伪共享简介
CPU Cache
众所周知CPU处理速度与硬盘、内存的访问速度相差过大,需要通过CPU缓存进行磨合,否则会导致CPU整体吞吐量受到极大的影响。
而单一层缓存无论是价格、命中率、查找速度方面都是不能够满足要求的,因此现在很多CPU出现了三级缓存结构,访问速度如下:
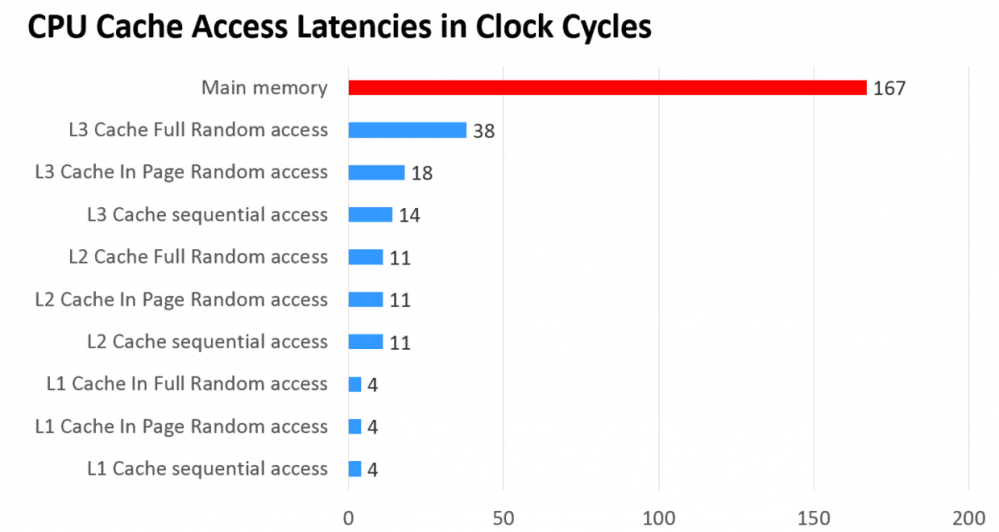
CPU缓存延迟,单位是CPU时钟周期,可以理解为CPU执行一个指令的时间
其中L1是L2的子集,L2是L3的子集,L1到L3缓存容量依次增大,查找耗时依次增大,CPU查找顺序依次是L1、L2、L3、主存。 L1与CPU core对应,是单核独占的,不会出现其他核修改的问题。一般L2也是单核独占。而L3一般是多核共享,可能操作同一份数据,那么就有可能出问题。
Cache Line
现代CPU读取数据通常以一块连续的块为单位,即缓存行(Cache Line)。所以通常情况下访问连续存储的数据会比随机访问要快,访问数组结构通常比链结构快,因为通常数组在内存中是连续分配的。
PS. JVM标准并未规定“数组必须分配在连续空间”,一些JVM实现中大数组不是分配在连续空间的。
缓存行的大小通常是64字节,这意味着即使只操作1字节的数据,CPU最少也会读取这个数据所在的连续64字节数据。
缓存失效
根据主流CPU为保证缓存有效性的MESI协议的简单理解,如果一个核正在使用的数据所在的缓存行被其他核修改,那么这个缓存行会失效,需要重新读取缓存。
False Sharing
如果多个核的线程在操作同一个缓存行中的不同变量数据,那么就会出现频繁的缓存失效,即使在代码层面看这两个线程操作的数据之间完全没有关系。
这种不合理的资源竞争情况学名伪共享(False Sharing),会严重影响机器的并发执行效率。
伪共享示例
// 多个线程,每个线程操作一个VolatileLong数组中的元素
// VolatileLong是否进行填充会影响最终结果
// 为填充时会产生伪共享问题,运行更慢,填充后不会
public class FalseShareTest implements Runnable {
public static int NUM_THREADS = 4;
public final static long ITERATIONS = 50L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public static long SUM_TIME = 0l;
public FalseShareTest(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
Thread.sleep(10000);
// 多个线程操作多个VolatileLong
for(int j=0; j<10; j++){
// 初始化
System.out.println(j);
if (args.length == 1) {
NUM_THREADS = Integer.parseInt(args[0]);
}
longs = new VolatileLong[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
final long start = System.nanoTime();
// 构造并启动线程
runTest();
final long end = System.nanoTime();
SUM_TIME += end - start;
}
System.out.println("平均耗时:"+SUM_TIME/10);
}
private static void runTest() throws InterruptedException {
// 创建每个线程, 每个线程操作一个VolatileLong
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseShareTest(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong {
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // 注释此行,结果区别很大
}
}
复制代码
VolatileLong是否使用6个long变量填充,结果相差很多。 使用填充,会避免伪共享,速度更快。
伪共享如何避免
Java8以下的版本
在Java8以下的版本中,可以使用填充的方式进行避免,比如 百度的snowflake实现 中使用的PaddedAtomicLong:
/**
* Represents a padded {@link AtomicLong} to prevent the FalseSharing problem<p>
*
* The CPU cache line commonly be 64 bytes, here is a sample of cache line after padding:<br>
* 64 bytes = 8 bytes (object reference) + 6 * 8 bytes (padded long) + 8 bytes (a long value)
*
* @author yutianbao
*/
public class PaddedAtomicLong extends AtomicLong {
private static final long serialVersionUID = -3415778863941386253L;
/** Padded 6 long (48 bytes) */
public volatile long p1, p2, p3, p4, p5, p6 = 7L;
/**
* Constructors from {@link AtomicLong}
*/
public PaddedAtomicLong() {
super();
}
public PaddedAtomicLong(long initialValue) {
super(initialValue);
}
/**
* To prevent GC optimizations for cleaning unused padded references
*/
public long sumPaddingToPreventOptimization() {
return p1 + p2 + p3 + p4 + p5 + p6;
}
}
复制代码
对象引用8字节,使用了6个long变量48字节进行填充,以及一个long型的值,一共64字节。 使用了sumPaddingToPreventOptimization方法规避编译器或GC优化没使用的变量。
Java8及以上的版本
从Java8开始原生支持避免伪共享,可以使用 @Contended 注解:
public class Point {
int x;
@Contended
int y;
}
复制代码
详见 @Contended 注解使用方法。
@Contended 注解会增加目标实例大小,要谨慎使用。默认情况下,除了 JDK 内部的类,JVM 会忽略该注解。要应用代码支持的话,要设置 -XX:-RestrictContended=false,它默认为 true(意味仅限 JDK 内部的类使用)。当然,也有个 –XX: EnableContented 的配置参数,来控制开启和关闭该注解的功能,默认是 true,如果改为 false,可以减少 Thread 和 ConcurrentHashMap 类的大小。参加《Java性能权威指南》210 页。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

