Sharding-JDBC:单库分表的实现
前面,我们一共学习了读写分离,垂直拆分,垂直拆分+读写分离。对应的文章分别如下:
Sharding-JDBC:查询量大如何优化?
Sharding-JDBC:垂直拆分怎么做?
通过上面的优化,已经能满足大部分的需求了。只有一种情况需要我们再次进行优化,那就是单表的数量急剧上升,超过了1千万以上,这个时候就要对表进行水平拆分了。
表的水平拆分是什么?
就是将一个表拆分成N个表,就像一块大石头,搬不动,然后切割成10块,这样就能搬的动了。原理是一样的。
除了能够分担数量的压力,同时也能分散读写请求的压力,当然这个得看你的分片算法了,合理的算法才能够让数据分配均匀并提升性能。
今天我们主要讲单库中进行表的拆分,也就是不分库,只分表。
既分库也分表的操作后面再讲,先来一幅图感受下未分表:
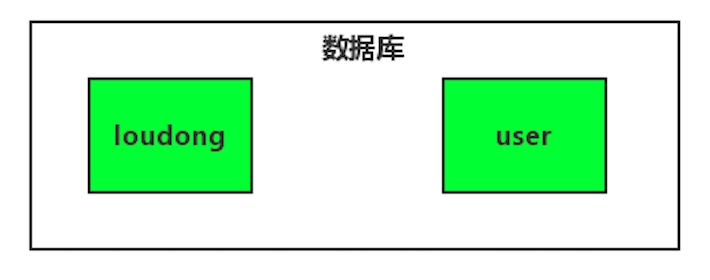
然后再来一张图感受下已分表:
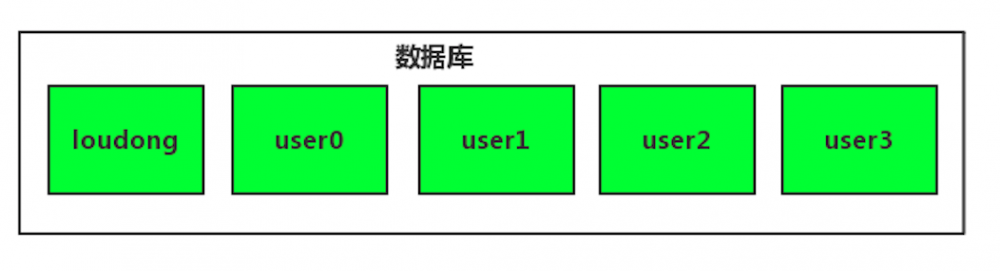
从上图我们可以看出,user表由原来的一个被拆分成了4个,数据会均匀的分布在这3个表中,也就是原来的user=user0+user1+user2+user3。
分表配置
首先我们需要创建4个用户表,如下:
CREATE TABLE `user_0`( id bigint(64) not null, city varchar(20) not null, name varchar(20) not null, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `user_1`( id bigint(64) not null, city varchar(20) not null, name varchar(20) not null, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `user_2`( id bigint(64) not null, city varchar(20) not null, name varchar(20) not null, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `user_3`( id bigint(64) not null, city varchar(20) not null, name varchar(20) not null, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 复制代码
分表的数量你需要根据你的数据量也未来几年的增长来评估。
分表的规则配置:
spring.shardingsphere.datasource.names=master
# 数据源
spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://localhost:3306/ds_0?characterEncoding=utf-8
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
# 分表配置
spring.shardingsphere.sharding.tables.user.actual-data-nodes=master.user_${0..3}
# inline 表达式
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_${id.longValue() % 4}
复制代码
- actual-data-nodes 配置分表信息,这边用的inline表达式,翻译过来就是master.user_0,master.user_1,master.user_2,master.user_3
- inline.sharding-column 分表的字段,这边用id分表
- inline.algorithm-expression 分表算法行表达式,需符合groovy语法,上面的配置就是用id进行取模分片
如果我们有更复杂的分片需求,可以自定义分片算法来实现:
# 自定义分表算法 spring.shardingsphere.sharding.tables.user.table-strategy.standard.sharding-column=id spring.shardingsphere.sharding.tables.user.table-strategy.standard.precise-algorithm-class-name=com.cxytiandi.sharding.algorithm.MyPreciseShardingAlgorithm 复制代码
算法类:
public class MyPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
for (String tableName : availableTargetNames) {
if (tableName.endsWith(shardingValue.getValue() % 4 + "")) {
return tableName;
}
}
throw new IllegalArgumentException();
}
}
复制代码
在doSharding方法中你可以根据参数shardingValue做一些处理,最终返回这条数据需要分片的表名称即可。
除了单列字段分片,还支持多字段分片,大家可以自己去看文档操作一下。
需要分表的进行配置,不需要分表的无需配置,数据库操作代码一行都不用改变。
如果我们要在单库分表的基础上,再做读写分离,同样很简单,只要多配置一个从数据源就可以了,配置如下:
spring.shardingsphere.datasource.names=master,slave
# 主数据源
spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://localhost:3306/ds_0?characterEncoding=utf-8
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
# 从数据源
spring.shardingsphere.datasource.slave.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave.url=jdbc:mysql://localhost:3306/ds_1?characterEncoding=utf-8
spring.shardingsphere.datasource.slave.username=root
spring.shardingsphere.datasource.slave.password=123456
# 分表配置
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds0.user_${0..3}
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_${id.longValue() % 4}
# 读写分离配置
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=master
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=slave
复制代码
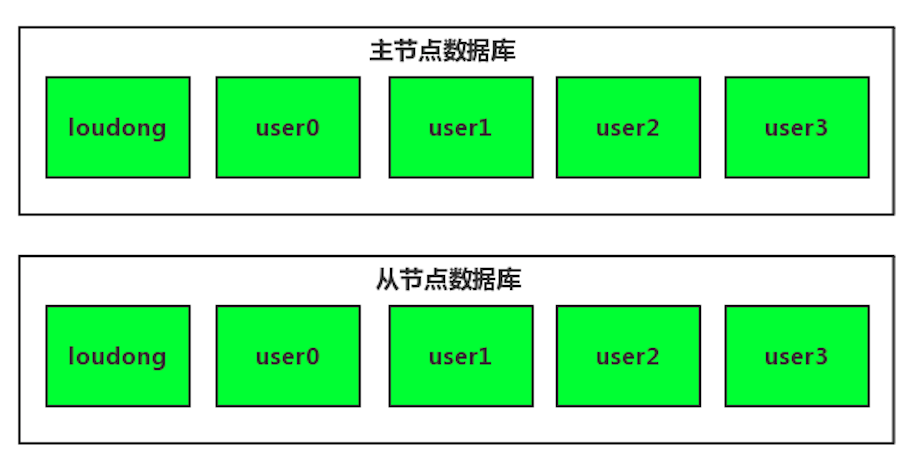
最后
你会发现,到最后这种复杂的分表场景,用框架来解决会非常简单。至少比你自己通过字段去计算路由的表,去汇总查询这种形式要好的多。
源码参考: github.com/yinjihuan/s…
觉得不错的记得关注下哦,给个Star吧!
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

