图数据库 Nebula Graph 的数据模型和系统架构设计
Nebula Graph:一个开源的分布式图数据库。作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,而且能够提供极高的服务可用性和数据安全性。
本篇主要介绍 Nebula Graph 的数据模型和系统架构设计。
有向属性图 DirectedPropertyGraph
Nebula Graph 采用易理解的有向属性图来建模,也就是说,在逻辑上,图由两种图元素构成:顶点和边。
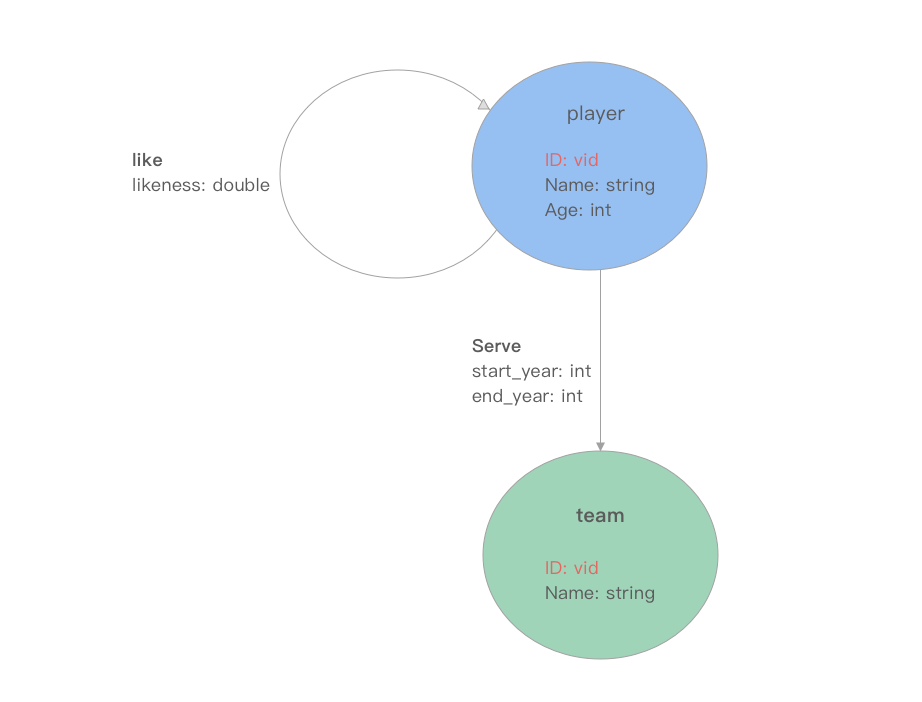
顶点 Vertex
在 Nebula Graph 中顶点由标签 tag 和对应 tag 的属性组构成, tag 代表顶点的类型,属性组代表 tag 拥有的一种或多种属性。一个顶点必须至少有一种类型,即标签,也可以有多种类型。每种标签有一组相对应的属性,我们称之为 schema 。
如上图所示,有两种 tag 顶点:player 和 team。player 的 schema 有三种属性 ID (vid), Name (sting)和 Age (int);team 的 schema 有两种属性 ID (vid)和 Name (string)。
和 Mysql 一样,Nebula Graph 是一种强 schema 的数据库,属性的名称和数据类型都是在数据写入前确定的。
边 Edge
在 Nebula Graph 中边由类型和边属性构成,而 Nebula Graph 中边均是有向边,有向边表明一个顶点( 起点 src )指向另一个顶点( 终点 dst )的 关联关系 。此外,在 Nebula Graph 中我们将边类型称为 edgetype ,每一条边 只有一种 edgetype ,每种 edgetype 相应定义了这种边上属性的 schema 。
回到上面的图例,图中有两种类型的边,一种为 player 指向 player 的 like 关系,属性为** likeness (double);另一种为 player 指向 team 的 serve** 关系,两个属性分别为 start_year (int) 和 end_year (int)。
需要说明的是,起点1 和终点2 之间,可以同时存在多条相同或者不同类型的边。
图分割 GraphPartition
由于超大规模关系网络的节点数量高达百亿到千亿,而边的数量更会高达万亿,即使仅存储点和边两者也远大于一般服务器的容量。因此需要有方法将图元素切割,并存储在不同逻辑分片 partition 上。Nebula Graph 采用边分割的方式,默认的分片策略为 哈希散列 ,partition 数量为静态设置并不可更改。
数据模型 DataModel
在 Nebula Graph 中,每个顶点被建模为一个 key-value ,根据其 vertexID(或简称 vid)哈希散列后,存储到对应的 partition 上。

一条逻辑意义上的边,在 Nebula Graph 中将会被建模为两个独立的 key-value ,分别称为 out-key 和 in-key 。out-key 与这条边所对应的起点存储在同一个 partition 上,in-key 与这条边所对应的终点存储在同一个 partition 上。
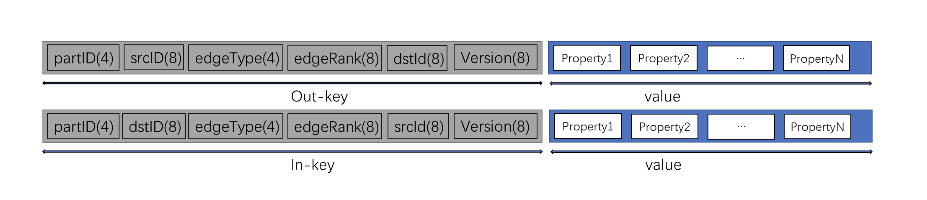
关于数据模型的详细设计会在后续的系列文章中介绍。
系统架构Architecture
Nebula Graph 包括四个主要的功能模块,分别是 存储层 、 元数据服务 、 计算层 和 客户端 。<br />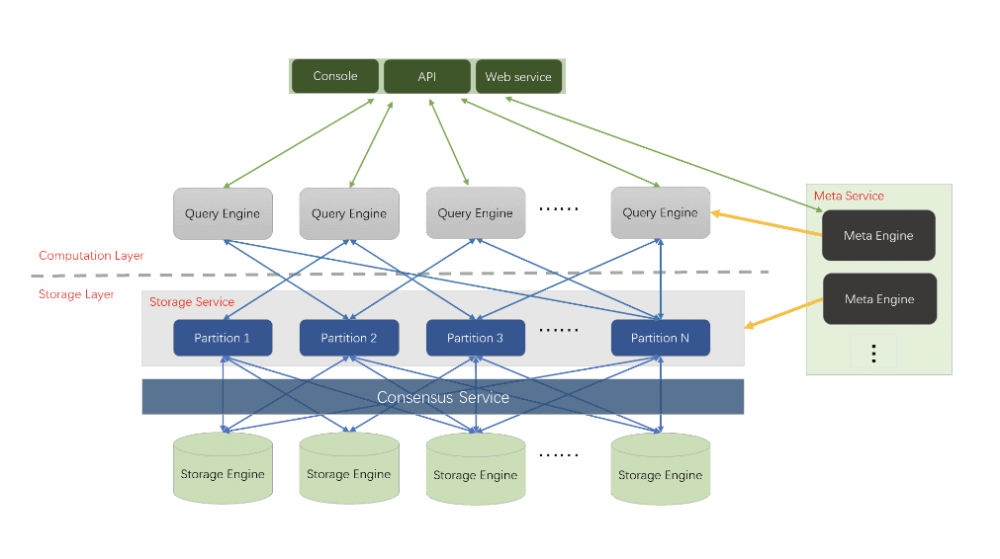
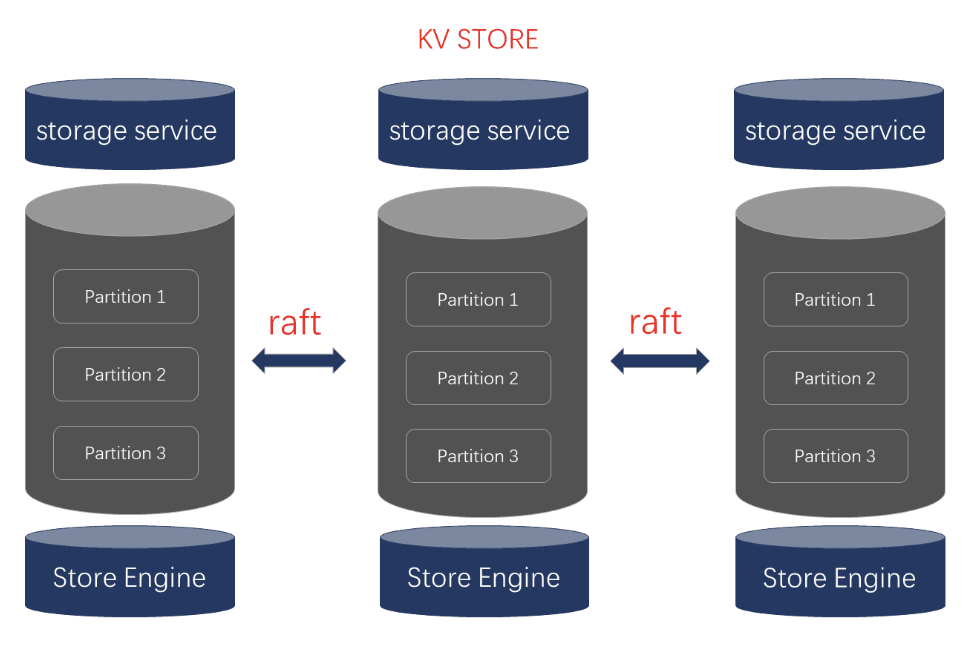
存储层 Storage
在 Nebula Graph 中存储层对应进程是 nebula-storaged ,其核心为基于 Raft(用来管理日志复制的一致性算法) 协议的分布式 Key-valueStorage 。目前支持的主要存储引擎为「Rocksdb」和「HBase」。Raft 协议通过 leader/follower 的方式,来保持数据之间的一致性。Nebula Storage 主要增加了以下功能和优化:
Raft group throughput leader/follower
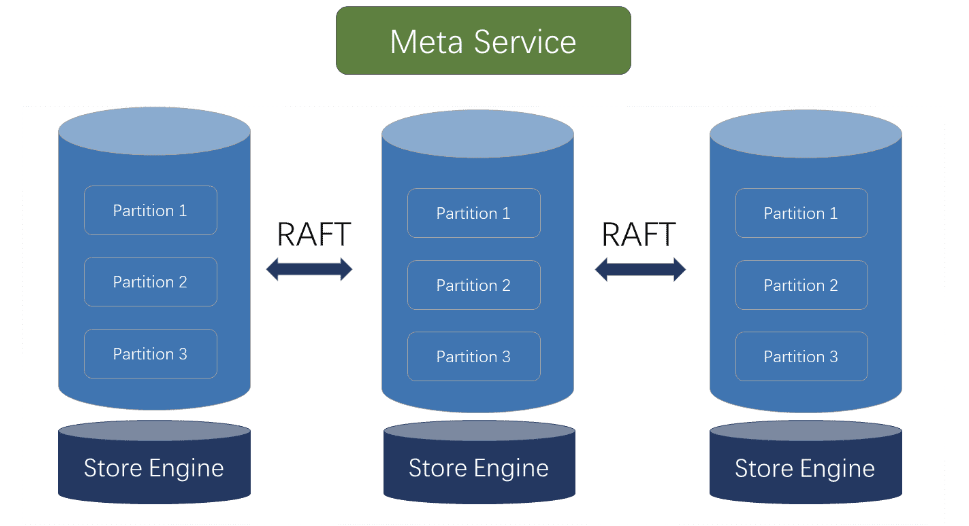
元数据服务层 Metaservice
Metaservice 对应的进程是 nebula-metad ,其主要的功能有:
- 用户管理:Nebula Graph 的用户体系包括
Goduser,Admin,User,Guest四种。每种用户的操作权限不一。 - 集群配置管理:支持上线、下线新的服务器。
- 图空间管理:增持增加、删除图空间,修改图空间配置(Raft副本数)
- Schema 管理:Nebula Graph 为强 schema 设计。
- 通过 Metaservice 记录 Tag 和 Edge 的属性的各字段的类型。支持的类型有:整型 int, 双精度类型 double, 时间数据类型 timestamp, 列表类型 list等;
- 多版本管理,支持增加、修改和删除 schema,并记录其版本号 - TTL 管理,通过标识到期回收 `time-to-live` 字段,支持数据的自动删除和空间回收
MetaService 层为有状态的服务,其状态持久化方法与 Storage 层一样通过 KVStore 方式存储。
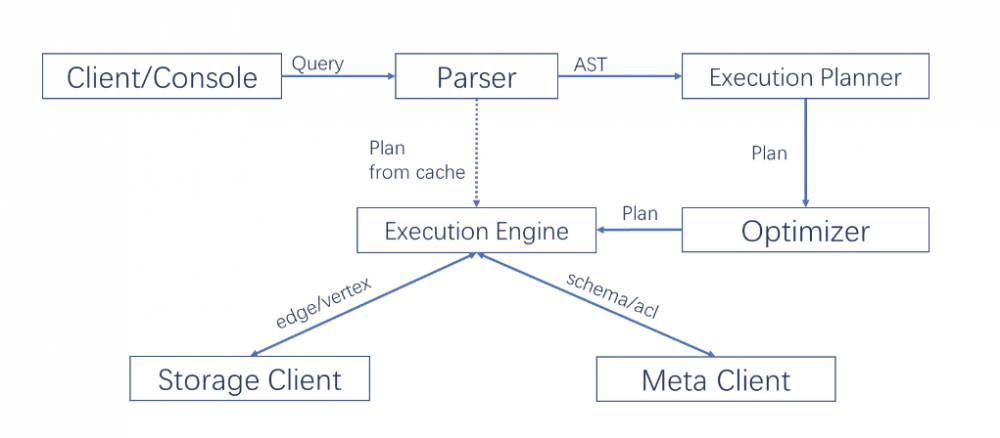
计算层 Query Engine & Query Language(nGQL)
计算层对应的进程是 nebula-graphd ,它由完全对等无状态无关联的计算节点组成,计算节点之间相互无通信。 Query Engine **层的主要功能,是解析客户端发送 nGQL 文本,通过词法解析 Lexer 和语法解析 Parser 生成执行计划,并通过优化后将执行计划交由执行引擎,执行引擎通过 MetaService 获取图点和边的 schema,并通过存储引擎层获取点和边的数据。 Query Engine** 层的主要优化有:
- 异步和并发执行:由于 IO 和网络均为长时延操作,需采用异步及并发操作。此外,为避免单个长 query 影响后续 query,Query Engine 为每个 query 设置单独的资源池以保证服务质量 QoS。
- 计算下沉:为避免存储层将过多数据回传到计算层占用宝贵的带宽,条件过滤
where等算子会随查询条件一同下发到存储层节点。 - 执行计划优化:虽然在关系数据库 SQL 中执行计划优化已经经历了长时间的发展,但业界对图查询语言的优化研究较少。Nebula Graph 对图查询的执行计划优化进行了一定的探索,包括 执行计划缓存 和 上下文无关语句并发执行 。
客户端 API & Console
Nebula Graph 提供 C++、Java、Golang 三种语言的客户端,与服务器之间的通信方式为 RPC,采用的通信协议为 Facebook-Thrift。用户也可通过 Linux 上 console 实现对 Nebula Graph 操作。Web 访问方式目前在开发过程中。
现场面基 Nebula Graph Meetup
来和 Nebula Graph 的程序员们一块面对面聊聊图数据库吗?「走近图数据库:Nebula Graph Meetup 第 3 期」将在本周六下午 14:00 在上海开始,参会传送门:: 戳这里
Nebula Graph:一个分布式,可扩展,快速的图形数据库,目前已开源。
GitHub: https://github.com/vesoft-inc/nebula
知乎: https://www.zhihu.com/org/nebulagraph/posts
微博: https://weibo.com/nebulagraph
正文到此结束
- 本文标签: GitHub list 删除 id 并发 java https sql value http IO 缓存 mysql git HBase API key src Service 存储引擎 linux 质量 安全 管理 parse schema Property 架构设计 db 集群 Facebook 解析 微博 文章 一致性 协议 进程 数据 程序员 Architect 模型 服务器 数据库 UI 空间 开源 数据模型 高并发 PHP tar 系统架构 时间 开发 ACE 分布式 tag web 配置
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

