Dubbo负载均衡、容错、高可用
- Random LoadBalance(默认) 随机,按权重设置随机概率。
在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整 提供者权重。 - RoundRobin LoadBalance 轮询,按公约后的权重设置轮询比率。
存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久 之,所有请求都卡在调到第二台上。 - LeastActive LoadBalance 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。 - ConsistentHash LoadBalance 一致性 Hash,相同参数的请求总是发到同一提供者。
当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。 缺省只对第一个参数 Hash,如果要修改,请配置 缺省用 160 份虚拟节点,如果要修改,请配置
1.2配置
1.2.1xml方式
可以在提供方配置也可以在消费方配置. 有如下几种,任选一种
- 服务端服务级别
<dubbo:service interface="..." loadbalance="roundrobin" /> 复制代码
- 服务端方法级别
<dubbo:service interface="...">
<dubbo:method name="..." loadbalance="roundrobin"/>
</dubbo:service>
复制代码
- 客户端服务级别
<dubbo:reference interface="..." loadbalance="roundrobin" /> 复制代码
- 客户端方法级别
<dubbo:reference interface="...">
<dubbo:method name="..." loadbalance="roundrobin"/>
</dubbo:reference>
复制代码
1.2.2注解方式
- 提供者配置
@Service(loadbalance = "")
public class UserServiceImpl implements UserService {}
复制代码
- 消费者配置,通过loadbalance属性
@Reference(loadbalance = "roundrobin ") private UserService userService; 复制代码
2.集群容错
2.1集群中容错类型
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
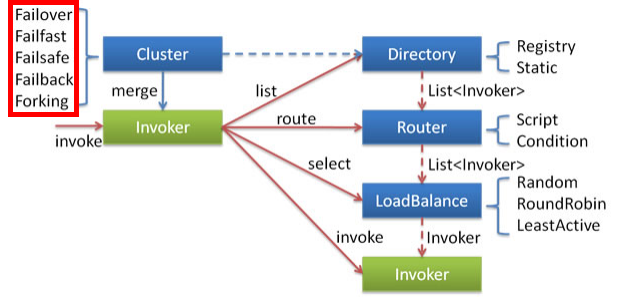
2.2Dubbo中容错策略
-
Failover Cluster
失败自动切换,当出现失败,重试其它服务器. 通常用于读操作,但重试会带来更长延迟。可通 过 retries="2" 来设置重试次数(不含第一次)。 可以在提供方配置也可以在消费方配置
//提供方配置 <dubbo:service retries="2" /> //消费方配置 <dubbo:reference retries="2" /> 复制代码
- Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。 - Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。 - Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。 - Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。 可通过 forks="2" 来设置最大并行数。 - Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错 [2]。通常用于通知所有提供者更新缓存或日志等本地 资源信息。
2.3配置
2.3.1xml方式
- 服务提供方
<dubbo:service cluster="failsafe" /> 复制代码
- 服务消费方
<dubbo:reference cluster="failsafe" /> 复制代码
2.3.2注解方式
- 服务提供方
@Service(cluster = "failsafe") 复制代码
- 服务消费方
@Reference(cluster = "failsafe") 复制代码
3.SpringBoot整合熔断器Hystrix
3.1Hystrix概述
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,Hystrix 能使你的系统在出现依赖服务失效的时 候,通过隔离系统所依赖的服务,防止服务级联失败,同时提供失败回退机制,更优雅地应对失效,并使你的系统 能更快地从异常中恢复 .
“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝), 向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的 异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃 至雪崩。
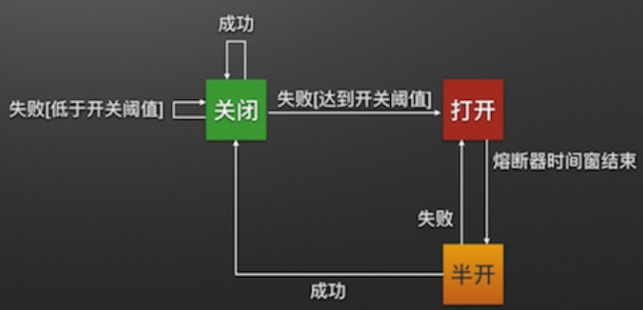
3.2整合Hystrix进行容错
3.2.1提供方
- 在pom.xml添加Hystrix起步依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring‐cloud‐starter‐netflix‐hystrix</artifactId>
</dependency>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring‐cloud‐dependencies</artifactId>
<version>Finchley.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
复制代码
- 在启动类上面开启Hystrix(@EnableHystrix )
@EnableHystrix
@EnableDubbo
@SpringBootApplication
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class,args);
}
}
复制代码
- 在提供的方法上面添加注解@HystrixCommand
@Service
public class UserServiceImpl implements UserService {
/**
* 按照用户id返回所有的收货地址
* @param userId
* @return
*/ @HystrixCommand
public List<Address> findUserAddressList(String userId) {
//模拟dao查询数据库
System.out.println("UserServiceImpl....");
List<Address> list = new ArrayList<Address>();
list.add(new Address(1,"北京","1","张三","12306"));
list.add(new Address(2,"武汉","2","李四","18170"));
return list;
}
}
复制代码
3.2.2消费者
- 在pom.xml添加Hystrix起步依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring‐cloud‐starter‐netflix‐hystrix</artifactId>
</dependency>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring‐cloud‐dependencies</artifactId>
<version>Finchley.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
复制代码
- 在启动类上面开启Hystrix(@EnableHystrix )
@EnableHystrix
@EnableDubbo
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class,args);
}
}
复制代码
- 在调用的方法上面添加注解@HystrixCommand
@RestController
@RequestMapping("/order")
public class OrderController {
@Reference(cluster = "") private UserService userService;
@HystrixCommand(fallbackMethod = "nativeMethod")
@RequestMapping("/save")
public List<Address> save(){
List<Address> list = userService.findUserAddressList("1");
System.out.println(list);
//调用业务...
return list;
}
//当远程方法调用失败,会触发当前方法
public List<Address> nativeMethod(){
List<Address> list = new ArrayList<Address>();
list.add(new Address(1,"默认地址","1","默认收货人","默认电话"));
return list;
}
}
复制代码
4.Zookeeper集群
4.1.Zookeeper集群简介
4.1.1为什么搭建Zookeeper集群
大部分分布式应用需要一个主控、协调器或者控制器来管理物理分布的子进程。目前,大多数都要开发私有的 协调程序,缺乏一个通用机制,协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器,zookeeper提供 通用的分布式锁服务,用以协调分布式应用。所以说zookeeper是分布式应用的协作服务。
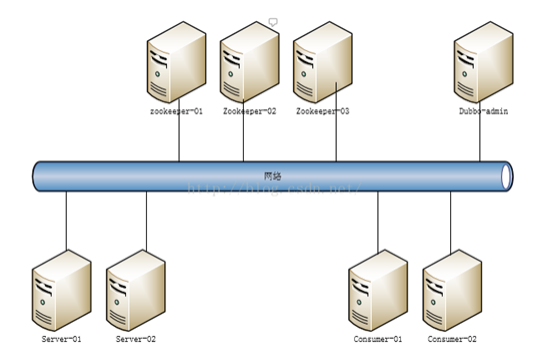
zookeeper作为注册中心,服务器和客户端都要访问,如果有大量的并发,肯定会有等待。所以可以通过 zookeeper集群解决。
下面是zookeeper集群部署结构图:
4.1.2Leader选举
Zookeeper的启动过程中leader选举是非常重要而且最复杂的一个环节。那么什么是leader选举呢? zookeeper为什么需要leader选举呢?zookeeper的leader选举的过程又是什么样子的?
看什么是leader选举。其实这个很好理解,leader选举就像总统选举一样,每人一票,获得多数票的 人就当选为总统了。在zookeeper集群中也是一样,每个节点都会投票,如果某个节点获得超过半数以上的节点的 投票,则该节点就是leader节点了。
4.2搭建Zookeeper集群
4.2.1搭建要求
真实的集群是需要部署在不同的服务器上的,但是在我们测试时同时启动十几个虚拟机内存会吃不消,所以我 们通常会搭建伪集群,也就是把所有的服务都搭建在一台虚拟机上,用端口进行区分。
搭建一个三个节点的Zookeeper集群(伪集群)。
4.2.2准备工作
(1)安装JDK 【步骤略】。
(2)Zookeeper压缩包上传到服务器【也可用docker方式】
(3)将Zookeeper解压,创建data目录 ,将 conf下zoo_sample.cfg 文件改名为 zoo.cfg
(4)建立/usr/local/zookeeper-cluster目录,将解压后的Zookeeper复制到以下三个目录
/usr/local/zookeeper-cluster/zookeeper-1
/usr/local/zookeeper-cluster/zookeeper-2
/usr/local/zookeeper-cluster/zookeeper-3
[root@localhost ~]# mkdir /usr/local/zookeeper‐cluster [root@localhost ~]# cp ‐r zookeeper‐3.4.6 /usr/local/zookeeper‐cluster/zookeeper‐1 [root@localhost ~]# cp ‐r zookeeper‐3.4.6 /usr/local/zookeeper‐cluster/zookeeper‐2 [root@localhost ~]# cp ‐r zookeeper‐3.4.6 /usr/local/zookeeper‐cluster/zookeeper‐3 复制代码
(5) 配置每一个Zookeeper 的dataDir(zoo.cfg) clientPort 分别为2181 2182 2183
- 修改/usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
clientPort=2181 dataDir=/usr/local/zookeeper‐cluster/zookeeper‐1/data 复制代码
- 修改/usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
clientPort=2182 dataDir=/usr/local/zookeeper‐cluster/zookeeper‐2/data 复制代码
- 修改/usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
clientPort=2183 dataDir=/usr/local/zookeeper‐cluster/zookeeper‐3/data 复制代码
4.2.3配置集群
(1)在每个zookeeper的 data 目录下创建一个 myid 文件,内容分别是1、2、3 。这个文件就是记录每个服务器 的ID
‐‐‐‐‐‐‐知识点小贴士‐‐‐‐‐‐ 如果你要创建的文本文件内容比较简单,我们可以通过echo 命令快速创建文件 格式为: echo 内容 >文件名 例如我们为第一个zookeeper指定ID为1,则输入命令 复制代码

(2)在每一个zookeeper 的 zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表。
- 集群服务器IP列表如下
server.1=192.168.25.140:2881:3881 server.2=192.168.25.140:2882:3882 server.3=192.168.25.140:2883:3883 复制代码
解释:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
4.2.4启动集群
(1)启动集群就是分别启动每个实例
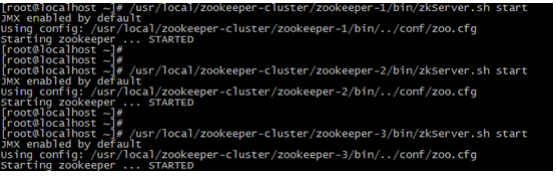
(2)启动后我们查询一下每个实例的运行状态
- 先查询第一个服务, Mode为follower表示是跟随者(从)

- 再查询第二个服务Mod 为leader表示是领导者(主)

- 查询第三个为跟随者(从)

4.2.5模拟集群异常
(1)首先我们先测试如果是从服务器挂掉,会怎么样
- 把3号服务器停掉,观察1号和2号,发现状态并没有变化

由此得出结论,3个节点的集群,从服务器挂掉,集群正常
(2)我们再把1号服务器(从服务器)也停掉,查看2号(主服务器)的状态,发现已经停止运行了。

由此得出结论,3个节点的集群,2个从服务器都挂掉,主服务器也无法运行。因为可运行的机器没有超过集群总数 量的半数。
(3)我们再次把1号服务器启动起来,发现2号服务器又开始正常工作了。而且依然是领导者。

(4)我们把3号服务器也启动起来,把2号服务器停掉(汗~~干嘛?领导挂了?)停掉后观察1号和3号的状态。
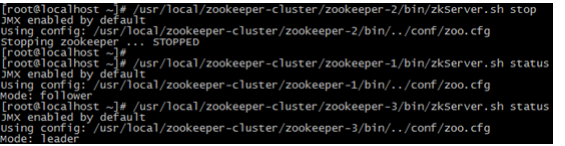
发现新的leader产生了~
由此我们得出结论,当集群中的主服务器挂了,集群中的其他服务器会自动进行选举状态,然后产生新得leader
(5)我们再次测试,当我们把2号服务器重新启动起来(汗~~这是诈尸啊!)启动后,会发生什么?2号服务器会再 次成为新的领导吗?我们看结果
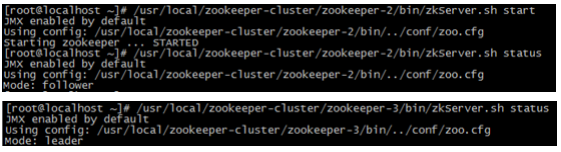
我们会发现,2号服务器启动后依然是跟随者(从服务器),3号服务器依然是领导者(主服务器),没有撼动3号 服务器的领导地位。
由此我们得出结论,当领导者产生后,再次有新服务器加入集群,不会影响到现任领导者。
4.3.Dubbo连接zookeeper集群
- 修改服务提供者和服务调用者的spring 配置文件
<!‐‐ 指定注册中心地址 ‐‐> <dubbo:registry protocol="zookeeper" address="192.168.25.140:2181,192.168.25.140:2182,192.168.25.140:2183"> </dubbo:registry> 复制代码
正文到此结束
- 本文标签: 配置 springboot 幂等 root 实例 https 锁 集群 服务端 管理 分布式锁 启动过程 12306 find src 安装 高可用 缓存 spring DOM ip 开发 cat IO 领导 Hystrix 部署 测试 list tar client map 分布式 目录 App ArrayList pom dependencies 进程 Service 数据 一致性 rand ssl XML dubbo zookeeper 幂等性 时间 注册中心 db 参数 线程 ACE UI 分布式系统 并发 服务器 Docker 负载均衡 开源 安全 id 代码 Netflix 端口 REST 数据库 http
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

