Maven学习笔记
maven学习笔记
先生,您在写代码吗? 不,我们正在完成一项伟大的工程。
前言
在刚学maven时,我就把maven当作一个引入jar包的工具而已,以前是自己下载jar包,现在是只用在pom文件中填写相应的坐标就可以了。除此之外当我们需要使用的jar包依赖于另一个jar包时,maven会自动帮我们引入适用的版本。这就避免了我们自己下jar包,然后版本不匹配的问题。除此之外,我还模糊的知道一些maven的聚合和继承,之后在接手项目的时候还是吃了的大亏。于是打算重新学习一下maven。
maven是什么?
Apache Maven is a software project management and comprehension tool. Based on the concept of a project object model (POM), Maven can manage a project's build, reporting and documentation from a central piece of information.
comprehension: the ability to understand something 理解力
maven是一种软件项目管理和理解的工具。基于项目对象模型的概念。
但是在后面的what is maven? 我看到这么一句话:
We hope that we have created something that will make the day-to-day work of Java developers easier and generally help with the comprehension of any Java-based project.
为什么能够帮助开发人员理解工程?
Maven约定了目录架构
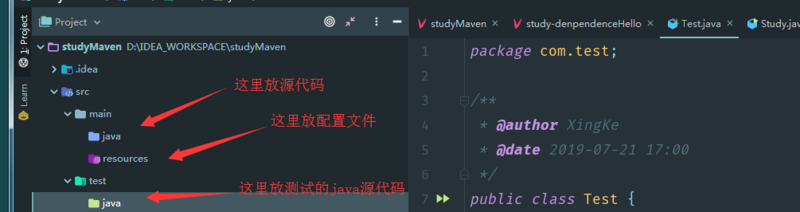
如果你在java中放配置文件,很可能会报找不到文件的异常。
但是我就是想在java这个文件夹中放配置文件,该怎么办呢? 你需要在pom文件中声明一下
<build>
<!--配置可在rc/main/java文件夹下编译出xml文件-->
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>
Maven的定位
多数博客或者视频都将maven定义为自动化构建工具。
那什么是自动化构建工具呢?
我们首先来解释构建:
-
-
编译
- 将java源文件变成字节码,交给JVM去执行
-
部署
- 一个BS项目最终运行的并不是动态web工程本身,而是这个动态web工程“编译的结果”
-
-
构建各个过程的步骤:
- 清理: 将以前编译得到的旧字节码删除掉
- 编译: 将java源代码变成字节码
- 测试: 执行test文件夹中的测试程序
- 报告: 显示测试程序执行的结果
- 打包: 动态Web工程打成war包,Java工程打成jar包
- 安装: Maven的特定概念---将打包得到的文件复制到"仓库"中指定的位置
- 部署: 将动态Web工程生成的war包复制到Servlet容器中指定的目录下,使其可以运行
-
自动化构建,其实上述步骤,在elipse和IDEA中也可以完成,只不过没那么标准。既然IDE已经可以完成这些工作了,那么还要maven干什么呢?
日常开发中,以下几个步骤是我们经常走的:
- 编译
- 打包
- 部署
- 测试
这几个步骤是程式化的,没有太大的变数或者说根本就没有变数。程序员们很希望从这些重复的工作中脱身出来,将这些重复的工作交给工具去做。此时Maven的意义就体现出来了,它可以自动的从构建过程中的起点一直执行到终点。
maven的核心概念
- POM
- 坐标
- 依赖
- 仓库
- 生命周期/插件/目标
- 继承
- 聚合
POM
POM: a project object model.项目对象模型
对这个概念老实说,我并没有很深的理解,或者说我并不理解项目对象模型的意思。
有资料说项目对象模型就是将Java工程的相关信息封装为对象便于操作和管理的模型。
这个解释的稍微让人那么容易那么一点。
学习Maven就是学习pom.xml文件中的配置
坐标
坐标这个概念我觉得和依赖结合起来解释会更好,在没有Maven之前,我们引入jar包的方式就是先下载,然后在复制在类文件路径下,你的项目需要的jar包,在Maven看来就是你的项目依赖于某些jar包,pom.xml文件中填写对应jar包的位置,就可以引入对应的jar包
使用如下三个向量在 Maven 的仓库中唯一的确定一个 Maven 工程。
[1] groupid:公司或组织的域名倒序+当前项目名称
[2] artifactId:当前项目的模块名称
[3] version:当前模块的版本
<groupId>com.atguigu.maven</groupId>
<artifactId>Hello</artifactId>
<version>0.0.1-SNAPSHOT</version>
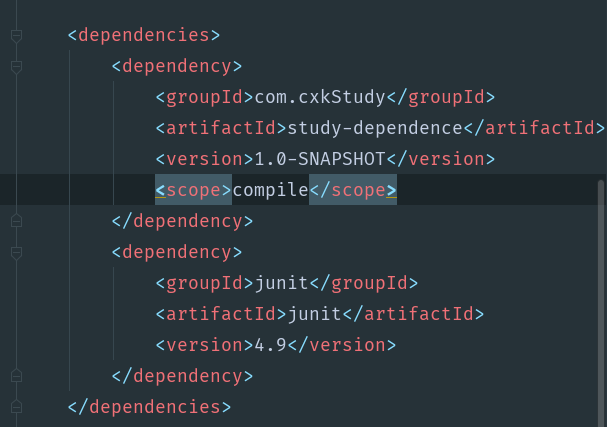
其实引入对象的依赖非常的简单,我们只用去Maven的中央仓库,输入jar包的名字,选择你需要的版本,然后将复制仓库给出的依赖,粘贴在pom.xml文件中的dependencies标签下就可以了.
步骤如下:
百度搜索Maven
进入之后
比如说我想要Spring-test的jar包
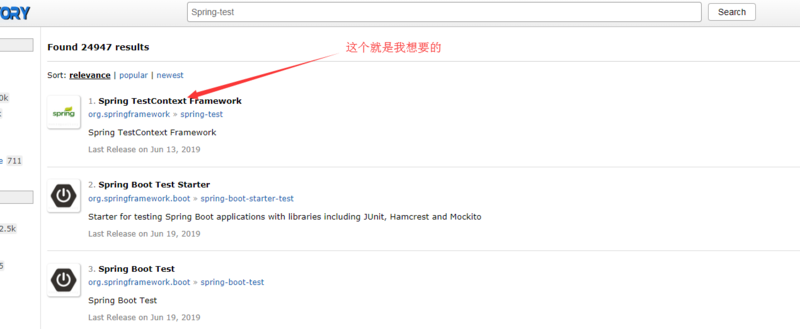
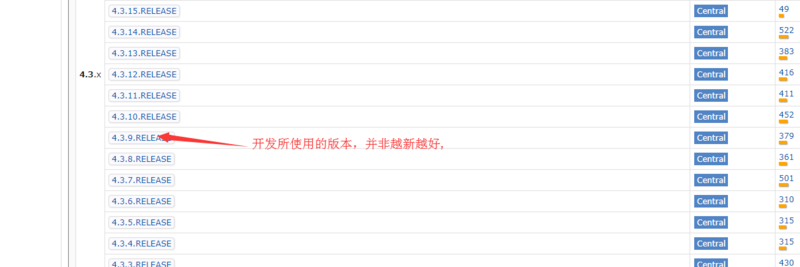
然后选择对应的版本:
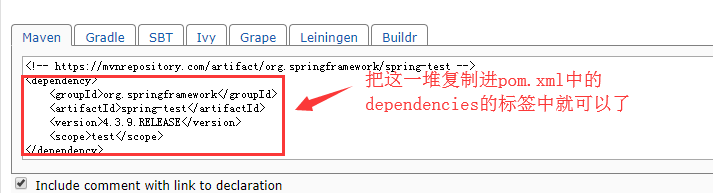
仓库
仓库可以理解为存放jar包的地方。
- 仓库的分类
- 本地仓库:当前电脑上的部署的仓库目录,为当前电脑上的所有Maven工程服务
-
远程仓库:
(1) 私服: 搭建在局域网环境中,为局域网范围内的所有Maven工程服务 (2) 中央仓库: 架设在Internet上,为全世界范围内所有的Maven工程服务。 (3) 中央仓库镜像: 为了分担中央仓库的流量,提升用户的访问速度。
使用properties标签内自定义标签统一声明版本号
生命周期/插件/目标
什么是Mavende生命周期?
Maven 生命周期定义了各个构建环节的执行顺序,有了这个清单,Maven 就可以自动化的执行构建命 令了。
Maven有三套互相独立的生命周期:
①Clean Lifecycle 在进行真正的构建之前进行一些清理工作
②Default Lifecycle 构建的核心部分,编译,测试,打包,安装,部署等等。
③Site Lifecycle 生成项目报告,站点,发布站点。
它们是相互独立的,你可以仅仅调用 clean 来清理工作目录,仅仅调用 site 来生成站点。当然你也可以
直接运行 mvn clean install site 运行所有这三套生命周期。
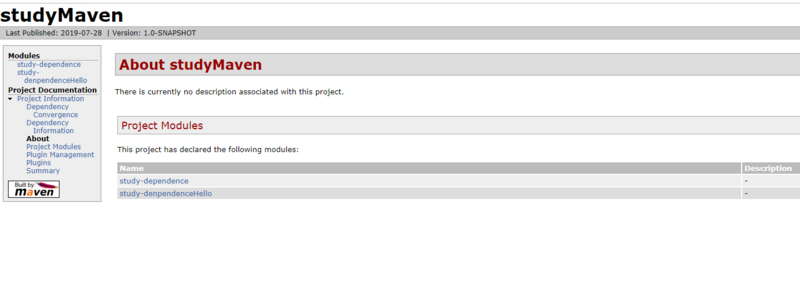
这个生成站点的意思就是: 在本地生成有关你项目的相关信息。
长这个样子:
Clean生命周期:
Clean 生命周期一共包含了三个阶段:
1 pre-clean 执行一些需要在 clean 之前完成的工作
2 clean 移除所有上一次构建生成的文件
3 post-clean 执行一些需要在 clean 之后立刻完成的工作
Site生命周期
1 pre-site 执行一些需要在生成站点文档之前完成的工作 2 site 生成项目的站点文档 3 post-site 执行一些需要在生成站点文档之后完成的工作,并且为部署做准备 4 site-deploy 将生成的站点文档部署到特定的服务器上 这里经常用到的是 site 阶段和 site-deploy 阶段,用以生成和发布 Maven 站点,这可是 Maven 相当强大的功能,Manager 比较喜欢,文档及统计数据自动生成,很好看。
Default 生命周期是 Maven 生命周期中最重要的一个,绝大部分工作都发生在这个生命周期中。这里,
只解释一些比较重要和常用的阶段:
validate
generate-sources
process-sources
generate-resources
process-resources 复制并处理资源文件,至目标目录,准备打包。
compile 编译项目的源代码。
process-classes
generate-test-sources
process-test-sources
generate-test-resources
process-test-resources 复制并处理资源文件,至目标测试目录。
test-compile 编译测试源代码。
process-test-classes
test 使用合适的单元测试框架运行测试。这些测试代码不会被打包或部署。
prepare-package
package 接受编译好的代码,打包成可发布的格式,如 JAR 。
pre-integration-test
integration-test
post-integration-test
verify
install 将包安装至本地仓库,以让其它项目依赖。
deploy 将最终的包复制到远程的仓库,以让其它开发人员与项目共享
- maven生命周期(lifecycle)由各个阶段组成,每个阶段由maven的插件plugin来执行完成。
- 当我们执行的maven命令需要用到某些插件时,Maven的核心程序会首先到本地仓库中查找
- 本地仓库的默认位置: 可以在配置文件中指定
我查的资料是
依赖
①complie
- 对主程序是否有效:有效
- 对测试程序是否有效: 有效
- 是否参与打包: 参与
- 是否参与部署: 参与
- 典型例子: Spring-core
②test
- 对主程序是否有效: 无效
- 对测试程序是否有效: 有效
- 是否参与打包: 不参与
- 是否参与部署: 不参与
- 典型例子: junit
③provided
- 对主程序是否有效: 有效
- 对测试程序是否有效: 有效
- 是否参与打包: 不参与
- 是否参与部署: 不参与
- 典型例子: servlet-api.jar
依赖传递性
模块A依赖于模块B。
模块B又依赖于C模块
则模块A内会有C模块。
让我们把以上的例子在通俗化一些:
模块C引入了Spring-corejar包, 那么模块C中的Maven依赖就会有以下两个jar包。
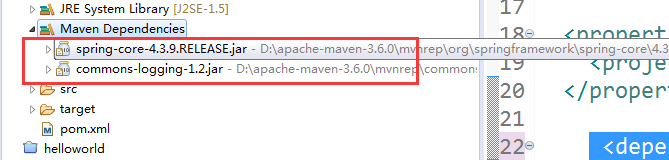
模块A引入模块B,就会顺带把这两个jar包一并引入。

模块A的pom:
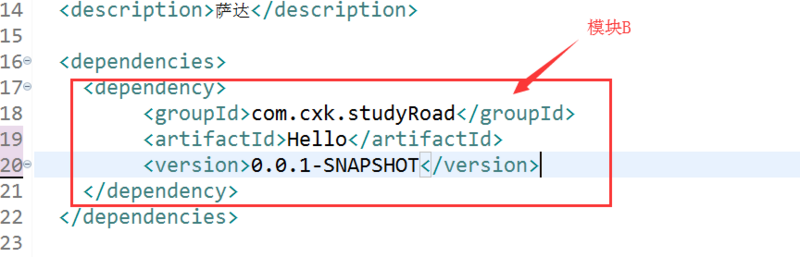
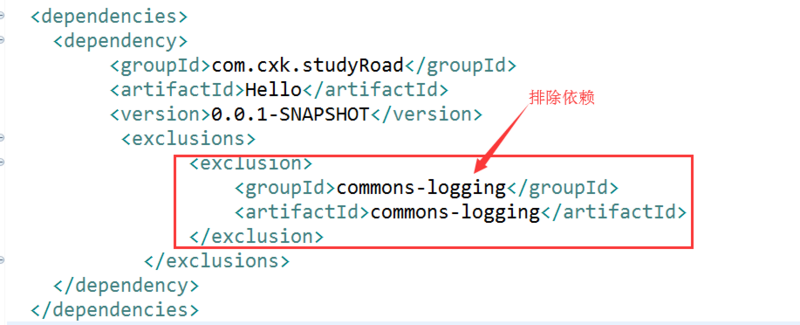
但是现在我并不想要commons-logging这个jar包该怎么办呢?
我们可以排除依赖:
继承
继承可以帮我们做什么?
- 统一管理依赖的版本。
一个典型的例子就是:
现在项目下A、B、C三个模块,三个模块都依赖着不同的Junit的版本,依赖范围为test时,依赖又不能传递过来,但是我们希望能够统一Junit版本,可能有的人自然会想到,你让A、B、C模块pom中的Junit依赖版本写一致不就行了,这也是个办法。但是maven在设计的时候估计也考虑到了这种情况,就是继承了。
继承该如何使用:
①
首先你需要创建一个maven工程,注意指定打包方式为pom <groupId>com.cxkStudy.maven</groupId> <artifactId>Parent</artifactId> <version>0.0.1-SNAPSHOT</version> <description>学习Maven使用</description> <packaging>pom</packaging>
②
再创建一个maven工程,在该模块中指定它的父工程是谁.
<parent>
<groupId>com.cxkStudy.maven</groupId>
<artifactId>Parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
③
在父项目中确定子模块的位置
<modules>
<module>../studyDenpen</module>
<module>../Hello</module>
</modules>
module标签中填的是相对于父项目的位置。
这也就是聚合了.
为什么要使用聚合?
将多个工程拆分为模块后,需要手动逐个安装到仓库后依赖才能够生效。修改源码后也需要逐个手动进 行 clean 操作。而使用了聚合之后就可以批量进行 Maven 工程的安装、清理工作。
我们可以在父工程里面指定Junit的版本,在子模块使用Junit的时候不写版本就好了。
父工程中执行Junit的版本:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
<scope>test</scope>
</dependency>
</dependencies>
</dependencyManagement>
子模块中引入Junit的时候不指定版本
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
请注意配置继承后,执行安装命令要先安装父工程。
随着我们的项目越来越大,src下面的包会越来越多,我曾经在GitHub下见过一个项目,SRC下面有三十多个包,每个包下面又有很多类。这代码看的我想吐,不是代码写的烂,而是太混杂了,结构不清晰。我们可以将我们的项目根据功能进行拆分,以避免src下出现太多的包。
比如说,我们可以将某一个模块专门用来发布我们写的功能模块,某一个模块放置公共类,某一个模块存放业务代码。这样在结构上会更为清晰,但这只用于比较大的工程,小的工程采用如此的拆分还是得不偿失。
正文到此结束
- 本文标签: src 下载 模型 java IBM API 组织 build 项目管理 id spring 源码 https 管理 XML Developer 生命 希望 部署 目录 测试 git IDE Document 百度 博客 IO 自定义标签 编译 ip 数据 程序员 开发 删除 自动生成 junit 服务器 servlet UI CTO http plugin 单元测试 站点 pom 配置 域名 dependencies 统计 ORM 字节码 web maven 安装 代码 软件 core Logging JVM apache 自动化 description GitHub 插件
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

