使用DTS打造基于事件驱动的后台架构
分布式服务的数据一致性,永远是后台最头疼的事情,笔者今天的讨论就从这里开始。
业务痛点1 – 多系统耦合
首先来看一个业务需求中的时序图:
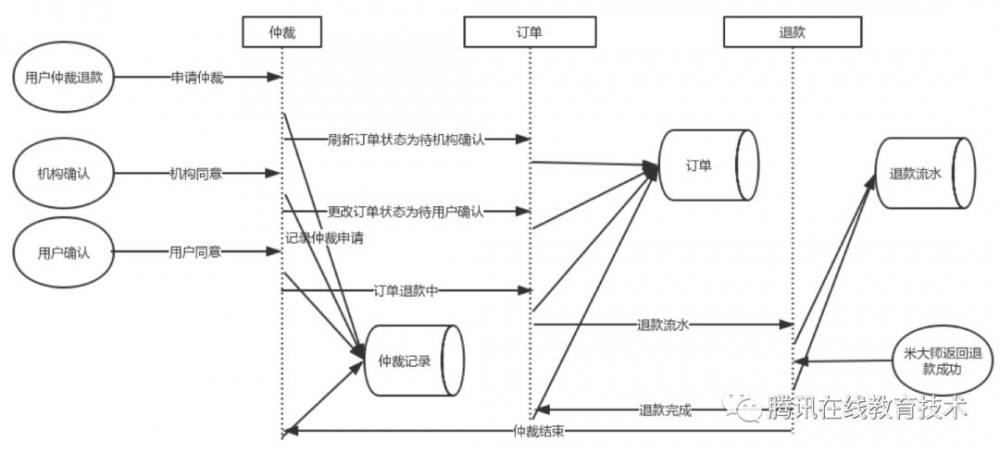
按照这个时序图开发,我们发现有一半的精力花在处理各个微服务之间的数据同步,也就是说代码中充斥着为通知其他服务更新数据而需执行的rpc调用。
上述系统实现明显不利于后期维护。当在某个服务增加一个接口的时候,很无奈的要把上述的调用也都调用一遍,如果不小心漏了或者rpc失败了,那么线上就会出现系统间的数据不一致。为了解决数据不一致问题,我们又花了大量的精力来写各种数据对账脚本,希望能保证各服务数据一致。
为了实现服务间解耦,服务架构应该如下图所示:
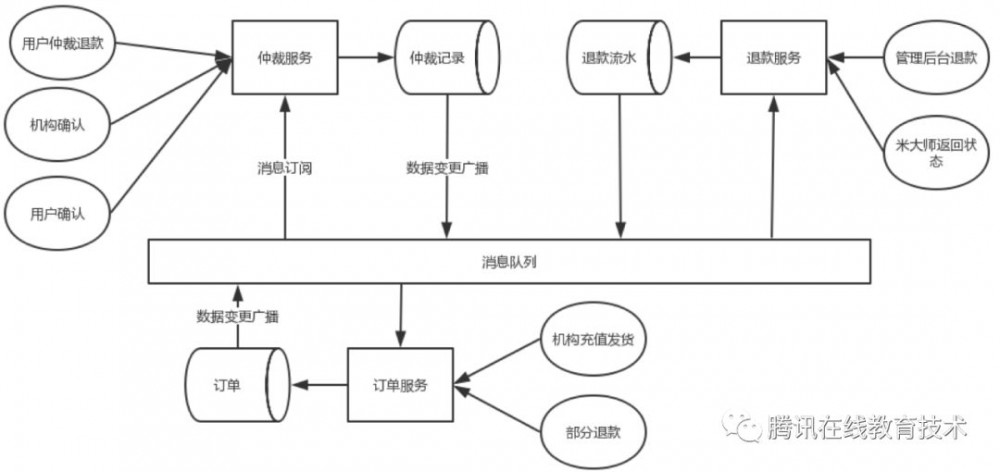
每个服务应该只需要完成自己负责的数据的增删改,然后使用消息队列把数据变更事件通知给其他业务服务,由订阅对应事件的服务自行完成自己内部数据的同步修改,变更事件的通知可以由业务自己完成。当然这种操作多了之后,我们就会想,这个数据变更广播的事情,是不是可以交给统一的服务来做,是不是可以通过第三方服务主动监控数据源的数据变更,做到业务代码0侵入?
业务痛点2 – 缓存数据更新
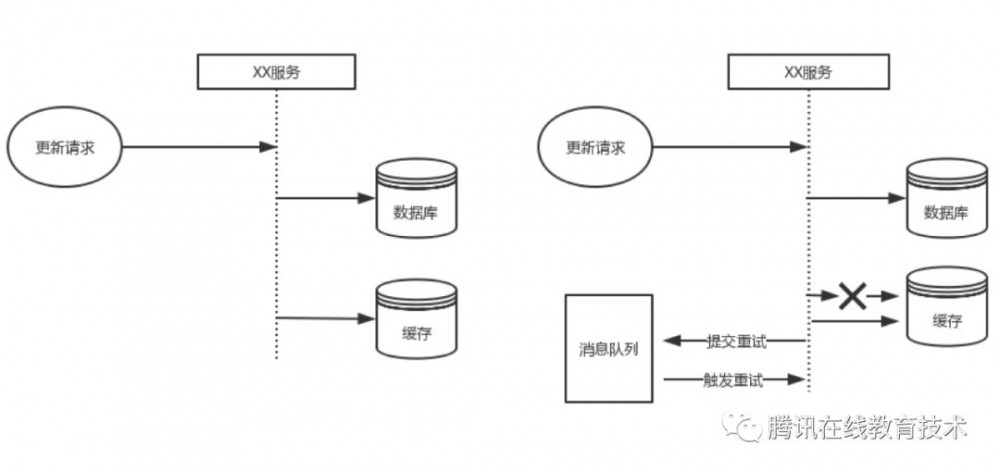
为了满足用户侧的高并发读访问,我们的数据会有一份缓存数据,这个缓存包含但不限于各种kv存储(redis、ckv),es等各种适用于高并发查询场景的缓存组件。
在上述场景下,最原始的思路是双写,但是双写必然会要考虑失败重试,失败重试后还失败的情况,一般会通过消息队列重试。这种方案设计相对复杂,同时对开发和维护人员不友好。
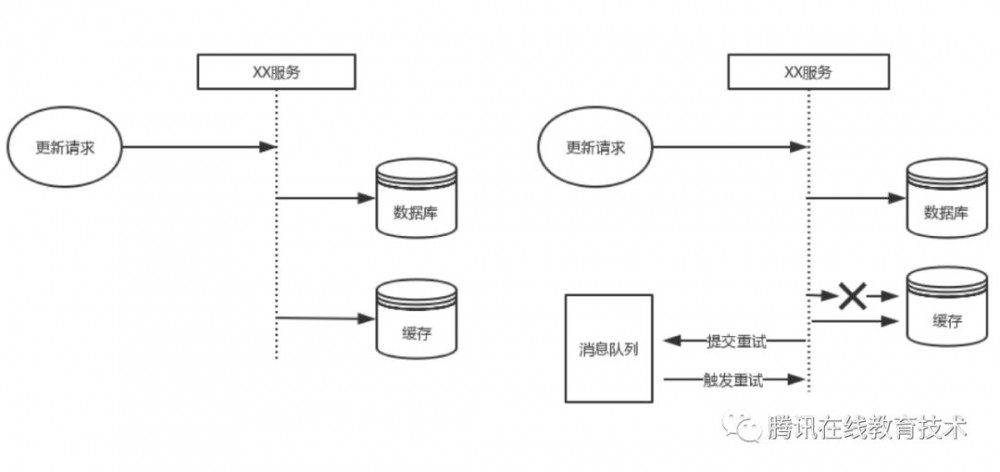
基于上述业务场景,方案设计出现了两种流派,一种是使用脚本做增量、全量扫描的数据同步方案,另外一种是放弃双写直接消息队列异步写的方案。
其实无论是脚本还是消息队列,架构上都已经进入了保证最终一致性的设计思路。这种架构我们关心的是时效性和可靠性,脚本方案一般可靠性高但是时效性差,同时对db造成很大压力;消息队列方案相对靠谱,但是每个访问数据库的地方要同步发个消息,实践起来也是一把辛酸泪。
自然的,我们希望有一套如下图所示的通用缓存结构,业务代码只用操作自己的表,然后数据会自动同步到缓存中。
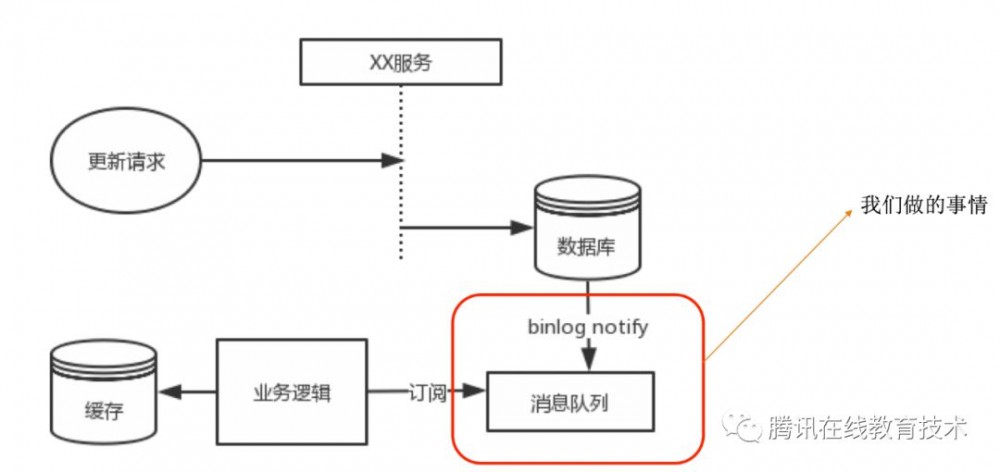
业务痛点3 – 核心数据监控、上报

采用和上述类似的思路,我们之前头痛的关键数据的状态监控和统计上报,可以用同样一套通知方案优雅的解决。
为了实现这套方案,我们首先需要一个靠谱的系统监听数据库数据的变更。数据变更的监听其实可以有两种实现方式:一种是在数据落地时或者数据落地前同步发送消息进行广播,另外一种则是在数据落地之后通过检查数据库的数据变化进行广播。这两种方案都有成熟的解决方案,具体对比如下图:
DB数据变更监听方案对比
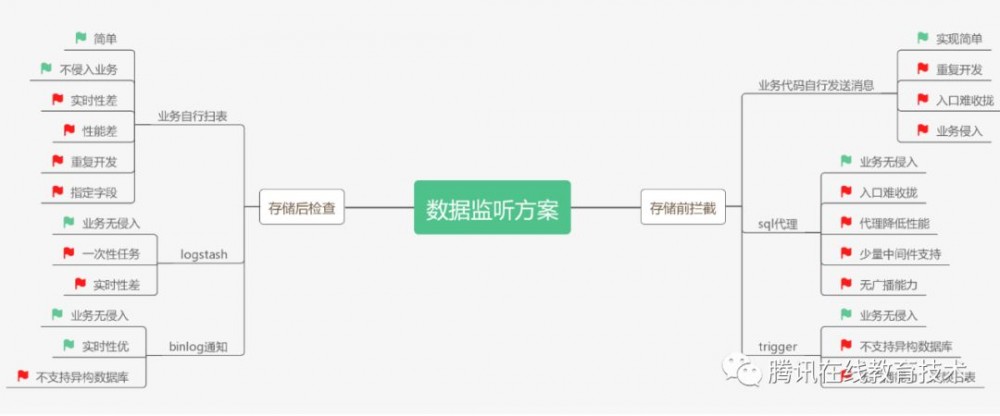
通过比较存储前拦截和存储后广播的各种方案,既能满足性能要求,又能减少开发写代码的方案,就是binlog notify。首先,我们先回顾下什么是binlog?
MySQL 的 Binary Log 介绍
•http://dev.mysql.com/doc/refman/5.5/en/binary-log.html
•http://www.taobaodba.com/html/474 mysqls-binary-log details.html
简单点说:
•mysql的binlog是多文件存储,定位一个LogEvent需要通过binlog filename + binlog position,进行定位
•mysql的binlog数据格式,按照生成的方式,主要分为:statement-based、row-based、mixed。mysql> show variables like 'binlog format'; +---------------+-------+ | Variable name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+ 1 row in set (0.00 sec)
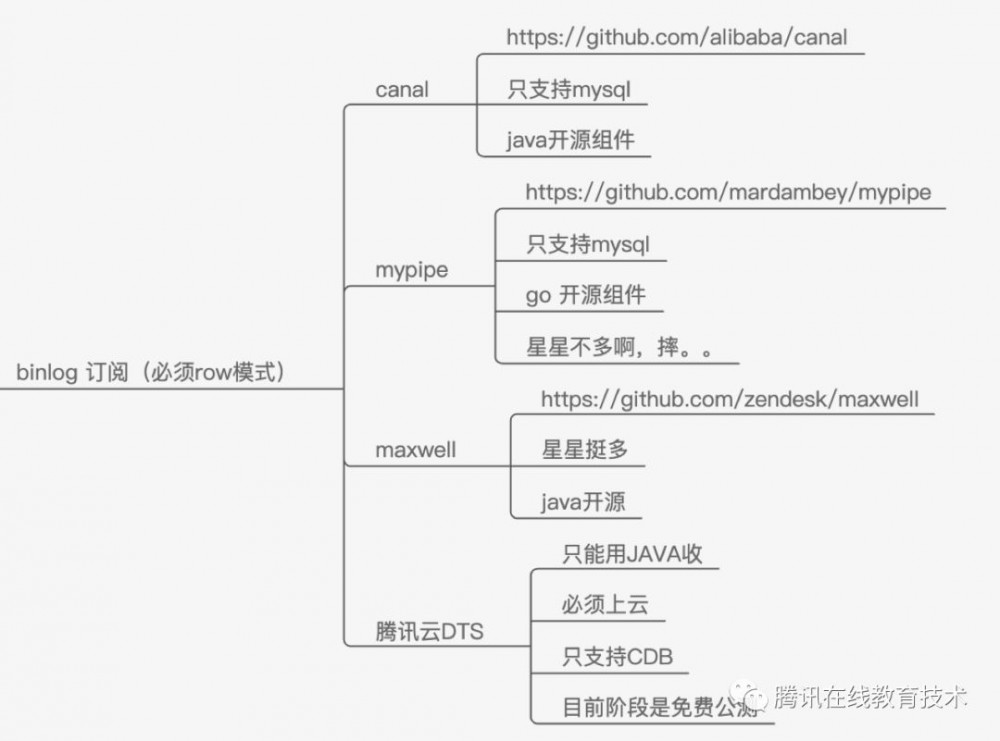
binlog订阅方案业界也有大量成熟的方案,我们挑了其中几个和业务关联比较密切的进行对比,大致的结果如下。
Binlog 订阅方案对比
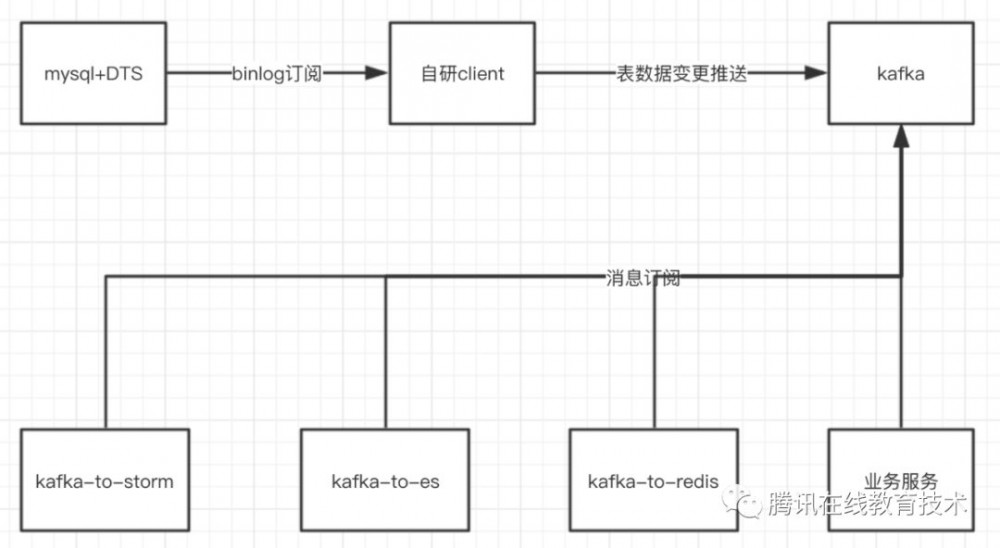
目前我们的服务部署在腾讯云上,腾讯云上提供了数据传输服务DTS能力,其实现原理和业界其他binlog notify组件的实现原理并没有多大的区别。DTS的原理如下图所示:

接入DTS后我们需要做的就是把对应的消息广播到消息队列中,如下图所示:
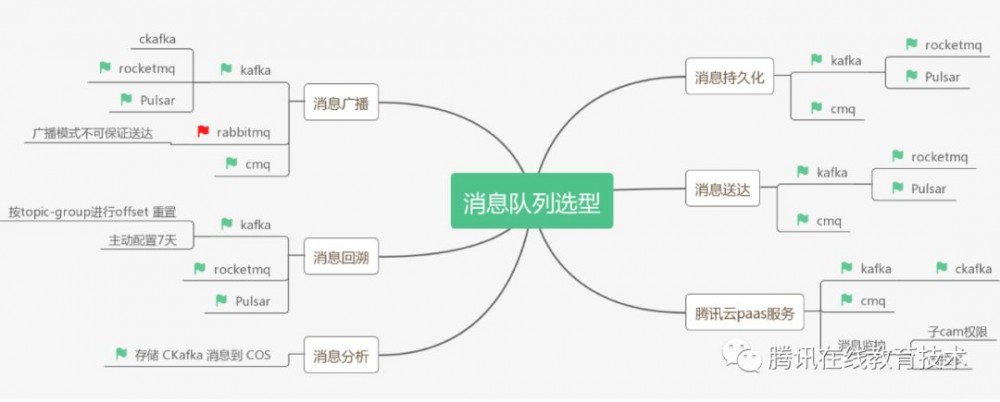
消息队列选型对比
最后我们讲讲为什么选择了kafka作为数据变更广播的通道。市面上可选的主流消息队列大致有下面这些,消息队列按消费者接收消息的方式大致可以分为推送和拉取两种方式:
Push模式代表是rabbitmq:
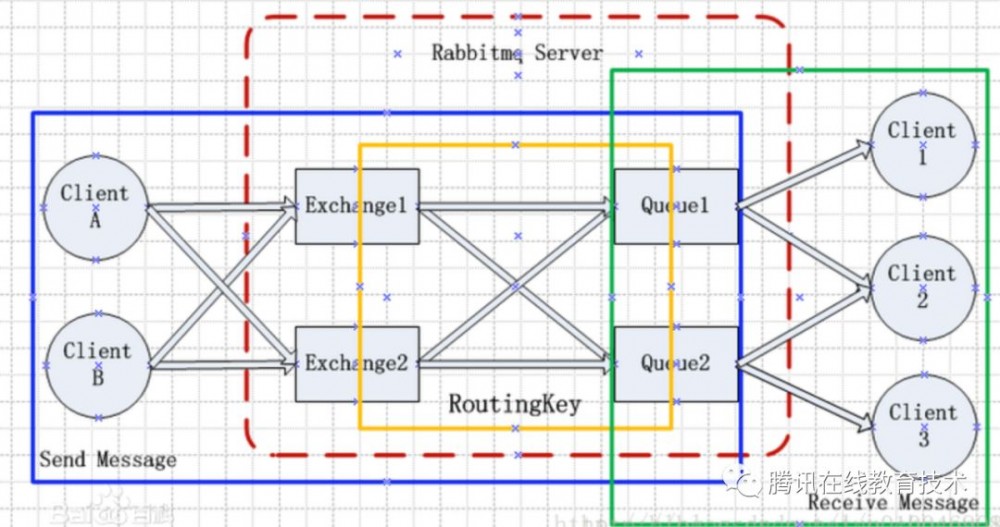
rabbitmq采用push模式广播,在client不在线的情况下会收不到消息,因此不适合作为我们消息队列的备选。
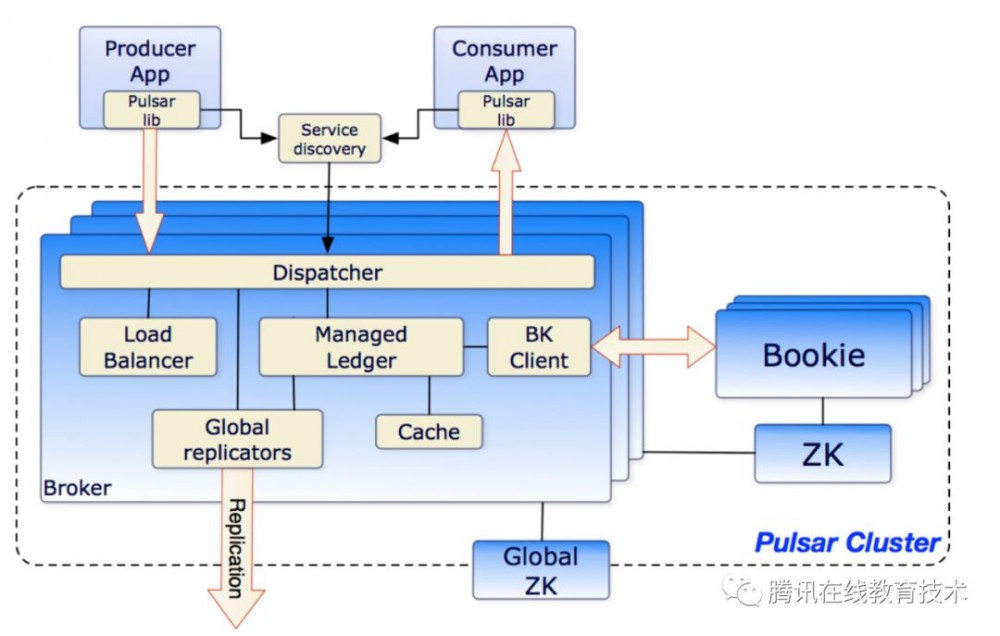
PULL模式的代表是kafka,下面是kafka的大致架构和原理:
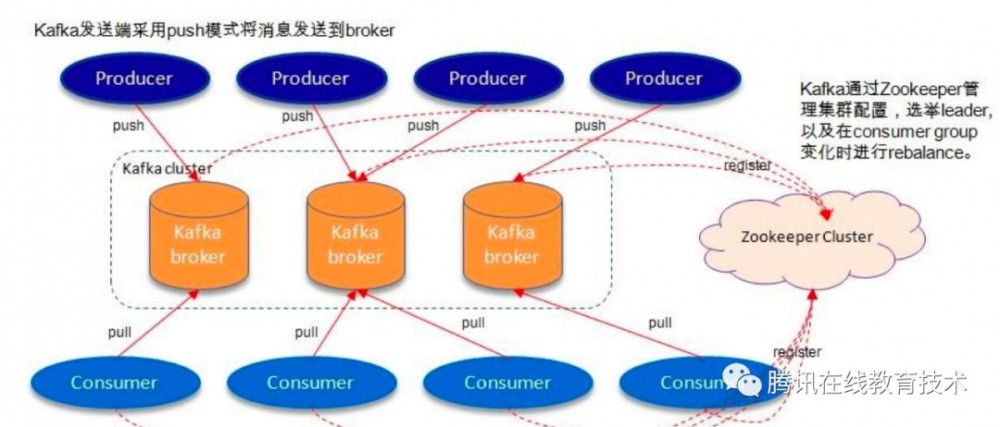
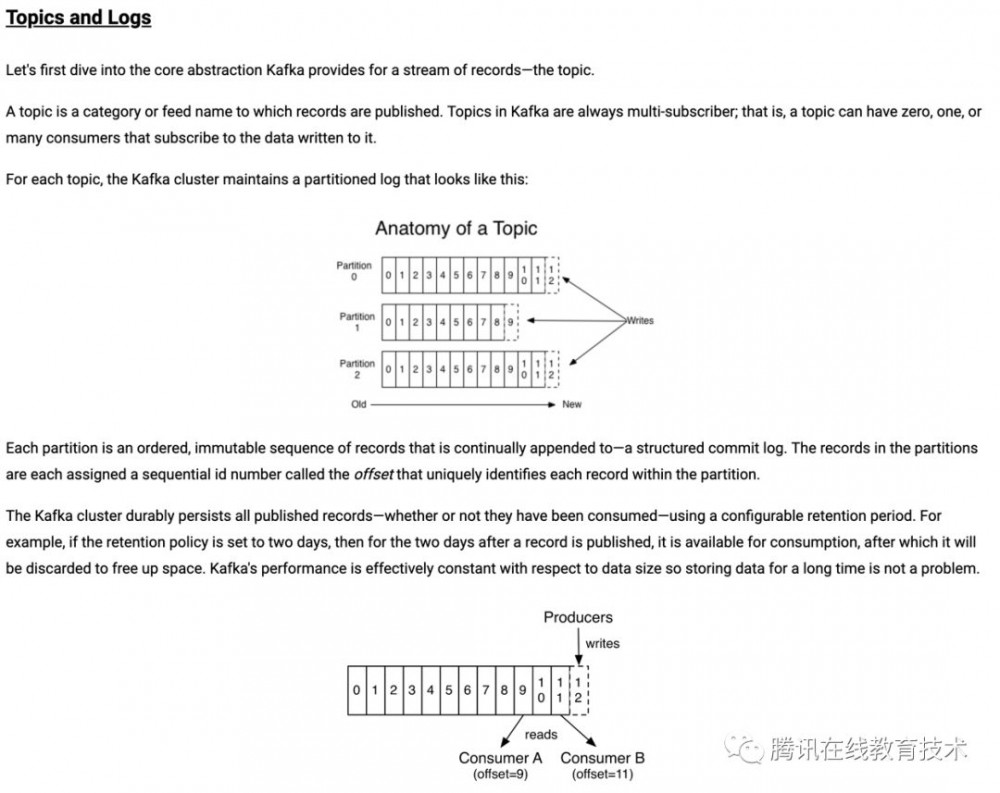
kafka采用的是数据直接落盘的模式,client根据各自的offset偏移量去对应的分区中拉取数据,简单可靠。和kafka类似的有消息中间件有rocketmq、pulsar。rocketmq在kafka类似架构的基础上,去掉了zookeeper,使用部分内存队列,优化了文件存储,对比如下:

总的来说在我们简单的消息广播使用模式下,kafka和rocketmq区别不大。
pulsar和kafka对比,最大的区别是存储自成集群。
基于我们业务使用的是腾讯云,所以上述组件我们一个都没选,而是选了腾讯云的Ckafka。Ckafka组件原理和kafka是一样的,其 通信协议也和kafka的0.10.x的一样 ,在kafka基础能力之上增强了监控和告警,以及存储CKafka消息到COS能力。其组件原理可以按kafka来理解。
业务体验
接入DTS后,我们花了两天时间改造了一个业务功能,大致如下的架构:
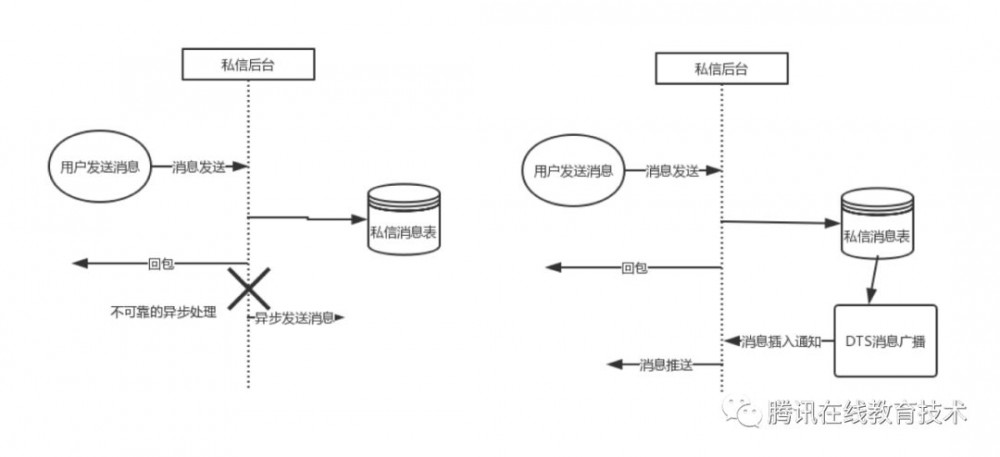
业务侧为了使用方便,也封装了简单的api,从此开发同步数据变得简单起来。
总结
通过数据变更通知系统的引入,我们后台的架构从简单的数据同步读写逐渐往事件驱动的方向演进,在一定程度上解决了长期困扰后台开发的多数据源数据不一致的问题,同时也实现了用户增删改查操作和后台存储运算逻辑的解耦,让需求迭代变得更快速和简单。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

