扒一扒Spring Cloud Eureka
Eureka架构
Eureka是Netflix开发的服务发现框架,本身是一个基于REST的服务。在spring cloud中担任比较中心的位置,eureka包含两个组件:
- Eureka Server:注册中心服务端,用于维护和管理注册服务列表
- Eureka Client:注册中心客户端,向注册中心注册服务和获取服务
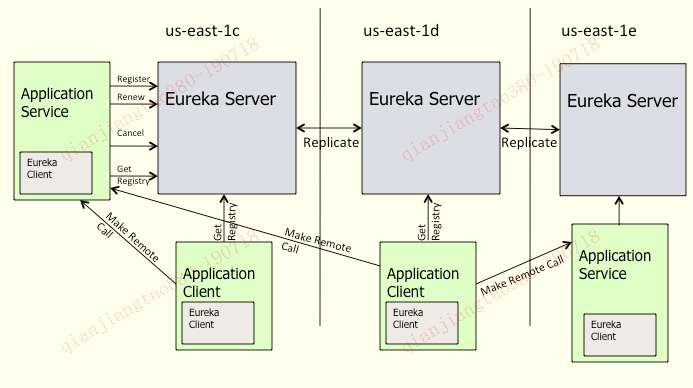
上图是来自官网的架构图,其中us-east-1c和us-east-1d,us-east-1e是代表不同的区也就是不同的机房,其中每一个eureka server都是一个集群。application service作为服务提供方向eureka中注册服务,eureka server接受到注册事件会在集群和 分区中进行数据同步,application client作为消费端可以从eureka中获取到服务注册信息,进行服务调用。这是作为注册中心 一个最简单的流程,其中有隐藏了很多细节问题,接下来让我们扒一扒其中的一些细节。
扒一扒Eureka
我们就从常用的注册中心zookeeper中展开对eureka的分析,zk作为注册中心的时候通过znode来存储服务provider信息, 在服务进行注册时实际上就是创建一个znode临时节点,利用临时节点的特性实现服务的下线,然后利用zk天然的强一致性协议 实现集群中注册信息同步,通过leader选举实现高可用性。客户端在进行获取服务注册信息时,通过zk的目录结构进行查找效率 非常高。一切都这么完美。那eureka又是怎么处理的呢?
Register(服务注册)
那eureka又是怎么处理的呢?首先看下最核心的服务注册,eureka是如何进行服务注册呢?带着问题看下eureka的流程。
熟悉的spring boot的同学都大概了解它的自动装配的原理,每个自定义starter都会在spring.factories中配置EnableAutoConfiguration自动配置类。eureka也是如下:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=/ org.springframework.cloud.netflix.eureka.config.EurekaClientConfigServerAutoConfiguration,/ org.springframework.cloud.netflix.eureka.config.EurekaDiscoveryClientConfigServiceAutoConfiguration,/ org.springframework.cloud.netflix.eureka.EurekaClientAutoConfiguration,/ org.springframework.cloud.netflix.ribbon.eureka.RibbonEurekaAutoConfiguration,/ org.springframework.cloud.netflix.eureka.EurekaDiscoveryClientConfiguration
我们重点关注下EurekaClientAutoConfiguration,在客户端启动的时候这个自动化配置会根据条件判断是否初始化创建所需要的bean,如:EurekaClientConfigBean,EurekaAutoServiceRegistration等,
对于注册我们只要关注EurekaAutoServiceRegistration就可以了,如下:
@Bean
@ConditionalOnBean(AutoServiceRegistrationProperties.class)
@ConditionalOnProperty(value = "spring.cloud.service-registry.auto-registration.enabled", matchIfMissing = true)
public EurekaAutoServiceRegistration eurekaAutoServiceRegistration(
ApplicationContext context, EurekaServiceRegistry registry,
EurekaRegistration registration) {
return new EurekaAutoServiceRegistration(context, registry, registration);
}
可是我们并没有设置spring.cloud.service-registry.auto-registration.enabled呀,看名字就知道是配置是否自动注册服务的,我猜这种配置作为客户端都是会注册的,
所以为了方便起见会默认为true的,当然不能全靠蒙的,于是我就搜索下果然默认为true:
{
"name": "spring.cloud.service-registry.auto-registration.enabled",
"type": "java.lang.Boolean",
"description": "Whether service auto-registration is enabled. Defaults to true.",
"sourceType": "org.springframework.cloud.client.serviceregistry.AutoServiceRegistrationProperties",
"defaultValue": true
}
可是创建这个bean有啥用呢?仔细看看这个类就能看出来一些问题,如下:
public class EurekaAutoServiceRegistration implements AutoServiceRegistration,
SmartLifecycle, Ordered, SmartApplicationListener {
}
实现了SmartLifecycle接口,所以熟悉spring的同学就会很熟悉这个类的,spring 在bean初始化完成后会调实现Lifecycle接口的start方法,在销毁的时候会调用stop方法,那我们就看看EurekaAutoServiceRegistration的start的方法:
// only initialize if nonSecurePort is greater than 0 and it isn't already running
// because of containerPortInitializer below
if (!this.running.get() && this.registration.getNonSecurePort() > 0) {
this.serviceRegistry.register(this.registration);
this.context.publishEvent(new InstanceRegisteredEvent<>(this,
this.registration.getInstanceConfig()));
this.running.set(true);
}
根据配置的端口判断是否要进行注册,看代码看到一个很关键的代码register, 一路走下去会调用 discoveryClient的registerHealthCheck -> onDemandUpdate -> InstanceInfoReplicator的run方法,这段代码比较简单最后调用了discoveryClient的register方法,
到这里最关键的注册方法我们终于找到了,接下来就是使用jersey类似spring mvc的web框架,使用post请求进行注册如下:
public EurekaHttpResponse<Void> register(InstanceInfo info) {
String urlPath = "apps/" + info.getAppName();
ClientResponse response = null;
try {
//使用jerseyClient发送post请求进行注册
//完整的url:http://127.0.0.1:8001/eureka/apps/${application.name}
Builder resourceBuilder = jerseyClient.resource(serviceUrl).path(urlPath).getRequestBuilder();
addExtraHeaders(resourceBuilder);
response = resourceBuilder
.header("Accept-Encoding", "gzip")
.type(MediaType.APPLICATION_JSON_TYPE)
.accept(MediaType.APPLICATION_JSON)
.post(ClientResponse.class, info);
return anEurekaHttpResponse(response.getStatus()).headers(headersOf(response)).build();
}
}
eureka服务端接受请求的都在core下的resource目录下,类似与spring中的controller,客户端服务注册的请求映射到ApplicationResource#addInstance进行服务注册,接下来我们看下服务端的大概的注册流程。核心方法是AbstractInstanceRegistry#register,主要流程如下:
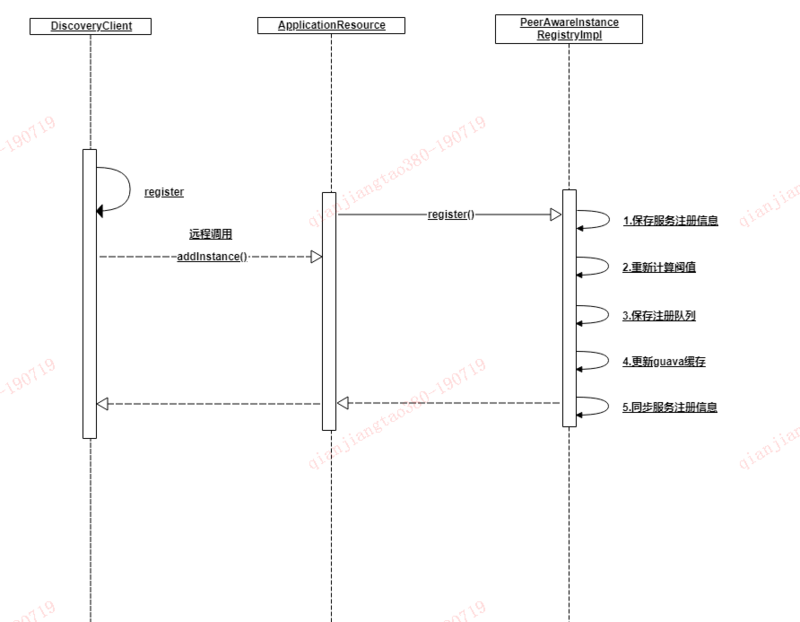
Eureka注册表
在上面我们说过在zk中服务信息保存到znode中,而eureka只是一个简单servlet web应用,它是如何保存服务信息呢?首先想到的肯定是map,如果考虑线程安全问题那就是ConcurrentHashMap,是这样吗?在上面服务注册的最后我们看到一段重要的代码:
//首先判断注册表中是否存在该服务
Map<String, Lease<InstanceInfo>> gMap = registry.get(registrant.getAppName());
REGISTER.increment(isReplication);
if (gMap == null) {
//如果为空就创建一个以appname作为key的空的map
final ConcurrentHashMap<String, Lease<InstanceInfo>> gNewMap = new ConcurrentHashMap<String, Lease<InstanceInfo>>();
gMap = registry.putIfAbsent(registrant.getAppName(), gNewMap);
if (gMap == null) {
gMap = gNewMap;
}
}
可以看出eureka中保存服务注册信息的确实就是一个ConcurrentHashMap,数据结构如下:
ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry = new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();
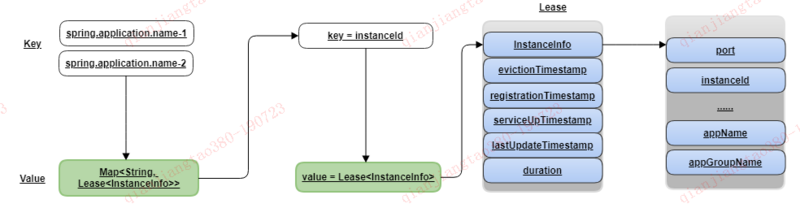
Fetch Registry(抓取注册信息)
至此我们已经很清楚的了解到服务是如何发布到注册中心,并且了解到了注册中心的核心数据结构注册列表,但是服务消费者是如何进行获取服务注册信息呢?并且如何感知有新的服务进行了注册呢?在上面服务注册中我们知道spring boot自动化配置中,在服务启动的时候会自动创建一些bean,所以我们再次回到EurekaClientAutoConfiguration中,我们会看到一个重要的内部类:RefreshableEurekaClientConfiguration,具体代码如下:
@Configuration
@ConditionalOnRefreshScope
protected static class RefreshableEurekaClientConfiguration {
@Autowired
private ApplicationContext context;
@Autowired
private AbstractDiscoveryClientOptionalArgs<?> optionalArgs;
@Bean(destroyMethod = "shutdown")
@ConditionalOnMissingBean(value = EurekaClient.class, search = SearchStrategy.CURRENT)
@org.springframework.cloud.context.config.annotation.RefreshScope
@Lazy
public EurekaClient eurekaClient(ApplicationInfoManager manager,
EurekaClientConfig config, EurekaInstanceConfig instance,
@Autowired(required = false) HealthCheckHandler healthCheckHandler) {
ApplicationInfoManager appManager;
if (AopUtils.isAopProxy(manager)) {
appManager = ProxyUtils.getTargetObject(manager);
}
else {
appManager = manager;
}
CloudEurekaClient cloudEurekaClient = new CloudEurekaClient(appManager, config, this.optionalArgs, this.context);
cloudEurekaClient.registerHealthCheck(healthCheckHandler);
return cloudEurekaClient;
}
}
上面的代码在服务启动的时候会创建@Bean标记的EurekaClient,在内部我们看到会创建CloudEurekaClient,而服务的信息获取的核心是调用父类的DiscoveryClient构造方法,没错又是这个类,在服务注册中也看到了, 其实eureka的核心也是这个类,下面就是跟服务获取的主要代码:
//1,初始化应用集合在本地的缓存
localRegionApps.set(new Applications());
//2,shouldFetchRegistry = true,fetchRegistry进行服务获取
if (clientConfig.shouldFetchRegistry() && !fetchRegistry(false)) {
fetchRegistryFromBackup();
}
//3,启东线程进行服务定时更新
initScheduledTasks();
首先看下fetchRegister方法,看看是如何进行服务获取的:
private boolean fetchRegistry(boolean forceFullRegistryFetch) {
try {
//...省略...
if (clientConfig.shouldDisableDelta()
|| (!Strings.isNullOrEmpty(clientConfig.getRegistryRefreshSingleVipAddress()))
|| forceFullRegistryFetch
|| (applications == null)
|| (applications.getRegisteredApplications().size() == 0)
|| (applications.getVersion() == -1))
{
//...省略...
//1,服务全量获取服务信息
getAndStoreFullRegistry();
} else {
//2,增量获取服务信息
getAndUpdateDelta(applications);
}
} catch (Throwable e) {
logger.error(PREFIX + "{} - was unable to refresh its cache! status = {}", appPathIdentifier, e.getMessage(), e);
return false;
}
}
当客户端第一次启动的时候会调用fetchRegister进行全量获取服务信息也就是走到代码中的1的逻辑中,里面的逻辑也比较简单有兴趣的同学可以自己看下,那什么时候会执行2的步骤呢?之前的代码中我们提到initScheduledTasks会进行服务异步更新,不妨看看initScheduledTasks的实现:
private void initScheduledTasks() {
if (clientConfig.shouldFetchRegistry()) {
// registry cache refresh timer
int registryFetchIntervalSeconds = clientConfig.getRegistryFetchIntervalSeconds();
int expBackOffBound = clientConfig.getCacheRefreshExecutorExponentialBackOffBound();
scheduler.schedule(
new TimedSupervisorTask(
"cacheRefresh",
scheduler,
cacheRefreshExecutor,
//1.间隔多长时间更新一次信息
registryFetchIntervalSeconds,
TimeUnit.SECONDS,
expBackOffBound,
//2.缓存刷新线程
new CacheRefreshThread()
),
registryFetchIntervalSeconds, TimeUnit.SECONDS);
}
}
从上面代码中可以看出eureka使用定时任务每隔registryFetchIntervalSeconds秒定时执行CacheRefreshThread线程,而线程内部会调用fetchRegistry方法进行增量获取。registryFetchIntervalSeconds是不是感觉很熟悉,没错我们经常会在yml或properties文件中配置这个值,如果不进行配置eureka默认30s会更新一次:
{
"name": "eureka.client.registry-fetch-interval-seconds",
"type": "java.lang.Integer",
"description": "Indicates how often(in seconds) to fetch the registry information from the eureka server.",
"sourceType": "org.springframework.cloud.netflix.eureka.EurekaClientConfigBean",
"defaultValue": 30
}
简单的说就是客户端启动的时候会进行一次服务全量获取,然后通过定时任务每隔一段时间对服务进行增量更新,大概的流程就是如此,当然内部细节也是很多的,比如服务端是如何响应的,有兴趣的可以自己研究下。
Renew(服务续约)
什么是服务续约?所谓的服务续约就是类似集群中的心跳机制,每隔一段时间发送一次心跳,表示节点是活着的,在eureka集群中也是这样的,Eureka Client注册到注册中心后,会通过Renew机制跟Eureka Server保持续约,告诉注册中心服务“我还活着”,以免Eureka Server的剔除任务将其剔除。 在之前的服务注册信息获取初始化Discovery client中会创建HeartbeatThread任务定时发送心跳进行续约:
// Heartbeat timer
scheduler.schedule(
new TimedSupervisorTask(
"heartbeat",
scheduler,
heartbeatExecutor,
//每隔一段时间发送一次心跳
renewalIntervalInSecs,
TimeUnit.SECONDS,
expBackOffBound,
//心跳线程
new HeartbeatThread()
),
renewalIntervalInSecs, TimeUnit.SECONDS);
{
"name": "eureka.instance.lease-renewal-interval-in-seconds",
"type": "java.lang.Integer",
"description": "Indicates how often (in seconds) ....
"sourceType": "org.springframework.cloud.netflix.eureka.EurekaInstanceConfigBean",
"defaultValue": 30
}
默认30s发送一次心跳进行续约,其本质就是向注册中心发送一次请求,可以看InstanceResource#renewLease(),底层是调用AbstractInstanceRegistry#renew,如下:
public boolean renew(String appName, String id, boolean isReplication) {
// 增加 续约次数 到 监控
RENEW.increment(isReplication);
// 获得 租约
Map<String, Lease<InstanceInfo>> gMap = registry.get(appName);
Lease<InstanceInfo> leaseToRenew = null;
if (gMap != null) {
leaseToRenew = gMap.get(id);
}
// 续约不存在
if (leaseToRenew == null) {
RENEW_NOT_FOUND.increment(isReplication);
logger.warn("DS: Registry: lease doesn't exist, registering resource: {} - {}", appName, id);
return false;
} else {
InstanceInfo instanceInfo = leaseToRenew.getHolder();
if (instanceInfo != null) {
// touchASGCache(instanceInfo.getASGName());
InstanceStatus overriddenInstanceStatus = this.getOverriddenInstanceStatus(
instanceInfo, leaseToRenew, isReplication);
//...省略...
}
// 新增续约每分钟次数
renewsLastMin.increment();
// 设置续约最后更新时间
leaseToRenew.renew();
return true;
}
}
简单的梳理下服务续约的流程时序图如下:
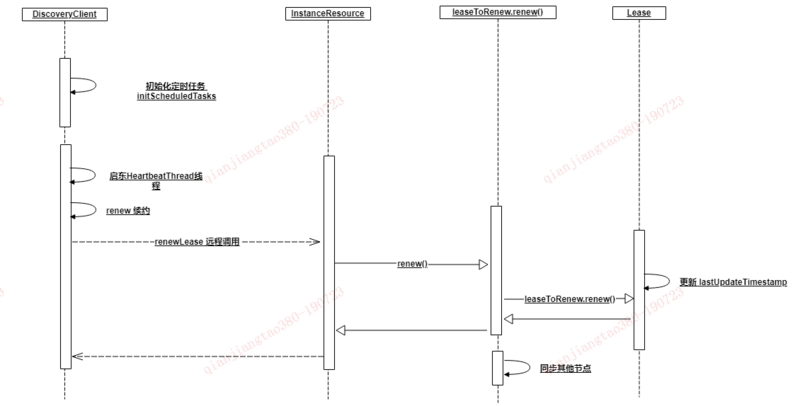
Cancel(服务注销)
服务注册和服务续约我们都说过了,那么如果服务挂了或因为网络问题注册中心收不到心跳信息,那么注册中心是怎么对服务进行剔除呢?eureka client挂了会调用DiscoveryClient#shutdown向服务端发送服务注销请求,具体的如下:
public synchronized void shutdown() {
if (isShutdown.compareAndSet(false, true)) {
if (applicationInfoManager != null
&& clientConfig.shouldRegisterWithEureka()
&& clientConfig.shouldUnregisterOnShutdown()) {
//将服务状态更新为down
applicationInfoManager.setInstanceStatus(InstanceStatus.DOWN);
//发送注销请求
unregister();
}
}
}
服务端收到注销请求(InstanceResource#cancelLease)后,会对该客户端进行注销,源码如下:
///服务下线
if (super.cancel(appName, id, isReplication)) {
//集群节点同步服务下线
replicateToPeers(Action.Cancel, appName, id, null, null, isReplication);
synchronized (lock) {
//更新阀值(最新的阀值已经修改为expectedNumberOfClientsSendingRenews和 numberOfRenewsPerMinThreshold)
if (this.expectedNumberOfClientsSendingRenews > 0) {
this.expectedNumberOfClientsSendingRenews = this.expectedNumberOfClientsSendingRenews - 1;
updateRenewsPerMinThreshold();
}
}
return true;
}
if (gMap != null) {
//1.将实例从服务列表中清除。
leaseToCancel = gMap.remove(id);
}
synchronized (recentCanceledQueue) {
//2.将这个变化事件添加到recentlyChangedQueue队列中
recentCanceledQueue.add(new Pair<Long, String>(System.currentTimeMillis(), appName + "(" + id + ")"));
}
//...省略...
//3.清空Guava缓存。
invalidateCache(appName, vip, svip);
logger.info("Cancelled instance {}/{} (replication={})", appName, id, isReplication);
return true;
}
Evict(服务剔除)
我们上面都详细的说过服务的注册,续约,注销等问题,在注销中我们只是介绍了eureka是如何注销的,但是并没有看到服务是什么时候剔除的,eureka server端又是如何剔除下线或过期的服务呢?接下来我们将详细的介绍服务端是如何进行剔除的。
在这之前我们不得不提到一个非常重要的类:EurekaServerInitializerConfiguration,这个就是服务剔除的入口,在服务注册的时候我们也提到了spring 在bean创建完成后会调用实现了SmartLifecycle的start()方法,而EurekaServerInitializerConfiguration也同样实现了`SmartLifecycle,
因此我看就有start()进入我们的服务剔除的探索,发现它是一个异步线程进行处理的:
public void start() {
new Thread(new Runnable() {
@Override
public void run() {
try {
// 核心方法
eurekaServerBootstrap.contextInitialized(
EurekaServerInitializerConfiguration.this.servletContext);
log.info("Started Eureka Server");
publish(new EurekaRegistryAvailableEvent(getEurekaServerConfig()));
EurekaServerInitializerConfiguration.this.running = true;
publish(new EurekaServerStartedEvent(getEurekaServerConfig()));
}
catch (Exception ex) {
// Help!
log.error("Could not initialize Eureka servlet context", ex);
}
}
}).start();
}
EurekaServerBootstrap#contextInitialized中完成了初始化环境设置和EurekaServerContext,其核心就是在初始化EurekaServerContext:
// Copy registry from neighboring eureka node int registryCount = this.registry.syncUp(); this.registry.openForTraffic(this.applicationInfoManager, registryCount);
protected void postInit() {
renewsLastMin.start();
if (evictionTaskRef.get() != null) {
evictionTaskRef.get().cancel();
}
//EvictionTask 线程进行服务剔除
evictionTaskRef.set(new EvictionTask());
evictionTimer.schedule(evictionTaskRef.get(),
serverConfig.getEvictionIntervalTimerInMs(),
serverConfig.getEvictionIntervalTimerInMs());
}
public void evict(long additionalLeaseMs) {
//1.判断是否过期
if (!isLeaseExpirationEnabled()) {
logger.debug("DS: lease expiration is currently disabled.");
return;
}
//2.筛选过期列表
List<Lease<InstanceInfo>> expiredLeases = new ArrayList<>();
for (Entry<String, Map<String, Lease<InstanceInfo>>> groupEntry : registry.entrySet()) {
Map<String, Lease<InstanceInfo>> leaseMap = groupEntry.getValue();
if (leaseMap != null) {
for (Entry<String, Lease<InstanceInfo>> leaseEntry : leaseMap.entrySet()) {
Lease<InstanceInfo> lease = leaseEntry.getValue();
if (lease.isExpired(additionalLeaseMs) && lease.getHolder() != null) {
expiredLeases.add(lease);
}
}
}
}
//3.进行公平剔除
int registrySize = (int) getLocalRegistrySize();
int registrySizeThreshold = (int) (registrySize * serverConfig.getRenewalPercentThreshold());
int evictionLimit = registrySize - registrySizeThreshold;
int toEvict = Math.min(expiredLeases.size(), evictionLimit);
if (toEvict > 0) {
logger.info("Evicting {} items (expired={}, evictionLimit={})", toEvict, expiredLeases.size(), evictionLimit);
Random random = new Random(System.currentTimeMillis());
for (int i = 0; i < toEvict; i++) {
// Pick a random item (Knuth shuffle algorithm)
int next = i + random.nextInt(expiredLeases.size() - i);
Collections.swap(expiredLeases, i, next);
Lease<InstanceInfo> lease = expiredLeases.get(i);
String appName = lease.getHolder().getAppName();
String id = lease.getHolder().getId();
EXPIRED.increment();
logger.warn("DS: Registry: expired lease for {}/{}", appName, id);
//4.清除guava缓存
internalCancel(appName, id, false);
}
}
}
如何判断实例过期是否可用 ? 必须满足两个条件:
public boolean isLeaseExpirationEnabled() {
if (!isSelfPreservationModeEnabled()) {
// The self preservation mode is disabled, hence allowing the instances to expire.
return true;
}
return numberOfRenewsPerMinThreshold > 0 && getNumOfRenewsInLastMin() > numberOfRenewsPerMinThreshold;
}
1.自我保护机制必须开启
2.上一分钟的续约数是否小于设定的最小续约数阀值 :
剔除操作时,首先计算过期的实例,并添加到过期实例列表里(expiredLeases)。如何判断呢?
//过期时间大于0 并且当前时间大于 最近续约时间 + duration + additionalLeaseMs
public boolean isExpired(long additionalLeaseMs) {
return (evictionTimestamp > 0 || System.currentTimeMillis() > (lastUpdateTimestamp + duration + additionalLeaseMs));
}
如何剔除选择?
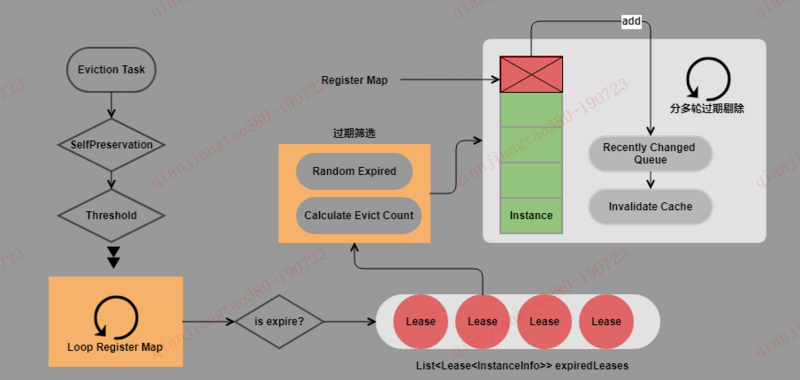
剔除第一步计算剔除最大数:实例总数 - 实例总数*自我保护阀值因子。
剔除第二步公平剔除:洗牌算法
比如我们一共有50个实例续约,并且20个实例过期了,并且自我保护阀值因子为0.8:
// 第一轮执行开始 int registrySize = 50; int registrySizeThreshold = (int) (50 * 0.8) = 40; int evictionLimit = 50 - 40 = 10; int toEvict = Math.min(20, 10) = 10; // 第一轮执行结束,剩余 40 个租约,其中有 10 个租约过期。 // 第二轮执行开始 int registrySize = 40; int registrySizeThreshold = (int) (40 * 0.8) = 32; int evictionLimit = 40 - 32 = 8; int toEvict = Math.min(10, 8) = 8; // 第二轮执行结束,剩余 32 个租约,其中有 8 个租约过期。 // 第三轮执行开始 int registrySize = 32; int registrySizeThreshold = (int) (32 * 0.8) = 25; int evictionLimit = 32 - 25 = 7; int toEvict = Math.min(2, 7) = 2; // 第三轮执行结束,剩余 30 个租约,其中有 2 个租约过期。结束
为什么不全部剔除过期的实例?
由于 JVM GC ,或是本地时间差异原因,可能自我保护机制的阀值 expectedNumberOfRenewsPerMin、numberOfRenewsPerMinThreshold 不够正确,在过期这个相对“危险”的操作,重新计算自我保护的阀值。 随机清理过期的租约。由于租约是按照应用顺序添加到数组,通过随机的方式,尽量避免单个应用被全部过期。
节点同步复制原理
至此我们看过服务注册,续约,注销,剔除等功能,但是说的都是单节点的说明,注册中心又是如何同步这些信息呢?最后我们一起看下eureka是如何实现同步复制的。
eureka节点同步分为两种:
- 服务启动的时候进行节点同步
- 服务注册,注销等处理的时候进行同步
服务启动同步
eureka server在启动的时候初始化EurekaServerContext的时候,会调用syncUp进行节点同步,如果之前有同步失败,则sleep最大同步重试时间默认为0s再次重试同步:
for (int i = 0; ((i < serverConfig.getRegistrySyncRetries()) && (count == 0)); i++) {
if (i > 0) {
try {
//sleep 最大重试时间
Thread.sleep(serverConfig.getRegistrySyncRetryWaitMs());
} catch (InterruptedException e) {
logger.warn("Interrupted during registry transfer..");
break;
}
}
//同步
Applications apps = eurekaClient.getApplications();
for (Application app : apps.getRegisteredApplications()) {
for (InstanceInfo instance : app.getInstances()) {
try {
if (isRegisterable(instance)) {
register(instance, instance.getLeaseInfo().getDurationInSecs(), true);
count++;
}
} catch (Throwable t) {
logger.error("During DS init copy", t);
}
}
}
}
服务注册,注销等时候进行同步
接下来我们就以服务注册为例看下eureka服务端是如何进行服务同步的。在说服务端信息同步以前不得不说下eureka的任务相关的东西,因为在注册同步中涉及复杂的任务关系和复杂的队列转化。
- 任务分发器:TaskDispatcher
- 任务接收器:AcceptorExecutor,AcceptorRunner
- 任务执行器:TaskExecutors
- 任务处理器:TaskProcess
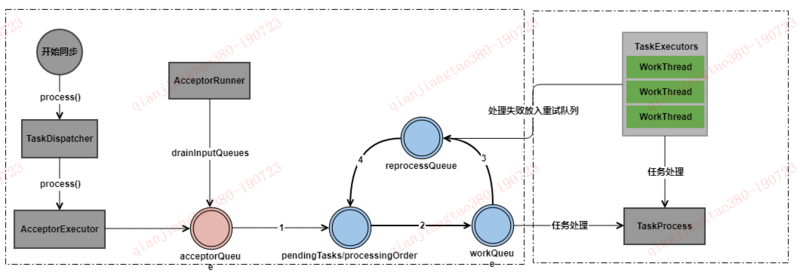
以上就是简单的eureka任务执行流程,那么任务执行的流程入口在哪呢?eureka是一个标准的Servlet应用,在eureka中有两个非常重要的类:EurekaBootStrap和EurekaServerBootStrap分别代表客户端与服务端的启动类,都实现了ServletContextListener,在tomcat启动的时候会调用contextInitialized进行初始化,既然是任务肯定是初始化的时候就启动了,然后有服务注册的时候直接向队列中丢任务就可以了,那么我们就来看看EurekaBootStrap的具体实现:
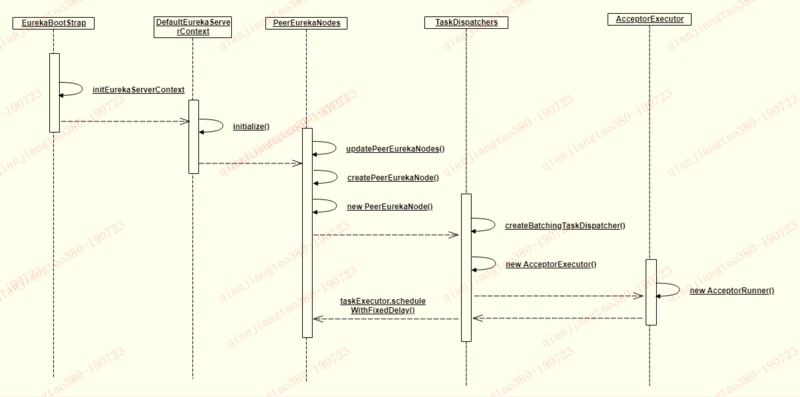
以上就是大概初始化流程我们主要看AcceptorRunner的实现,至此我们根据时序图就直接到AcceptorRunner:
class AcceptorRunner implements Runnable {
@Override
public void run() {
long scheduleTime = 0;
while (!isShutdown.get()) {
try {
//1.处理完输入队列( 接收队列 + 重新执行队列 )
drainInputQueues();
int totalItems = processingOrder.size();
long now = System.currentTimeMillis();
//2.计算调度时间
if (scheduleTime < now) {
scheduleTime = now + trafficShaper.transmissionDelay();
}
if (scheduleTime <= now) {
//3.调度批量任务
assignBatchWork();
//4.调度单任务
assignSingleItemWork();
}
} catch (InterruptedException ex) {
//......
}
}
}
至此初始化中对reprocessQueue,acceptorQueue和pendingTasks进行转化,当然eureka刚刚启动的时候是没有任何任务的,然后我们再回到PeerEurekaNodes#start方法中,队列初始化完成后,就执行任务:
try {
//对队列进行转化
updatePeerEurekaNodes(resolvePeerUrls());
//创建待执行的任务
Runnable peersUpdateTask = new Runnable() {
@Override
public void run() {
try {
updatePeerEurekaNodes(resolvePeerUrls());
} catch (Throwable e) {
logger.error("Cannot update the replica Nodes", e);
}
}
};
//开始执行任务
taskExecutor.scheduleWithFixedDelay(
peersUpdateTask,
serverConfig.getPeerEurekaNodesUpdateIntervalMs(),
serverConfig.getPeerEurekaNodesUpdateIntervalMs(),
TimeUnit.MILLISECONDS
);
} catch (Exception e) {
throw new IllegalStateException(e);
}
执行任务的核心就是askExecutors#batchExecutors的处理,会根据添加的任务创建TaskExecutors,然后执行线程run方法如下:
@Override
public void run() {
try {
while (!isShutdown.get()) {
List<TaskHolder<ID, T>> holders = getWork();
metrics.registerExpiryTimes(holders);
List<T> tasks = getTasksOf(holders);
//处理任务
ProcessingResult result = processor.process(tasks);
switch (result) {
case Success:
break;
case Congestion:
case TransientError:
taskDispatcher.reprocess(holders, result);
break;
case PermanentError:
logger.warn("Discarding {} tasks of {} due to permanent error", holders.size(), workerName);
}
metrics.registerTaskResult(result, tasks.size());
}
} catch (InterruptedException e) {
}
内部首先对task进行转化,转化成ReplicationList,然后批量提交分发到不同的节点上进行同步:
@Override
public ProcessingResult process(List<ReplicationTask> tasks) {
//task转化
ReplicationList list = createReplicationListOf(tasks);
//批量提交分发
EurekaHttpResponse<ReplicationListResponse> response = replicationClient.submitBatchUpdates(list);
}
至此我们完整的看完了eureka的任务处理流程还是比较复杂的,肯定会有同学有疑问不是说以服务注册为例子看下服务同步的吗,并没有看到注册同步呀!其实了解了任务的执行流程接下来的服务注册及其他的处理就很简单了
只要向任务系统中丢任务了就可以了,不妨我们看下注册的例子。在之前我们已经详细的说过服务注册流程了,就直接看下PeerAwareInstanceRegistryImpl#register的源代码:
@Override
public void register(final InstanceInfo info, final boolean isReplication) {
int leaseDuration = Lease.DEFAULT_DURATION_IN_SECS;
if (info.getLeaseInfo() != null && info.getLeaseInfo().getDurationInSecs() > 0) {
leaseDuration = info.getLeaseInfo().getDurationInSecs();
}
//服务注册
super.register(info, leaseDuration, isReplication);
//节点同步
replicateToPeers(Action.Register, info.getAppName(), info.getId(), info, null, isReplication);
}
内部对所有节点根据不同的类型进行相对应的处理
switch (action) {
case Cancel:
node.cancel(appName, id);
break;
case Heartbeat:
InstanceStatus overriddenStatus = overriddenInstanceStatusMap.get(id);
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.heartbeat(appName, id, infoFromRegistry, overriddenStatus, false);
break;
case Register:
//根据不同的action进行对应的处理,这里处理注册的事件
node.register(info);
break;
case StatusUpdate:
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.statusUpdate(appName, id, newStatus, infoFromRegistry);
break;
case DeleteStatusOverride:
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.deleteStatusOverride(appName, id, infoFromRegistry);
break;
}
public void register(final InstanceInfo info) throws Exception {
long expiryTime = System.currentTimeMillis() + getLeaseRenewalOf(info);
batchingDispatcher.process(
taskId("register", info),
new InstanceReplicationTask(targetHost, Action.Register, info, null, true) {
public EurekaHttpResponse<Void> execute() {
return replicationClient.register(info);
}
},
expiryTime
);
}
到这里我们就能看到其原理了,注册的处理就是向队列中添加InstanceReplicationTask任务,当线程开始执行这个任务的时间就会调用replicationClient.register(),向其他的集群节点进行相互注册达到服务同步的效果,至此eureka的集群同步就到处为止了。
最后
最近稍微闲一点就花点时间看看eureka,以上只是本人的学习总结,有很多细节也不是很了解,有些不一定准确仅供学习参考。最后想说下就是看源码的建议,看下大概的流程,大概的原理就可以了没必要了解每一个细节问题,不然真的很累。当遇到问题时可以相对应地详细的看下某个功能点的源码,这样效率更高!就像我们日常做项目一样,没有人一来公司就把公司的项目每一行代码都看一遍,当需要做一个需求的时候才会去看下相对应功能的代码。
正文到此结束
- 本文标签: CTO value 同步 message cache 高可用 服务注册 Proxy web servlet 线程 UI 时间 key provider http ORM Spring Boot 注册中心 synchronized zip description Region 需求 Collections 总结 ECS bean id Netflix 构造方法 update heartbeat swap 配置 代码 json final ask Service 服务端 ribbon JVM ssh 自动化 tar map 管理 实例 开发 core Action AOP Spring cloud ArrayList java node js zookeeper Bootstrap URLs REST src Property Collection 本质 ConcurrentHashMap spring rand 端口 https 安全 DOM Eureka client 处理器 IO bug HashMap rmi retry 源码 ip 集群 IDE App list build queue executor 一致性 EnableAutoConfiguration 目录 缓存 协议 tomcat cat 数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

