java并发编程学习之ConcurrentHashMap
之前HashMap中提过,并发的时候,可能造成死循环,那么在多线程中可以用ConcurrentHashMap来避免这一情况。
Segment
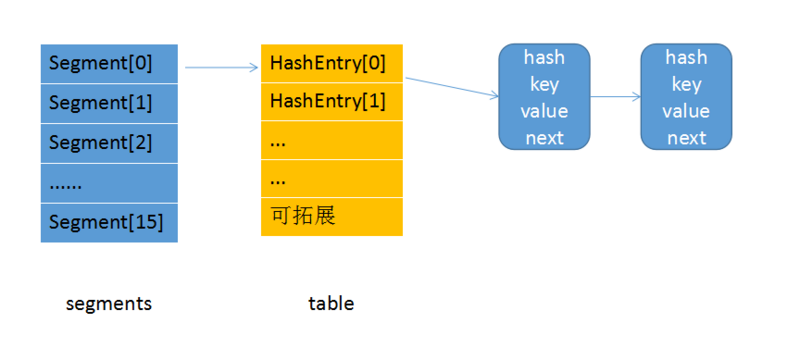
ConcurrentHashMap是由多个Segment组成的,Segment继承了ReentrantLock,每次加锁都是对某个Segment,不会影响其他Segment,达到了锁分离(也叫分段锁)的作用。
每个Segment又包含了HashEntry数组,HashEntry是一个链表。如下图所示:
初始化
initialCapacity:初始容量大小,默认16。
loadFactor:扩容因子,table扩容使用,Segments不扩容。默认0.75,当Segment容量大于initialCapacity*loadFactor时,开始扩容
concurrencyLevel:并发数,默认16,直接影响segmentShift和segmentMask的值,以及Segment的初始化数量。Segment初始化的数量,为最接近且大于的办等于2的N次方的值,比如concurrencyLevel=16,Segment数量为16,concurrencyLevel=17,Segment数量为32。segmentShift的值是这样的,比如Segment是32,相对于2的5次方,那么他的值就是32-5,为27,后面无符号右移27位,也就是取高5位的时候,就是0到31的值,此时Segment的下标也是0到31,取模后对应着每个Segment。segmentMask就是2的n次方-1,这边n是5,用于取模。之前在hashmap的indexFor方法有提过。
初始化的时候,还要初始化第一个Segment,以及Segment中table数组的大小,这边大小是大于等于initialCapacity除以Segment数组的个数,平均分配,最小是2,且是2的N次方。比如initialCapacity是32,concurrencyLevel是16的时候,那么Segment的个数也是16,32除以16,等于2,如果initialCapacity是33,Segment是16,33除以16,取4。
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;//用于高位,判断落在哪个Segment
this.segmentMask = ssize - 1;//用于取模。之前在hashmap的indexFor方法有提过。2的n次方-1
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);//初始化第一个位置的Segment
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];//初始化Segments
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
put方法
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
//无符号右移后取模,落在哪个Segment上面
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
ensureSegment方法
确定落在哪个Segment上,如果为空,就初始化,因为之前就初始化第一个Segment
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
//使用segment[0]的table长度和loadFactor来初始化
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))//cas操作,只能一个设值成功,如果其他成功了,就赋值,并返回
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);//获取Segment的锁
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;//上面是获取Segment取高位的hash,这边是tabel的hash,
HashEntry<K,V> first = entryAt(tab, index);//取到hash位置的数组的表头
for (HashEntry<K,V> e = first;;) {//从头结点遍历
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {//key相同,或者hash值一样
oldValue = e.value;
if (!onlyIfAbsent) {//是否替换
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)//不为空,设置为表头
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);/初始化后放表头
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);// 扩容
else
setEntryAt(tab, index, node);//把新的节点放在tab的index上面
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();//释放锁
}
return oldValue;
}
scanAndLockForPut方法
尝试获取锁,没获取到先初始化node
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);//获取hash后的头结点,有存在null的情况
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock()) {//这个put方法先尝试获取,获取不到,这边while循环尝试获取
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {//结点为空的时候
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);//初始化node
retries = 0;
}
else if (key.equals(e.key))//头结点不为空的时候
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {//超过重试次数,直接进入阻塞队列等待锁
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {//不等于first,就是已经有其他节点进入
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
rehash方法,扩容,对table扩容
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;//左移,之前的2倍
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // 为空,没有后面的节点,直接给新数组
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
//因为数组是2倍的扩容,所以重新hash后,要么落在跟之前索引一样的位置,要么就是加上oldCapacity 的值,
//比如容量是2,扩容4,现在hash是2,4,6,10,14那么后面3个都是除4余2,可以直接复制
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {//hash不一样,重新
lastIdx = k;
lastRun = last;
}
}
//执行上面,就是lastRun是6,10,14
newTable[lastIdx] = lastRun;//上面
// Clone remaining nodes克隆的时候,碰到lastrun,直接根据所以给值,但是前面有可能的索引跟lastrun一样,比如2
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);//加入到头结点
newTable[nodeIndex] = node;
table = newTable;
}
get方法
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&//找到Segment,逻辑同put
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);//找到table,逻辑同put
e != null; e = e.next) {//遍历table
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

