空白和尾部空白
static String format(Locale l, String format, Object... args) //使用指定的语言环境、格式字符串和参数返回一个格式化字符串
4. 不可修改的特点
为何不可修改
以下两点保证String的 不可修改 特点
- value 被声明为 final,即value引用的地址不可修改。
- String类没有暴露修改value引用内容的方法。
不可修改的优点
从内存,同步和数据结构角度分析:
- Requirement of String Pool :字符串池(String intern pool)是方法区域中的特殊存储区域。 创建字符串并且池中已存在该字符串时,将返回现有字符串的引用,而不是创建新对象。如果字符串可变,这将毫无意义。
- Caching Hashcode :hashcode在java中被频繁的使用,在String类中存在属性
private int hash;//this is used to cache hash code. -
Facilitating the Use of Other Objects:确保第三方使用。举一个例子:
//假设String.class 有属性 value; //set的本意是保证元素不重复出现,如果String是可变的,则会破坏这个规则 HashSet<String> set = new HashSet<String>(); set.add(new String("a")); set.add(new String("b")); set.add(new String("c")); for(String a: set) a.value = "a"; -
Security:String被广泛用作许多java类的参数,例如 网络连接,打开文件等。字符串不是不可变的,连接或文件将被更改,这可能会导致严重的安全威胁。 该方法认为它连接到一台机器,但事实并非如此。 可变字符串也可能在Reflection中引起安全问题,因为参数是字符串。例子:
boolean connect(string s){ if (!isSecure(s)) { throw new SecurityException(); } //here will cause problem, if s is changed before this by using other references. causeProblem(s); } - Immutable objects are naturally thread-safe :由于无法更改不可变对象,因此可以在多个线程之间自由共享它们。 这消除了进行同步的要求。
总之,出于效率和安全原因,String被设计为不可变的。 这也是在一般情况下在一些情况下优选不可变类的原因。
5. 字符串pool
什么是池
在 JAVA 语言中有8中基本类型和一种比较特殊的类型 String 。这些类型为了使他们在运行过程中速度更快,更节省内存,都提供了一种常量池的概念。常量池就类似一个JAVA系统级别提供的缓存。8种基本类型的常量池都是系统协调的, String 类型的常量池比较特殊。它的主要使用方法有两种:
- 直接使用双引号声明出来的
String对象会直接存储在常量池中 - 如果不是用双引号声明的
String对象,可以使用String提供的intern方法。intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中 - 在 jdk6 及以前的版本中,字符串的常量池是放在堆的 Perm 区的(Perm 区是一个类静态的区域,主要存储一些加载类的信息,常量池,方法片段等内容,默认大小只有4m),一旦常量池中大量使用 intern 是会直接产生
java.lang.OutOfMemoryError: PermGen space错误的。 - 在jdk7中,字符串常量池已经从 Perm 区移到正常的 Java Heap 区域。
String#intern方法
它的大体实现结构就是: JAVA 使用 jni 调用c++实现的 StringTable 的 intern 方法, StringTable 的 intern 方法跟Java中的 HashMap 的实现是差不多的, 只是不能自动扩容。默认大小是1009
注意点:
Hashtable String.intern -XX:StringTableSize=99991
实例思考
// JDK6 中执行: false false
// JDK7 中执行: false true
public static void main(String[] args) {
// 声明的字符创变量 -> 堆
String s = new String("1");
s.intern();
// 声明的字符创常量 -> 堆的 Perm 区
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
// JDK6 中执行: false false
// JDK7 中执行: false false
public static void main(String[] args) {
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
-
jdk6内存分析(注:图中绿色线条代表 string 对象的内容指向。 黑色线条代表地址指向)
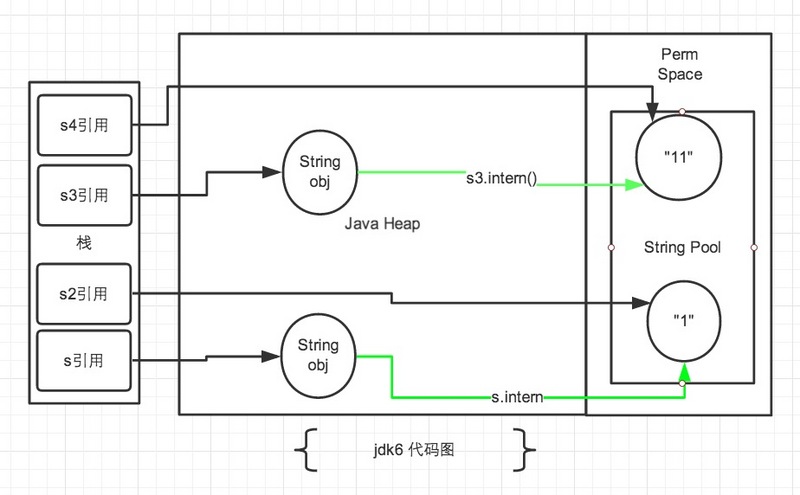
String s = new String("1"); String s3 = new String("1") + new String("1"); s.intern(); -
jdk7内存分析-1
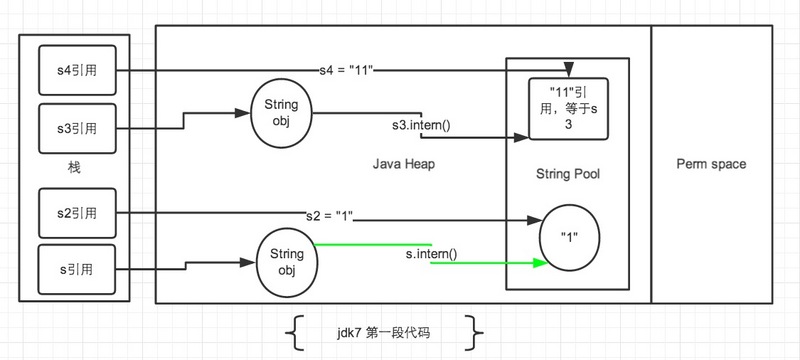
- 在第一段代码中,先看 s3和s4字符串。
String s3 = new String("1") + new String("1");,这句代码中现在生成了2最终个对象,是字符串常量池中的“1” 和 JAVA Heap 中的 s3引用指向的对象。中间还有2个匿名的new String("1")我们不去讨论它们。此时s3引用对象内容是”11”,但此时常量池中是没有 “11”对象的。 - 接下来
s3.intern();这一句代码,是将 s3中的“11”字符串放入 String 常量池中,因为此时常量池中不存在“11”字符串,因此常规做法是跟 jdk6 图中表示的那样,在常量池中生成一个 “11” 的对象,关键点是 jdk7 中常量池不在 Perm 区域了,这块做了调整。常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用指向 s3 引用的对象。 也就是说引用地址是相同的。 - 最后
String s4 = "11";这句代码中”11”是显示声明的,因此会直接去常量池中创建,创建的时候发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。所以 s4 引用就指向和 s3 一样了。因此最后的比较s3 == s4是 true。 - 再看 s 和 s2 对象。
String s = new String("1");第一句代码,生成了2个对象。常量池中的“1” 和 JAVA Heap 中的字符串对象。s.intern();这一句是 s 对象去常量池中寻找后发现 “1” 已经在常量池里了。 - 接下来
String s2 = "1";这句代码是生成一个 s2的引用指向常量池中的“1”对象。 结果就是 s 和 s2 的引用地址明显不同。图中画的很清晰。
- 在第一段代码中,先看 s3和s4字符串。
-
jdk7内存分析-2

- 来看第二段代码,从上边第二幅图中观察。第一段代码和第二段代码的改变就是
s3.intern();的顺序是放在String s4 = "11";后了。这样,首先执行String s4 = "11";声明 s4 的时候常量池中是不存在“11”对象的,执行完毕后,“11“对象是 s4 声明产生的新对象。然后再执行s3.intern();时,常量池中“11”对象已经存在了,因此 s3 和 s4 的引用是不同的。 - 第二段代码中的 s 和 s2 代码中,
s.intern();,这一句往后放也不会有什么影响了,因为对象池中在执行第一句代码String s = new String("1");的时候已经生成“1”对象了。下边的s2声明都是直接从常量池中取地址引用的。 s 和 s2 的引用地址是不会相等的。
- 来看第二段代码,从上边第二幅图中观察。第一段代码和第二段代码的改变就是
-
小结-从上述的例子代码可以看出 jdk7 版本对 intern 操作和常量池都做了一定的修。主要包括2点:
String#intern
参考:
https://tech.meituan.com/2014...
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

