Java并发累加器
说到并发编程的问题,大多数人第一反应想到的就是大多数举线程安全例子时出现的一段代码:
... i++; // 自增 ... 复制代码
然后很自然地想到,由于 i++ 这个操作其实在底层是3个操作:
tmp1 = i; tmp2 = tmp1 + 1; i = tmp2;
因此, i++ 并非一个原子操作,在多线程环境下线程不安全。
那么问题来了,如果要实现一个累加器,在并发条件下实现 i++ 功能,应该怎么做?
比如:
- 记录某接口中的方法在1s内被调用了多少次
- 在LFU (Least Frequently Used) 算法中统计一个周期内某个对象被使用过多少次
- ......
方案1:AtomicLong
AtomicLong 位于 java.util.concurrent.atomic 包下,是一个无需加锁但线程安全且可实现 i++ 或 i += x 操作的类,作者是Doug Lea。
Doug Lea大师不用多介绍了,在我们看来出自他手的 AtomicLong 效率和线程安全“毋庸置疑”。当然如果连他的大名都不认识那真的应该反思一下了,毕竟 java.util.concurrent 包下绝大部分类都盖着他的戳呢......
AtomicLong 类中有一个属性value,用于记录这个Long的值;
这个value是volatile的,说明在不同线程中的修改对其他线程都是可见的;
这个类使用循环 + CAS (Compare And Swap) 的模式实现无锁线程安全;
这个类提供了 getAndAdd 、 addAndGet 等方法实现了 i++ 、 i += x 等操作的原子性。
在 AtomicLong 的实现中,get方法和set方法直接读取或修改value,由于volatile机制的保证,这两个操作是线程安全的。
在Java7中的核心方法
compareAndSet
方法接受两个参数,即拿期待将被替换的值和真实值比对,一致时才更新,否则失败。当然,这其中存在ABA问题,这里暂且先不讨论。
通过底层工具 Unsafe 的native方法 compareAndSwapLong 实现CAS操作,这个native方法是计算机硬件支持的,在高并发下有可能竞争失败,因为真实值已经被其他线程修改导致compare结果不一致。
public final boolean compareAndSet(long expect, long update) {
return unsafe.compareAndSwapLong(this, valueOffset, expect, update);
}
复制代码
getAndSet
读旧值写新值,这是通过循环 + CAS完成的,如果CAS赋值失败,说明有其他线程在竞争。这个方法会一直尝试到成功为止。
public final long getAndSet(long newValue) {
while (true) {
long current = get();
if (compareAndSet(current, newValue))
return current;
}
}
复制代码
其他核心方法
还有其他几个常用的核心方法,用于实现自增自减操作:
getAndIncrement getAndDecrement getAndAdd incrementAndGet decrementAndGet addAndGet
这几个方法都是都是通过循环 + CAS的方式实现原子化,以 getAndIncrement 举例:
// getAndIncrement
while (true) {
long current = get();
long next = current + 1;
if (compareAndSet(current, next)) // 实际就是unsafe.compareAndSwapLong
return current;
}
复制代码
在Java8中的实现
Unsafe新增了方法 getAndSetLong 、 getAndAddLong ,其实就是将Java7中 AtomicLong 的方法搬过去了。
除了 compareAndSet 方法还在使用 compareAndSwap 外,其他的方法均通过这两个getAndAdd方法完成:
getAndIncrement getAndDecrement getAndAdd incrementAndGet decrementAndGet addAndGet
当然, getAndAddLong 和 getAndSetLong 方法本质仍然是使用循环CAS实现,Java8中的 Unsafe 类反编译后的部分代码:
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
复制代码
但是,根据: Java 8中AtomicLong类的CAS相关更改如何工作? - 代码日志 这篇文章的说法,在Java7中的循环CAS方法内部的if条件语句在高并发下存在分支预测优化的问题导致效率变低。 原文翻译得很奇怪,我重新解读一下:
当在循环内的CAS经常失败时,CPU分支预测器开始起作用,以期望加速执行效率;一旦分支预测错误——即CAS执行成功了——处理器将耗费很多时间进行停止-回滚-热启动。
关于分支预测器,我们之后的博文会介绍。
ps.另外有说法是Java7中CAS的底层指令是LOCK CMPXCHG,在Java8中为LOCK XADD,导致Java8中CAS比Java7中效率高。 参考https://bugs.java.com/bugdatabase/view_bug.do?bug_id=7023898 中的描述,用XADD替换CMPXCHG我想在JDK7u40版本之后中应该已经被Java开发人员了解并实现自适应了。
方案2:LongAdder
在Java8中,Doug Lea大师在 java.util.concurrent.atomic 包中添加了几个新的类,其中有一个类叫做 LongAdder 。
看介绍,这个类是用于高并发下累加计算用的。
This class is usually preferable to {@link AtomicLong} when multiple threads update a common sum that is used for purposes such as collecting statistics, not for fine-grained synchronization control. Under low update contention, the two classes have similar characteristics. But under high contention, expected throughput of this class is significantly higher, at the expense of higher space consumption.
这个类(LongAdder)用于多个线程更新一个累加值,比如用于统计而不是用于控制同步时,效果会比使用AtomicLong更好。在低冲突下,这两个类特征类似,但在高冲突的情况下,这个类的预期吞吐量会更高,代价是消耗更多空间。
LongAdder 继承了 Striped64 ,我们来看看这两个类做了什么,以及为什么用于统计时预期效率会更高。
Striped64
内部包含子类 Cell ,实际上就是 AtomicLong 功能的子集,只保存value及其CAS功能,但没有其他诸如 get 、 incrementAndGet 等功能。并且 Cell 类使用 @Contended 注解避免伪共享问题。
内部定义了 transient volatile long base ,用于“保存值的一部分”;还定义了 transient volatile Cell[] cells ,用于“保存值的另一部分”。没错,base和cells共同组成了最终的值。
Striped64有两个最核心的方法—— longAccumulate 和 doubleAccumulate ,逻辑类似,一个处理整数(如 LongAdder 使用)一个处理浮点数(如 DoubleAdder 使用)。
这两个方法比较复杂,代码量较大,这里附上其中一个,建议仔细看一下,如果实在不想看也可以跳过,代码如下:
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h; // 探针值
if ((h = getProbe()) == 0) {
// 初始化一个探针值,其实就是一个跟线程相关的伪随机值
ThreadLocalRandom.current(); // force initialization
h = getProbe();
// 标记这个Striped64是否原来有值
// CAS失败调用longAccumulate方法时显然默认是false
wasUncontended = true;
}
// 线程操作碰撞标记,上一个槽非空时为true
// 也就是线程竞争碰撞时为true
boolean collide = false;
for (;;) {
Cell[] as; Cell a; int n; long v;
// 已经初始化的情况,绝大多数调用进入的分支
if ((as = cells) != null && (n = as.length) > 0) {
// 线程探针值对n取模,n是2的幂
// 实际上是找当前线程对应的Cell是否为null
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // 没人持有锁,尝试获取锁并添加Cell
Cell r = new Cell(x); // 乐观创建
if (cellsBusy == 0 && casCellsBusy()) { // CAS加锁
boolean created = false;
try { // 再次检查是否应当添加
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0; // 最后释放锁
}
// 如果创建成功了,跳出整个循环,计算结束
if (created)
break;
// 再次检查时这个槽已经被其他线程写入了,进入下一轮
continue; // Slot is now non-empty
}
}
// 这个槽是空的且CAS加锁失败的情况
collide = false;
}
// 线程对应的Cell有值了,且调用longAccumulate之前的CAS失败,之后的逻辑会重新计算探针值继续循环
// 下一次循环不会再进入这个分支,这个分支只进入一次
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
// 线程对应的Cell有值,之前CAS也成功了,那么尝试正常计算并CAS设置这个Cell的value
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
// 线程对应的Cell有值,之前CAS也成功了,但上一个分支条件中本线程对应的CAS失败了
else if (n >= NCPU || cells != as)
// 数组达到长度上限,或cells被其他线程并发修改了
// 清空collide,下一轮循环
collide = false; // At max size or stale
// 对应Cell有值,之前CAS成功,本次CAS失败,且数组长度未达上限,且未被其他线程修改
// 且collide标记为false
// 这个collide标记实际上是扩容前的最后一道防线
else if (!collide)
// 设置冲突标记
collide = true;
// 其他分支全部尝试过了且无效,最终方案加锁扩容
// 如果加锁扩容还失败,那继续循环
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
// 未初始化,且cells未被其他线程扩容,且CAS获取到锁的情况
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
// 获取锁后,再次检查
if (cells == as) {
// 创建length = 2的数组并添加当前值到线程对应的Cell
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
// 解锁
cellsBusy = 0;
}
// 本线程创建成功才跳出
// 如果cells又被其他线程扩容了,那就继续循环
if (init)
break;
}
// 未初始化cells,不巧被其他线程获取锁了,只好CAS修改base
// 如果CAS修改base还失败,那就继续循环
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
复制代码
上边的代码看似复杂,其实核心点只有以下几个:
- 如前述,
Striped64的值由long base和Cell[] cells两个部分组成,其中每个线程映射到cells数组中的一个Cell - 从乐观角度出发,尽量不加锁,资源竞争时尽量使用CAS
- 无冲突时不会进行循环,甚至某些条件下产生冲突也不会循环(Doug Lea考虑很周全)
- 本质上,大部分分支是在处理冲突,真正核心的分支只有2个:
Cell
Striped64为什么要使用base + cells
在并发程度较高时, AtomicLong 使用的CAS操作失败频率也较高,且多了很多不必要的资源消耗,导致性能下降。
而 Striped64 考虑到 AtomicLong 中CAS竞争的资源单一,选择在有冲突时分散竞争资源,为每个线程分配一个 Cell ,让每个资源竞争对应的资源,大幅减少冲突。
LongAdder
由于 Striped64 是 LongAccumulator 、 LongAdder 等的父类,抽出了公共的并发计算处理部分,而未实现子类中特殊的取值部分。
因此 LongAdder 继承 Striped64 时不但实现了累加器所需的方法,还增加了几个取值方法。
核心方法
// 增加值
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
// 乐观情况下,完全无冲突时会使用父类Sriped64.casBase方法,更新base
// 一旦casBase产生冲突,会使得cells不为空,那么每个线程会通过探针值probe找到自己对应的Cell,通过CAS更新其value
// 一旦CAS更新Cell的值出现冲突,那么会使用Striped64.longAccumulate方法更新cells或base的值
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
// 自增
public void increment() {
add(1L);
}
// 自减
public void decrement() {
add(-1L);
}
复制代码
可以看出,核心部分就是分散并发冲突,调用 Striped64 的 longAccumulate 方法。
与 AtomicLong 最大的区别是自增方法都没有返回值。(废话,方法名说得很清楚了)
sum
返回总和,即base及cells数组中所有值的和。
由于未加锁,当遍历求和时其他线程在更新,那么结果可能并不是准确的。
reset
无加锁地将数据重置,包括清零cells中的元素和清零base,这意味着使用方需要确认没有其他线程在更新,否则无法彻底清零。
但是cells数组大小不会变化,元素也没有移除,这意味着重置后复用这个对象将不会再重复之前进行过的扩容过程。
sumThenReset
遍历求和的同时将cells数组中元素的值清零,注意同样未加锁, sum 和 reset 方法存在的被其他线程修改的问题这个方法也同样存在。
其他方法
提供了 longValue 、 doubleValue 等取值方法,核心均是使用 sum 方法。
LongAdder的缺点
正如之前所说, AtomicLong 在set、get时都是直接操作核心的value,时间复杂度是O(1)。
相比之下, LongAdder 有这样一些缺点:
- 没有提供赋值方法,意味着要复用需要调用
reset方法,这个方法的缺点上边已经说了,另外时间复杂度也会比AtomicLong.set高,因为有遍历操作 - 取值方法时间复杂度相对来说也高,因为要进行遍历求和
- 正如作者的描述,占用空间更大,因为使用
@Contended注解避免伪共享
虽然 LongAdder 求和或清空时遍历的cells数组长度最大值为CPU核数,其实也并不大,但是考虑到并发累加器的应用场景,如果调用次数过多比例过高对性能的影响还是会体现出来的。
AtomicLong和LongAdder的比较
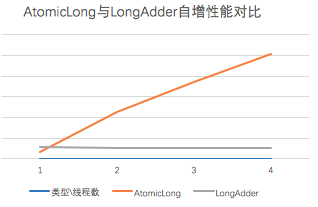
LongAdder 更适合高并发、写操作远多于读操作的场景。这也是Doug Lea在类说明中描述的,“用于统计而不是用于控制同步时”预期效率会比 AtomicLong 高很多。
AtomicLong 更适合读远多于写,或线程数不多的场景。
在低并发情况下, AtomicLong 的读写效率跟 LongAdder 基本相同,甚至略优于 LongAdder ;
AtomicLong 的读效率总是优于 LongAdder 的;
但 AtomicLong 的写效率会随着竞争的激烈程度线性降低,但 LongAdder 的写效率几乎可以保持地很好。
总的来说,两者的应用场景还是非常不一样的,不应当将 LongAdder 当做 AtomicLong 来使用。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

